|
|
|
|
|
# 15 | OpenResty 和别的开发平台有什么不同?
|
|
|
|
|
|
|
|
|
|
|
|
你好,我是温铭。
|
|
|
|
|
|
|
|
|
|
|
|
上一模块中, 你已经学习了 OpenResty 的两个基石:NGINX 和 LuaJIT,相信你已经摩拳擦掌,准备开始学习 OpenResty 提供的 API 了吧?
|
|
|
|
|
|
|
|
|
|
|
|
不过,别着急,在这之前,你还需要再花一点儿时间,来熟悉下 OpenResty 的原理和基本概念。
|
|
|
|
|
|
|
|
|
|
|
|
## 原理
|
|
|
|
|
|
|
|
|
|
|
|
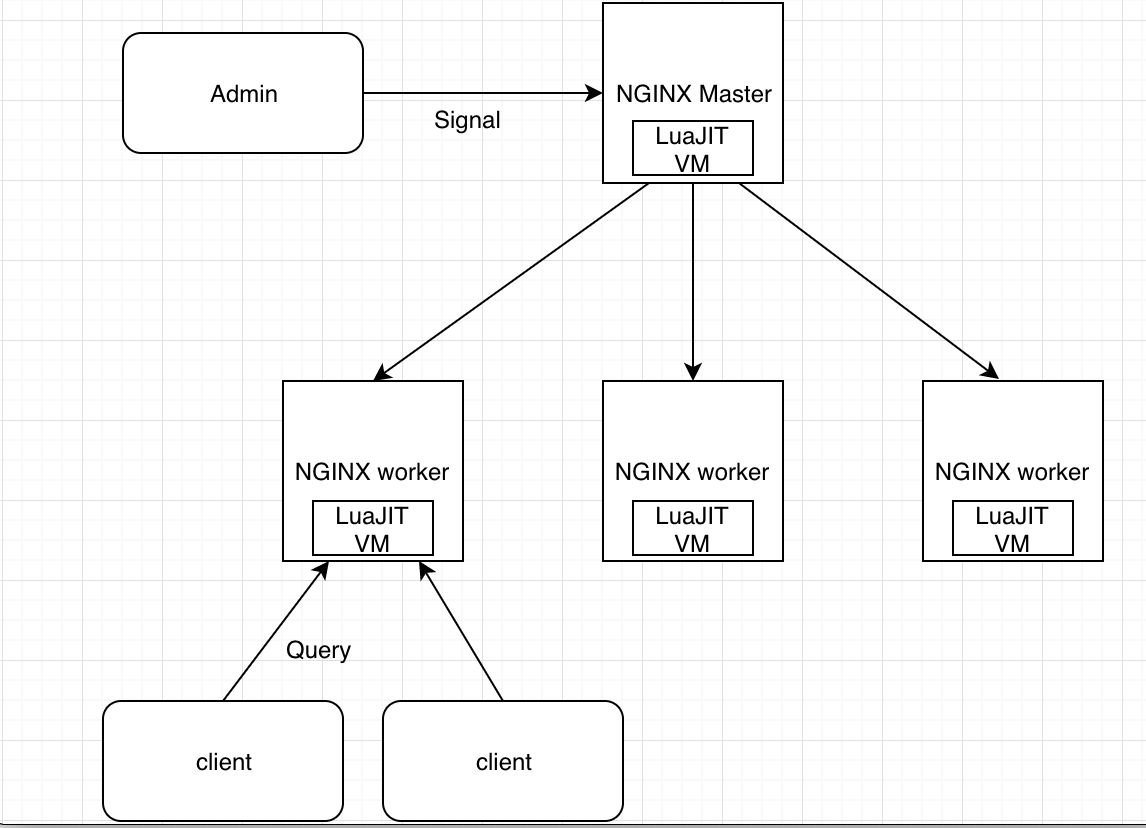
在前面的 LuaJIT 内容中,你已经见过下面这个架构图:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这里我再详细解释一下。
|
|
|
|
|
|
|
|
|
|
|
|
OpenResty 的 master 和 worker 进程中,都包含一个 LuaJIT VM。在同一个进程内的所有协程,都会共享这个 VM,并在这个 VM 中运行 Lua 代码。
|
|
|
|
|
|
|
|
|
|
|
|
而在同一个时间点上,每个 worker 进程只能处理一个用户的请求,也就是只有一个协程在运行。看到这里,你可能会有一个疑问:NGINX 既然能够支持 C10K (上万并发),不是需要同时处理一万个请求吗?
