375 lines
19 KiB
Markdown
375 lines
19 KiB
Markdown
|
|
# 23 | 情感分析:如何使用LSTM进行情感分析?
|
|||
|
|
|
|||
|
|
你好,我是方远。
|
|||
|
|
|
|||
|
|
欢迎来跟我一起学习情感分析,今天我们要讲的就是机器学习里的文本情感分析。文本情感分析又叫做观点提取、主题分析、倾向性分析等。光说概念,你可能会觉得有些抽象,我们一起来看一个生活中的应用,你一看就能明白了。
|
|||
|
|
|
|||
|
|
比方说我们在购物网站上选购一款商品时,首先会翻阅一下商品评价,看看是否有中差评。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。像这样根据评价文本,由计算机自动区分评价属于好评、中评或者说差评,背后用到的技术就是情感分析。
|
|||
|
|
|
|||
|
|
如果你进一步观察,还会发现,在好评差评的上方还有一些标签,比如“声音大小合适”、“连接速度快”、“售后态度很好”等。这些标签其实也是计算机根据文本,自动提取的主题或者观点。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
情感分析的快速发展得益于社交媒体的兴起,自2000年初以来,情感分析已经成长为自然语言处理(NLP)中最活跃的研究领域之一,它也被广泛应用在个性化推荐、商业决策、舆情监控等方面。
|
|||
|
|
|
|||
|
|
今天这节课,我们将完成一个情感分析项目,一起来对影评文本做分析。
|
|||
|
|
|
|||
|
|
## 数据准备
|
|||
|
|
|
|||
|
|
现在我们手中有一批影评数据(IMDB数据集),影评被分为两类:正面评价与负面评价。我们需要训练一个情感分析模型,对影评文本进行分类。
|
|||
|
|
|
|||
|
|
这个问题本质上还是一个文本分类问题,研究对象是电影评论类的文本,我们需要对文本进行二分类。下面我们来看一看训练数据。
|
|||
|
|
|
|||
|
|
IMDB(Internet Movie Database)是一个来自互联网电影数据库,其中包含了50000条严重两极分化的电影评论。数据集被划分为训练集和测试集,其中训练集和测试集中各有25000条评论,并且训练集和测试集都包含50%的正面评论和50%的消极评论。
|
|||
|
|
|
|||
|
|
### 如何用Torchtext读取数据集
|
|||
|
|
|
|||
|
|
我们可以利用Torchtext工具包来读取数据集。
|
|||
|
|
|
|||
|
|
Torchtext是一个包含**常用的文本处理工具**和**常见自然语言数据集**的工具包。我们可以类比之前学习过的Torchvision包来理解它,只不过,Torchvision包是用来处理图像的,而Torchtext则是用来处理文本的。
|
|||
|
|
|
|||
|
|
安装Torchtext同样很简单,我们可以使用pip进行安装,命令如下:
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
pip install torchtext
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
Torchtext中包含了上面我们要使用的IMDB数据集,并且还有读取语料库、词转词向量、词转下标、建立相应迭代器等功能,可以满足我们对文本的处理需求。
|
|||
|
|
|
|||
|
|
更为方便的是,Torchtext已经把一些常见对文本处理的数据集囊括在了`torchtext.datasets`中,与Torchvision类似,使用时会自动下载、解压并解析数据。
