# 20 | 模型部署:怎么发布训练好的机器学习模型?
你好,我是黄佳。欢迎来到零基础实战机器学习。
截止到现在,我们这个课程一直都是在本机上跑模型、分析和预测数据。但实际上,机器学习技术并不局限于离线应用,它也可以被部署到生产系统中发挥作用。
在具体部署时,出于对灵活性或者运行速度的需要,开发人员有可能会用Java、C或者C++等语言重写模型。当然,重写模型是非常耗时耗力的,也不一定总是要这样做。像Tensorflow、PyTorch、Sklearn这些机器学习框架都会提供相应的工具,把数据科学家调试成功的机器学习模型直接发布为Web服务,或是部署到移动设备中。
在这一讲中,我们会通过一个非常简单的示例,来看看怎么把我们之前做过的[预测微信文章浏览量](https://time.geekbang.org/column/article/414504)的机器学习模型嵌入到Web应用中,让模型从数据中学习,同时实时接收用户的输入,并返回预测结果。由于移动设备上的部署,还需要一些额外的步骤和工具,如Tensorflow Lite等,我这里不做展示,你有兴趣的话可以阅读[相关文档](https://www.tensorflow.org/lite/guide#3_run_inference_with_the_model)。
我先给你看看搞定后的页面:
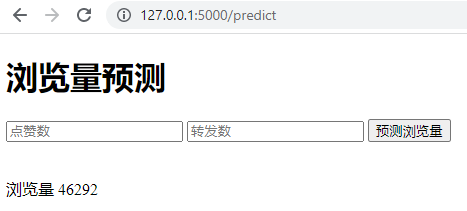
在进入具体的部署之前,我带你先整体了解一下,要搭建这个基于Web的机器学习应用,我们需要构建哪些模块。
## 整个项目需要构建哪些模块?
在这个项目中,我们实际上要构建的模块有三个:
* **机器学习模型**:我们会把机器学习模型序列化,生成二进制文件,通过载入这个文件,Web应用程序中就生成了可以调用的机器学习模型对象,我们可以根据Web端传入的点赞数、转发数,用模型来预测对应的浏览量。关于序列化,我们一会儿会详细讲到。
* **用Flask开发的Web应用**:它通过REST API,接收用户输入的点赞数和转发数信息,根据我们的模型计算预测值并返回它。Flask是一个使用Python编写的轻量级Web应用框架,简单易用,这里我们将用它来开发Web应用。
* **HTML页面模板**:允许用户输入点赞数和转发数信息并提交给Web服务器,当Web应用收到信息之后,就会调用机器学习模型,并在HTML页面中显示浏览量的预测值。
那么,这三个模块在整个Web应用中是如何协作的呢?我们来看看这张流程图:
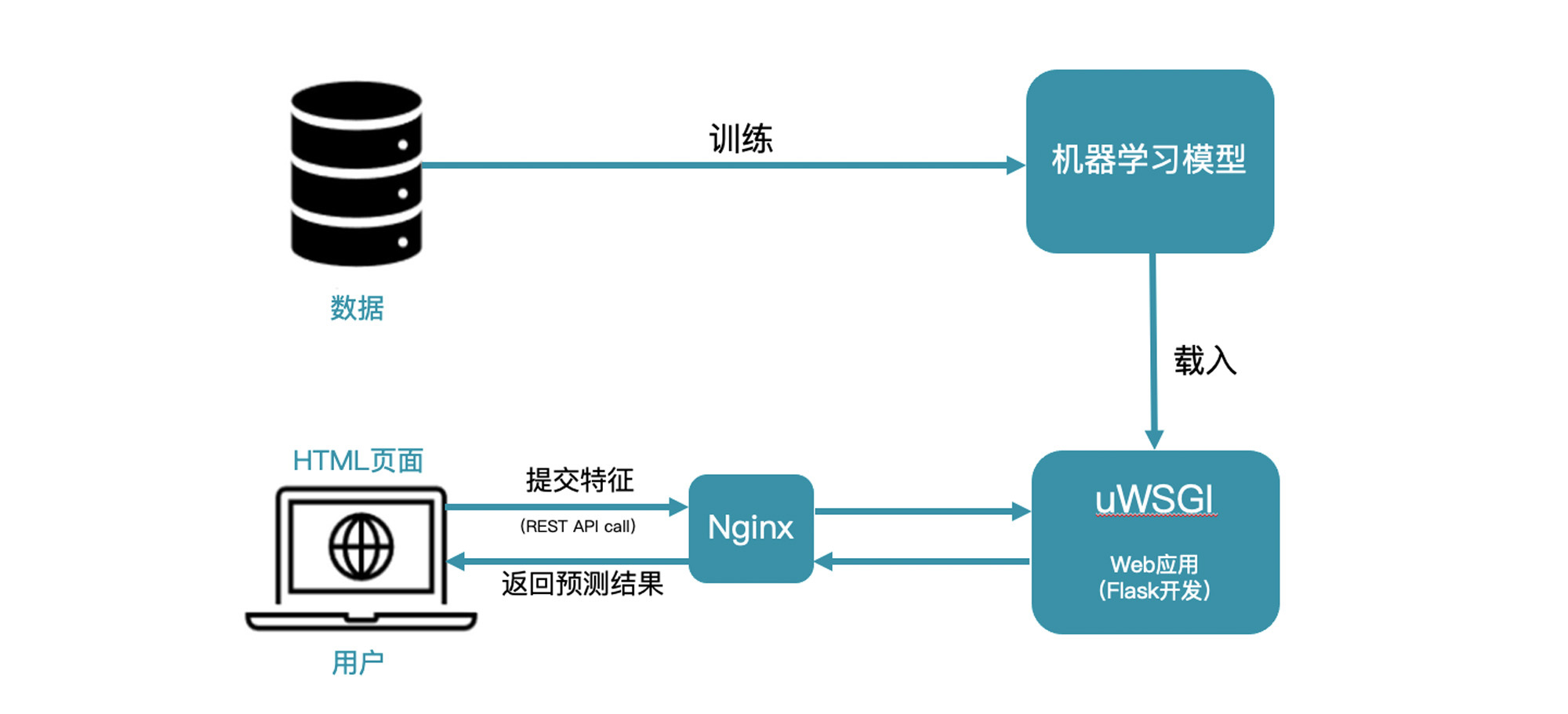
首先,用户通过HTML页面输入点赞数和转发数,并发送预测的REST API请求。代理服务器Nginx接收到请求后,将请求转发给后端服务器uWSGI。接着,后端服务器uWSGI会把请求继续转发给Web应用程序,这时候,Web应用程序会载入机器学习模型,并根据接收到的点赞数和转发数进行预测。预测出的结果再经由Web应用程序、后端服务器uWSGI、代理服务器Nginx,一路返回给HTML页面,呈现给用户。
你可能已经注意到,在图的上半部分,还有一个“数据导入机器学习模型做训练”的过程。这个过程其实只需要完成一次,就是在我们首次创建好模型的时候,用提前准备好的数据集训练模型。后续Web应用程序每次载入模型都不需要再调用数据集进行训练。
基于上面这个流程,我们再来看下这个项目的目录结构(你可以在[这里](https://github.com/huangjia2019/geektime/tree/main/%E8%BF%9B%E9%98%B6%E7%AF%8720)下载这些文件):
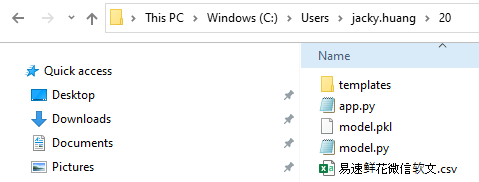
可以看到,在这个项目中,包含了5个文件(文件夹),分别是:
* **templates**:这个文件夹中存放着HTML文件**index.html**,这是给用户看的网页模板,也就是对应着用户能够浏览并输入信息的HTML页面;
* **app.py**:它就是Web API的开发源文件,负责部署机器学习模型;
* **model.py**:这是一个Python脚本文件,存放着我们创建、拟合机器学习模型的代码。Python脚本文件不是像Jupyter Notebook那样一个单元格,一个单元格交互地执行,而是在命令行整体执行。这个文件执行后会生成一个存储模型的二进制文件model.pkl,提供给Web API导入。
* **model.pkl**:就是刚才讲的model.py执行时生成的文件,用来存储模型。
* **易速鲜花微信软文.csv**:这就是我们用来训练模型的数据集。
下面我们就从最简单、最容易理解的HTML页面开始,一步步搭建来这个项目。
## 创建HTML模板
因为我们现在不再是从本机上跑机器学习模型,那么就需要有一个HTML页面,提供给用户通过网络来输入要预测的东西(也就是特征)。这也就是我们通常说的前端,这个不难理解。
HTML的语法也很简单,具体代码如下:
```
机器学习部署应用
浏览量预测
{{ prediction_text }}