|
|
|
|
|
|
|
|
|
|
|
|
当然不是,NGINX 实际上是通过 epoll 的事件驱动,来减少等待和空转,才尽可能地让 CPU 资源都用于处理用户的请求。毕竟,只有单个的请求被足够快地处理完,整体才能达到高性能的目的。如果采用的是多线程模式,让一个请求对应一个线程,那么在 C10K 的情况下,资源很容易就会被耗尽的。
|
|
|
|
|
|
|
|
|
|
|
|
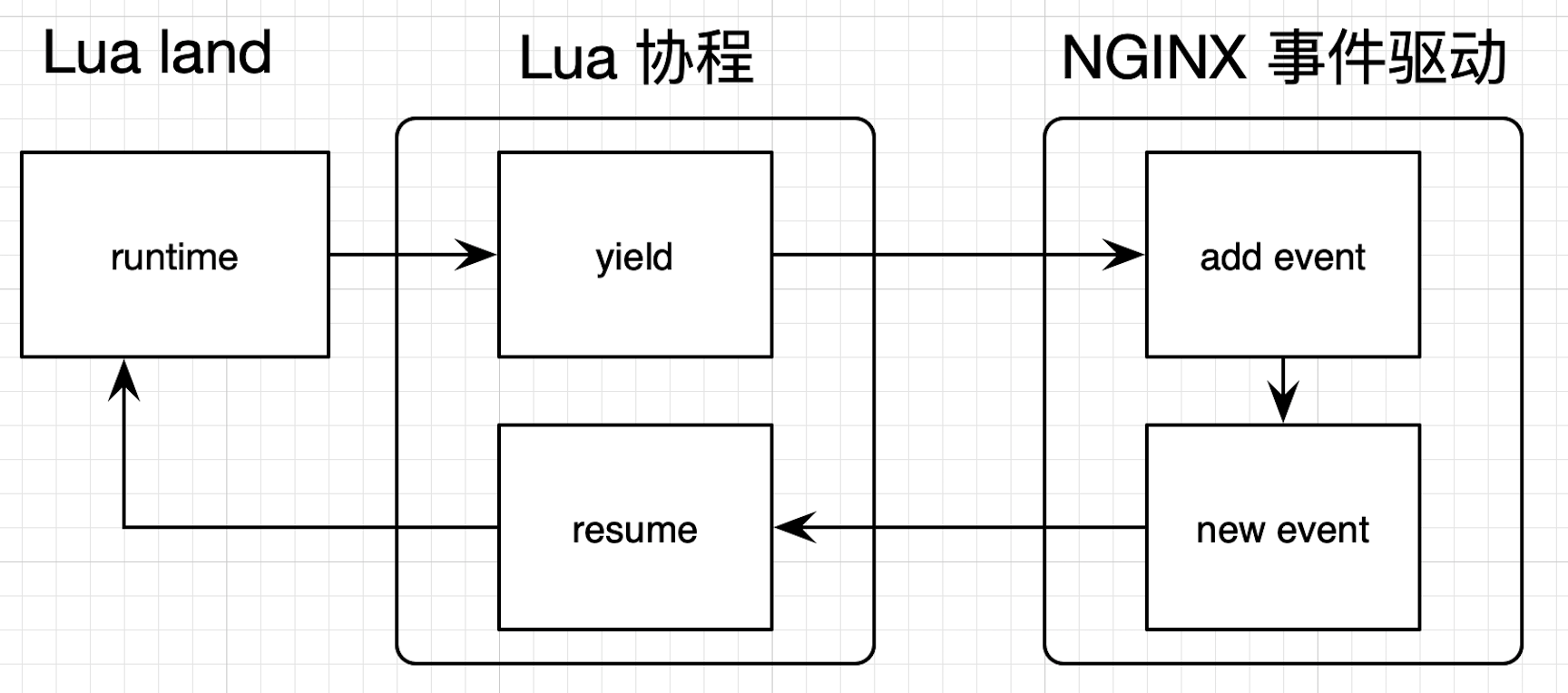
在 OpenResty 层面,Lua 的协程会与 NGINX 的事件机制相互配合。如果 Lua 代码中出现类似查询 MySQL 数据库这样的 I/O 操作,就会先调用 Lua 协程的 yield 把自己挂起,然后在 NGINX 中注册回调;在 I/O 操作完成(也可能是超时或者出错)后,再由 NGINX 回调 resume 来唤醒 Lua 协程。这样就完成了 Lua 协程和 NGINX 事件驱动的配合,避免在 Lua 代码中写回调。
|
|
|
|
|
|
|
|
|
|
|
|
我们可以来看下面这张图,描述了这整个流程。其中,`lua_yield` 和 `lua_resume` 都属于 Lua 提供的 `lua_CFunction`。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
另外一个方面,如果 Lua 代码中没有 I/O 或者 sleep 操作,比如全是密集的加解密运算,那么 Lua 协程就会一直占用 LuaJIT VM,直到处理完整个请求。
|
|
|
|
|
|
|
|
|
|
|
|
下面我提供了 `ngx.sleep` 的一段源码,可以帮你更清晰理解这一点。 这段代码位于 `ngx_http_lua_sleep.c` 中,你可以在 `lua-nginx-module` 项目的 [src 目录](https://github.com/openresty/lua-nginx-module/tree/master/src)中找到它。
|
|
|
|
|
|
|
|
|
|
|
|
在`ngx_http_lua_sleep.c` 中,我们可以看到 sleep 函数的具体实现。你需要先通过 C 函数 `ngx_http_lua_ngx_sleep`,来注册 `ngx.sleep` 这个 Lua API:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
void
|
|
|
|
|
|
ngx_http_lua_inject_sleep_api(lua_State *L)
|
|
|
|
|
|
{
|
|
|
|
|
|
lua_pushcfunction(L, ngx_http_lua_ngx_sleep);
|
|
|
|
|
|
lua_setfield(L, -2, "sleep");
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
下面便是 sleep 的主函数,这里我只摘取了几行主要的代码:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int ngx_http_lua_ngx_sleep(lua_State *L)
|
|
|
|
|
|
{
|
|
|
|
|
|
coctx->sleep.handler = ngx_http_lua_sleep_handler;
|
|
|
|
|
|
ngx_add_timer(&coctx->sleep, (ngx_msec_t) delay);
|
|
|
|
|
|
return lua_yield(L, 0);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
你可以看到:
|
|
|
|
|
|
|
|
|
|
|
|