|
|||
|
|
|
|||
|
|
以IMDB为例,我们可以用后面的代码来读取数据集:
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# 读取IMDB数据集
|
|||
|
|
import torchtext
|
|||
|
|
train_iter = torchtext.datasets.IMDB(root='./data', split='train')
|
|||
|
|
next(train_iter)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
torchtext.datasets.IMDB函数有两个参数,其中:
|
|||
|
|
|
|||
|
|
* root:是一个字符串,用于指定你想要读取目标数据集的位置,如果数据集不存在,则会自动下载;
|
|||
|
|
* split:是一个字符串或者元组,表示返回的数据集类型,是训练集、测试集或验证集,默认是 (‘train’, ‘test’)。
|
|||
|
|
torchtext.datasets.IMDB函数的返回值是一个迭代器,这里我们读取了IMDB数据集中的训练集,共25000条数据,存入了变量train\_iter中。
|
|||
|
|
|
|||
|
|
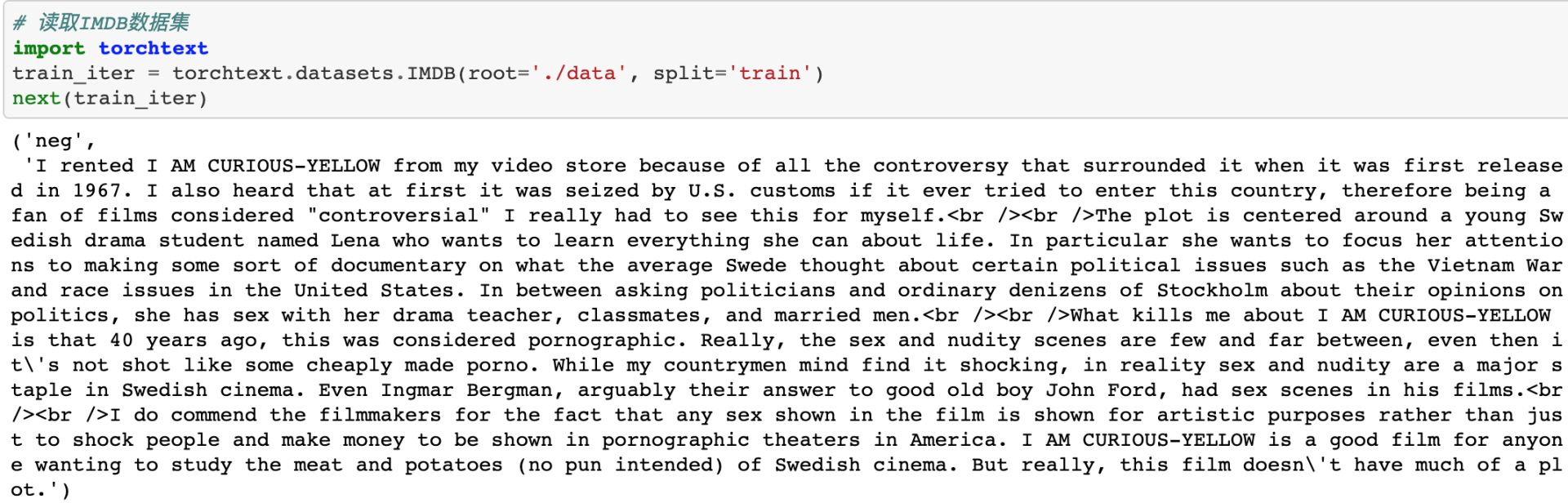
程序运行的结果如下图所示。我们可以看到,利用next()函数,读取出迭代器train\_iter中的一条数据,每一行是情绪分类以及后面的评论文本。“neg”表示负面评价,“pos”表示正面评价。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 数据处理pipelines
|
|||
|
|
|
|||
|
|
读取出了数据集中的评论文本和情绪分类,我们还需要将文本和分类标签处理成向量,才能被计算机读取。处理文本的一般过程是先分词,然后根据词汇表将词语转换为id。
|
|||
|
|
|
|||
|
|
Torchtext为我们提供了基本的文本处理工具,包括分词器“tokenizer”和词汇表“vocab”。我们可以用下面两个函数来创建分词器和词汇表。
|
|||
|
|
|
|||
|
|
get\_tokenizer函数的作用是创建一个分词器。将文本喂给相应的分词器,分词器就可以根据不同分词函数的规则完成分词。例如英文的分词器,就是简单按照空格和标点符号进行分词。
|
|||
|
|
|
|||
|
|
build\_vocab\_from\_iterator函数可以帮助我们使用训练数据集的迭代器构建词汇表,构建好词汇表后,输入分词后的结果,即可返回每个词语的id。
|
|||
|
|
|
|||
|
|
创建分词器和构建词汇表的代码如下。首先我们要建立一个可以处理英文的分词器tokenizer,然后再根据IMDB数据集的训练集迭代器train\_iter建立词汇表vocab。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# 创建分词器
|
|||
|
|
tokenizer = torchtext.data.utils.get_tokenizer('basic_english')
|
|||
|
|
print(tokenizer('here is the an example!'))
|
|||
|
|
'''
|
|||
|
|
输出:['here', 'is', 'the', 'an', 'example', '!']