* 这里先增加了 `ngx_http_lua_sleep_handler` 这个回调函数;
|
|
|
|
|
|
* 然后调用 `ngx_add_timer` 这个 NGINX 提供的接口,向 NGINX 的事件循环中增加一个定时器;
|
|
|
|
|
|
* 最后使用 `lua_yield` 把 Lua 协程挂起,把控制权交给 NGINX 的事件循环。
|
|
|
|
|
|
|
|
|
|
|
|
当 sleep 操作完成后, `ngx_http_lua_sleep_handler` 这个回调函数就被触发了。它里面调用了 `ngx_http_lua_sleep_resume`, 并最终使用 `lua_resume` 唤醒了 Lua 协程。更具体的调用过程,你可以自己去代码里面检索,这里我就不展开描述了。
|
|
|
|
|
|
|
|
|
|
|
|
`ngx.sleep` 只是最简单的一个示例,不过通过对它的剖析,你可以看出 `lua-nginx-module` 模块的基本原理。
|
|
|
|
|
|
|
|
|
|
|
|
## 基本概念
|
|
|
|
|
|
|
|
|
|
|
|
分析完原理之后,让我们一起温故而知新,回忆下 OpenResty 中**阶段**和**非阻塞**这两个重要的概念。
|
|
|
|
|
|
|
|
|
|
|
|
OpenResty 和 NGINX 一样,都有阶段的概念,并且每个阶段都有自己不同的作用:
|
|
|
|
|
|
|
|
|
|
|
|
* `set_by_lua`,用于设置变量;
|
|
|
|
|
|
* `rewrite_by_lua`,用于转发、重定向等;
|
|
|
|
|
|
* `access_by_lua`,用于准入、权限等;
|
|
|
|
|
|
* `content_by_lua`,用于生成返回内容;
|
|
|
|
|
|
* `header_filter_by_lua`,用于应答头过滤处理;
|
|
|
|
|
|
* `body_filter_by_lua`,用于应答体过滤处理;
|
|
|
|
|
|
* `log_by_lua`,用于日志记录。
|
|
|
|
|
|
|
|
|
|
|
|
当然,如果你的代码逻辑并不复杂,都放在 rewrite 或者 content 阶段执行,也是可以的。
|
|
|
|
|
|
|
|
|
|
|
|
不过需要注意,OpenResty 的 API 是有阶段使用限制的。每一个 API 都有一个与之对应的使用阶段列表,如果你超范围使用就会报错。这与其他的开发语言有很大的不同。
|
|
|
|
|
|
|
|
|
|
|
|
举个例子,这里我还是以 `ngx.sleep` 为例。通过查阅文档,我知道它只能用于下面列出的上下文中,并不包括 log 阶段:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
context: rewrite_by_lua*, access_by_lua*, content_by_lua*, ngx.timer.*, ssl_certificate_by_lua*, ssl_session_fetch_by_lua*_
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
而如果你不知道这一点,在它不支持的 log 阶段使用 sleep 的话:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
location / {
|
|
|
|
|
|
log_by_lua_block {
|
|
|
|
|
|
ngx.sleep(1)
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在 NGINX 的错误日志中,就会出现 error 级别的提示:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