|
|||
|
|
'''
|
|||
|
|
|
|||
|
|
# 构建词汇表
|
|||
|
|
def yield_tokens(data_iter):
|
|||
|
|
for _, text in data_iter:
|
|||
|
|
yield tokenizer(text)
|
|||
|
|
|
|||
|
|
vocab = torchtext.vocab.build_vocab_from_iterator(yield_tokens(train_iter), specials=["<pad>", "<unk>"])
|
|||
|
|
vocab.set_default_index(vocab["<unk>"])
|
|||
|
|
|
|||
|
|
print(vocab(tokenizer('here is the an example <pad> <pad>')))
|
|||
|
|
'''
|
|||
|
|
输出:[131, 9, 40, 464, 0, 0]
|
|||
|
|
'''
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在构建词汇表的过程中,yield\_tokens函数的作用就是依次将训练数据集中的每一条数据都进行分词处理。另外,在构建词汇表时,用户还可以利用specials参数自定义词表。
|
|||
|
|
|
|||
|
|
上述代码中我们自定义了两个词语:“<pad>”和“<unk>”,分别表示占位符和未登录词。顾名思义,未登录词是指没有被收录在分词词表中的词。由于每条影评文本的长度不同,不能直接批量合成矩阵,因此需通过截断或填补占位符来固定长度。
|
|||
|
|
|
|||
|
|
为了方便后续调用,我们使用分词器和词汇表来建立数据处理的pipelines。文本pipeline用于给定一段文本,返回分词后的id。标签pipeline用于将情绪分类转化为数字,即“neg”转化为0,“pos”转化为1。
|
|||
|
|
|
|||
|
|
具体代码如下所示。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# 数据处理pipelines
|
|||
|
|
text_pipeline = lambda x: vocab(tokenizer(x))
|
|||
|
|
label_pipeline = lambda x: 1 if x == 'pos' else 0
|
|||
|
|
|
|||
|
|
print(text_pipeline('here is the an example'))
|
|||
|
|
'''
|
|||
|
|
输出:[131, 9, 40, 464, 0, 0 , ... , 0]
|
|||
|
|
'''
|
|||
|
|
print(label_pipeline('neg'))
|
|||
|
|
'''
|
|||
|
|
输出:0
|
|||
|
|
'''
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
通过示例的输出结果,相信你很容易就能理解文本pipeline和标签pipeline的用法了。
|
|||
|
|
|
|||
|
|
### 生成训练数据
|
|||
|
|
|
|||
|
|
有了数据处理的pipelines,接下来就是生成训练数据,也就是生成DataLoader。
|
|||
|
|
|
|||
|
|
这里还涉及到一个变长数据处理的问题。我们在将文本pipeline所生成的id列表转化为模型能够识别的tensor时,由于文本的句子是变长的,因此生成的tensor长度不一,无法组成矩阵。
|
|||
|
|
|
|||
|
|
这时,我们需要限定一个句子的最大长度。例如句子的最大长度为256个单词,那么超过256个单词的句子需要做截断处理;不足256个单词的句子,需要统一补位,这里用“/”来填补。
|
|||
|
|
|
|||
|
|
上面所说的这些操作,我们都可以放到collate\_batch函数中来处理。
|
|||
|
|
|
|||
|
|
collate\_batch函数有什么用呢?它负责在DataLoad提取一个batch的样本时,完成一系列预处理工作:包括生成文本的tensor、生成标签的tensor、生成句子长度的tensor,以及上面所说的对文本进行截断、补位操作。所以,我们将collate\_batch函数通过参数collate\_fn传入DataLoader,即可实现对变长数据的处理。
|
|||
|
|
|
|||
|
|
collate\_batch函数的定义,以及生成训练与验证DataLoader的代码如下。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# 生成训练数据
|
|||
|
|
import torch
|
|||
|
|
import torchtext
|
|||
|
|
from torch.utils.data import DataLoader
|
|||
|
|
from torch.utils.data.dataset import random_split
|
|||
|
|
from torchtext.data.functional import to_map_style_dataset
|
|||
|
|
|
|||
|
|
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
|||
|
|
|
|||
|
|
def collate_batch(batch):
|
|||
|
|
max_length = 256
|
|||
|
|
pad = text_pipeline('<pad>')
|
|||
|
|
label_list, text_list, length_list = [], [], []
|
|||
|
|
for (_label, _text) in batch:
|
|||
|
|
label_list.append(label_pipeline(_label))
|
|||
|
|
processed_text = text_pipeline(_text)[:max_length]
|
|||
|
|
length_list.append(len(processed_text))
|
|||
|
|
text_list.append((processed_text+pad*max_length)[:max_length])
|
|||
|
|