[error] 62666#0: *6 failed to run log_by_lua*: log_by_lua(nginx.conf:14):2: API disabled in the context of log_by_lua*
|
|
|
|
|
|
stack traceback:
|
|
|
|
|
|
[C]: in function 'sleep'
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
所以,在你使用 API 之前,一定记得要先查阅文档,确定其能否在代码的上下文中使用。
|
|
|
|
|
|
|
|
|
|
|
|
复习了阶段的概念后,我们再来回顾下非阻塞。首先明确一点,由 OpenResty 提供的所有 API,都是非阻塞的。
|
|
|
|
|
|
|
|
|
|
|
|
我继续以 sleep 1 秒这个需求为例来说明。如果你要在 Lua 中实现它,你需要这样做:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
function sleep(s)
|
|
|
|
|
|
local ntime = os.time() + s
|
|
|
|
|
|
repeat until os.time() > ntime
|
|
|
|
|
|
end
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
因为标准 Lua 没有直接的 sleep 函数,所以这里我用一个循环,来不停地判断是否达到指定的时间。这个实现就是阻塞的,在 sleep 的这一秒钟时间内,Lua 正在做无用功,而其他需要处理的请求,只能在一边傻傻地等待。
|
|
|
|
|
|
|
|
|
|
|
|
不过,要是换成 `ngx.sleep(1)` 来实现的话,根据上面我们分析过的源码,在这一秒钟的时间内,OpenResty 依然可以去处理其他请求(比如 B 请求),当前请求(我们叫它 A 请求)的上下文会被保存起来,并由 NGINX 的事件机制来唤醒,再回到 A 请求,这样 CPU 就一直处于真正的工作状态。
|
|
|
|
|
|
|
|
|
|
|
|
## 变量和生命周期
|
|
|
|
|
|
|
|
|
|
|
|
除了这两个重要概念外,**变量的生命周期**,也是 OpenResty 开发中容易出错的地方。
|
|
|
|
|
|
|
|
|
|
|
|
前面说过,在 OpenResty 中,我推荐你把所有变量都声明为局部变量,并用 luacheck 和 lua-releng 这样的工具来检测全局变量。这其实对于模块来说也是一样的,比如下面这样的写法:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
local ngx_re = require "ngx.re"
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
其实,在 OpenResty 中,除了 `init_by_lua` 和 `init_worker_by_lua` 这两个阶段外,其余阶段都会设置一个隔离的全局变量表,以免在处理过程中污染了其他请求。即使在这两个可以定义全局变量的阶段,你也应该尽量避免去定义全局变量。
|
|
|
|
|
|
|
|
|
|
|
|
通常来说,试图用全局变量来解决的问题,其实更应该用模块的变量来解决,而且还会更加清晰。下面是一个模块中变量的示例:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
local _M = {}
|
|
|
|
|
|
|
|
|
|
|
|
_M.color = {
|
|
|
|
|
|
red = 1,
|
|
|
|
|
|
blue = 2,
|
|
|
|
|
|
green = 3