label_list = torch.tensor(label_list, dtype=torch.int64)
|
|||
|
|
text_list = torch.tensor(text_list, dtype=torch.int64)
|
|||
|
|
length_list = torch.tensor(length_list, dtype=torch.int64)
|
|||
|
|
return label_list.to(device), text_list.to(device), length_list.to(device)
|
|||
|
|
|
|||
|
|
train_iter = torchtext.datasets.IMDB(root='./data', split='train')
|
|||
|
|
train_dataset = to_map_style_dataset(train_iter)
|
|||
|
|
num_train = int(len(train_dataset) * 0.95)
|
|||
|
|
split_train_, split_valid_ = random_split(train_dataset,
|
|||
|
|
[num_train, len(train_dataset) - num_train])
|
|||
|
|
train_dataloader = DataLoader(split_train_, batch_size=8, shuffle=True, collate_fn=collate_batch)
|
|||
|
|
valid_dataloader = DataLoader(split_valid_, batch_size=8, shuffle=False, collate_fn=collate_batch)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们一起梳理一下这段代码的流程,一共是五个步骤。
|
|||
|
|
|
|||
|
|
1.利用torchtext读取IMDB的训练数据集,得到训练数据迭代器;
|
|||
|
|
2.使用to\_map\_style\_dataset函数将迭代器转化为Dataset类型;
|
|||
|
|
3.使用random\_split函数对Dataset进行划分,其中95%作为训练集,5%作为验证集;
|
|||
|
|
4.生成训练集的DataLoader;
|
|||
|
|
5.生成验证集的DataLoader。
|
|||
|
|
|
|||
|
|
到此为止,数据部分已经全部准备完毕了,接下来我们来进行网络模型的构建。
|
|||
|
|
|
|||
|
|
## 模型构建
|
|||
|
|
|
|||
|
|
之前我们已经学过卷积神经网络的相关知识。卷积神经网络使用固定的大小矩阵作为输入(例如一张图片),然后输出一个固定大小的向量(例如不同类别的概率),因此适用于图像分类、目标检测、图像分割等等。
|
|||
|
|
|
|||
|
|
但是除了图像之外,还有很多信息,其大小或长度并不是固定的,例如音频、视频、文本等。我们想要处理这些序列相关的数据,就要用到时序模型。比如我们今天要处理的文本数据,这就涉及一种常见的时间序列模型:循环神经网络(Recurrent Neural Network,RNN)。
|
|||
|
|
|
|||
|
|
不过由于RNN自身的结构问题,在进行反向传播时,容易出现梯度消失或梯度爆炸。**LSTM网络**在RNN结构的基础上进行了改进,通过精妙的门控制将短时记忆与长时记忆结合起来,**一定程度上解决了梯度消失与梯度爆炸的问题**。
|
|||
|
|
|
|||
|
|
我们使用LSTM网络来进行情绪分类的预测。模型的定义如下。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# 定义模型
|
|||
|
|
class LSTM(torch.nn.Module):
|
|||
|
|
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional,
|
|||
|
|
dropout_rate, pad_index=0):
|
|||
|
|
super().__init__()
|
|||
|
|
self.embedding = torch.nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_index)
|
|||
|
|
self.lstm = torch.nn.LSTM(embedding_dim, hidden_dim, n_layers, bidirectional=bidirectional,
|
|||
|
|
dropout=dropout_rate, batch_first=True)
|
|||
|
|
self.fc = torch.nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
|
|||
|
|
self.dropout = torch.nn.Dropout(dropout_rate)
|
|||
|
|
|
|||
|
|
def forward(self, ids, length):
|
|||
|
|
embedded = self.dropout(self.embedding(ids))
|
|||
|
|
packed_embedded = torch.nn.utils.rnn.pack_padded_sequence(embedded, length, batch_first=True,
|
|||
|
|
enforce_sorted=False)
|
|||
|
|
packed_output, (hidden, cell) = self.lstm(packed_embedded)
|
|||
|
|
output, output_length = torch.nn.utils.rnn.pad_packed_sequence(packed_output)
|
|||
|
|
if self.lstm.bidirectional:
|
|||
|
|
hidden = self.dropout(torch.cat([hidden[-1], hidden[-2]], dim=-1))
|
|||
|
|
else:
|
|||
|
|
hidden = self.dropout(hidden[-1])
|
|||
|
|
prediction = self.fc(hidden)
|
|||
|
|
return prediction
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
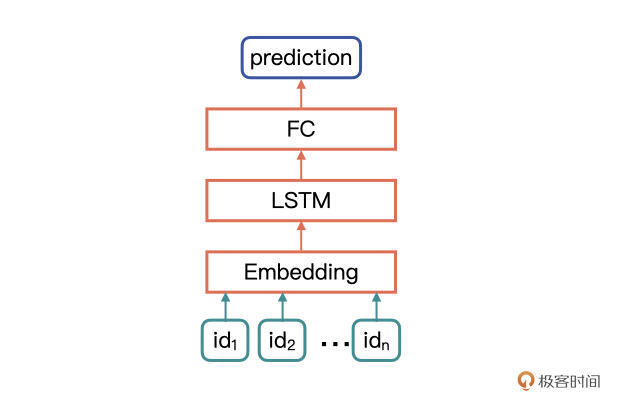
网络模型的具体结构,首先是一个Embedding层,用来接收文本id的tensor,然后是LSTM层,最后是一个全连接分类层。其中,bidirectional为True,表示网络为双向LSTM,bidirectional为False,表示网络为单向LSTM。
|
|||
|
|
|
|||
|
|
网络模型的结构图如下所示。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
## 模型训练与评估
|
|||
|
|
|
|||
|
|
定义好网络模型的结构,我们就可以进行模型训练了。首先是实例化网络模型,参数以及具体的代码如下。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# 实例化模型
|
|||
|
|
vocab_size = len(vocab)
|
|||
|
|
embedding_dim = 300
|
|||
|
|
hidden_dim = 300
|
|||
|
|
output_dim = 2
|
|||
|
|
n_layers = 2
|
|||
|
|
bidirectional = True
|
|||
|
|
dropout_rate = 0.5
|
|||
|
|
|
|||
|
|
model = LSTM(vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout_rate)
|
|||
|
|
model = model.to(device)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
由于数据的情感极性共分为两类,因此这里我们要把output\_dim的值设置为2。
|
|||
|
|
接下来是定义损失函数与优化方法,代码如下。在之前的课程里也多次讲过了,所以这里不再重复。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# 损失函数与优化方法
|
|||
|
|
lr = 5e-4
|
|||
|
|
criterion = torch.nn.CrossEntropyLoss()
|
|||
|
|
criterion = criterion.to(device)
|
|||
|
|
|
|||
|
|
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
计算loss的代码如下。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
import tqdm
|
|||
|
|
import sys
|
|||
|
|
import numpy as np
|
|||
|
|
|
|||
|
|
def train(dataloader, model, criterion, optimizer, device):
|
|||
|
|
model.train()
|
|||
|
|
epoch_losses = []
|
|||
|
|
epoch_accs = []
|
|||
|
|
for batch in tqdm.tqdm(dataloader, desc='training...', file=sys.stdout):
|
|||
|
|
(label, ids, length) = batch
|
|||
|
|
label = label.to(device)
|
|||
|
|
ids = ids.to(device)
|
|||
|
|
length = length.to(device)
|
|||
|
|
prediction = model(ids, length)
|
|||
|
|
loss = criterion(prediction, label) # loss计算
|
|||
|
|
accuracy = get_accuracy(prediction, label)
|
|||
|
|
# 梯度更新
|
|||
|
|
optimizer.zero_grad()
|
|||
|
|
loss.backward()
|
|||
|
|
optimizer.step()
|
|||
|
|
epoch_losses.append(loss.item())
|
|||
|
|
epoch_accs.append(accuracy.item())
|
|||
|
|
return epoch_losses, epoch_accs
|
|||
|
|
|
|||
|
|
def evaluate(dataloader, model, criterion, device):
|
|||
|
|
model.eval()
|
|||
|
|
epoch_losses = []
|
|||
|
|
epoch_accs = []
|
|||
|
|
with torch.no_grad():
|
|||
|
|
for batch in tqdm.tqdm(dataloader, desc='evaluating...', file=sys.stdout):
|
|||
|
|
(label, ids, length) = batch
|
|||
|
|
label = label.to(device)
|
|||
|
|
ids = ids.to(device)
|
|||
|
|
length = length.to(device)
|
|||
|
|
prediction = model(ids, length)
|
|||
|
|
loss = criterion(prediction, label) # loss计算
|
|||
|
|
accuracy = get_accuracy(prediction, label)
|
|||
|
|
epoch_losses.append(loss.item())
|
|||
|
|
epoch_accs.append(accuracy.item())
|
|||
|
|
return epoch_losses, epoch_accs
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
可以看到,这里训练过程与验证过程的loss计算,分别定义在了train函数和evaluate函数中。主要区别是训练过程有梯度的更新,而验证过程中不涉及梯度的更新,只计算loss即可。
|
|||
|
|
模型的评估我们使用ACC,也就是准确率作为评估指标,计算ACC的代码如下。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def get_accuracy(prediction, label):
|
|||
|
|
batch_size, _ = prediction.shape
|
|||
|
|
predicted_classes = prediction.argmax(dim=-1)
|
|||
|
|
correct_predictions = predicted_classes.eq(label).sum()
|
|||
|
|
accuracy = correct_predictions / batch_size
|
|||
|
|
return accuracy
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
最后,训练过程的具体代码如下。包括计算loss和ACC、保存losses列表和保存最优模型。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
n_epochs = 10
|
|||
|
|
best_valid_loss = float('inf')
|
|||
|
|
|
|||
|
|
train_losses = []
|
|||
|
|
train_accs = []
|
|||
|
|
valid_losses = []
|
|||
|
|
valid_accs = []
|
|||
|
|
|
|||
|
|
for epoch in range(n_epochs):
|
|||
|
|
train_loss, train_acc = train(train_dataloader, model, criterion, optimizer, device)
|
|||
|
|
valid_loss, valid_acc = evaluate(valid_dataloader, model, criterion, device)
|
|||
|
|
train_losses.extend(train_loss)
|
|||
|
|
train_accs.extend(train_acc)
|
|||
|
|
valid_losses.extend(valid_loss)
|
|||
|
|
valid_accs.extend(valid_acc)
|
|||
|
|
epoch_train_loss = np.mean(train_loss)
|
|||
|
|
epoch_train_acc = np.mean(train_acc)
|
|||
|
|
epoch_valid_loss = np.mean(valid_loss)
|
|||
|
|
epoch_valid_acc = np.mean(valid_acc)
|
|||
|
|
if epoch_valid_loss < best_valid_loss:
|
|||
|
|
best_valid_loss = epoch_valid_loss
|
|||
|
|
torch.save(model.state_dict(), 'lstm.pt')
|
|||
|
|
print(f'epoch: {epoch+1}')
|
|||
|
|
print(f'train_loss: {epoch_train_loss:.3f}, train_acc: {epoch_train_acc:.3f}')
|
|||
|
|
print(f'valid_loss: {epoch_valid_loss:.3f}, valid_acc: {epoch_valid_acc:.3f}')
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们还可以利用保存下来train\_losses列表,绘制训练过程中的loss曲线,或使用[第15课](https://time.geekbang.org/column/article/444252)讲过的可视化工具来监控训练过程。
|
|||
|
|
至此,一个完整的情感分析项目已经完成了。从数据读取到模型构建与训练的方方面面,我都手把手教给了你,希望你能以此为模板,独立解决自己的问题。
|
|||
|
|
|
|||
|
|
## 小结
|
|||
|
|
|
|||
|
|
恭喜你,完成了今天的学习任务。今天我们一起完成了一个情感分析项目的实践,相当于是对自然语言处理任务的一个初探。我带你回顾一下今天学习的要点。
|
|||
|
|
|
|||
|
|
在数据准备阶段,我们可以使用PyTorch提供的文本处理工具包Torchtext。想要掌握Torchtext也不难,我们可以类比之前详细介绍过的Torchvision,不懂的地方再对应去[查阅文档](https://pytorch.org/text/stable/index.html),相信你一定可以做到举一反三。
|
|||
|
|
|
|||
|
|
**模型构建时,要根据具体的问题选择适合的神经网络。卷积神经网络常被用于处理图像作为输入的预测问题;循环神经网络常被用于处理变长的、序列相关的数据。而LSTM相较于RNN,能更好地解决梯度消失与梯度爆炸的问题**。
|
|||
|
|
|
|||
|
|
在后续的课程中,我们还会讲解两大自然语言处理任务:文本分类和摘要生成,它们分别包括了判别模型和生成模型,相信那时你一定会在文本处理方面有更深层次的理解。
|
|||
|
|
|
|||
|
|
## 每课一练
|
|||
|
|
|
|||
|
|
利用今天训练的模型,编写一个函数predict\_sentiment,实现输入一句话,输出这句话的情绪类别与概率。
|
|||
|
|
|
|||
|
|
例如:
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
text = "This film is terrible!"
|
|||
|
|
predict_sentiment(text, model, tokenizer, vocab, device)
|
|||
|
|
'''
|
|||
|
|
输出:('neg', 0.8874172568321228)
|
|||
|
|
'''
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
欢迎你在留言区跟我交流互动,也推荐你把今天学到的内容分享给更多朋友,跟他一起学习进步。
|
|||
|
|
|