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
return _M
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
我在一个名为 hello.lua 的文件中定义了一个模块,模块包含了 color 这个 table。然后,我又在 nginx.conf 中增加了对应的配置:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
location / {
|
|
|
|
|
|
content_by_lua_block {
|
|
|
|
|
|
local hello = require "hello"
|
|
|
|
|
|
ngx.say(hello.color.green)
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这段配置会在 content 阶段中 require 这个模块,并把 green 的值作为 http 请求返回体打印出来。
|
|
|
|
|
|
|
|
|
|
|
|
你可能会好奇,模块变量为什么这么神奇呢?
|
|
|
|
|
|
|
|
|
|
|
|
实际上,在同一 worker 进程中,模块只会被加载一次;之后这个 worker 处理的所有请求,就可以共享模块中的数据了。我们说“全局”的数据很适合封装在模块内,是因为 OpenResty 的 worker 之间完全隔离,所以每个 worker 都会独立地对模块进行加载,而模块的数据也不能跨越 worker。
|
|
|
|
|
|
|
|
|
|
|
|
至于应该如何处理 worker 之间需要共享的数据,我会留到后面的章节来讲解,这里你先不必深究。
|
|
|
|
|
|
|
|
|
|
|
|
不过,这里也有一个很容易出错的地方,那就是**访问模块变量的时候,你最好保持只读,而不要尝试去修改,不然在高并发的情况下会出现 race**。这种 bug 依靠单元测试是无法发现的,它在线上偶尔会出现,并且很难定位。
|
|
|
|
|
|
|
|
|
|
|
|
举个例子,模块变量 green 当前的值是 3,而你在代码中做了加 1 的操作,那么现在 green 的值是 4 吗?不一定,它可能是 4,也可能是 5 或者是 6。因为在对模块变量进行写操作的时候,OpenResty 并不会加锁,这时就会产生竞争,模块变量的值就会被多个请求同时更新。
|
|
|
|
|
|
|
|
|
|
|
|
说完了全局变量、局部变量和模块变量,最后我们再来讲讲跨阶段的变量。
|
|
|
|
|
|
|
|
|
|
|
|
有些情况下,我们需要的是跨越阶段的、可以读写的变量。而像我们熟悉的 NGINX 中 `$host`、`$scheme` 等变量,虽然满足跨越阶段的条件,但却无法做到动态创建,你必须先在配置文件中定义才能使用它们。比如下面这样的写法:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
location /foo {
|
|
|
|
|
|
set $my_var ; # 需要先创建 $my_var 变量
|
|
|
|
|
|
content_by_lua_block {
|
|
|
|
|
|
ngx.var.my_var = 123
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
OpenResty 提供了 `ngx.ctx`,来解决这类问题。它是一个 Lua table,可以用来存储基于请求的 Lua 数据,且生存周期与当前请求相同。我们来看下官方文档中的这个示例:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
location /test {
|
|
|
|
|
|
rewrite_by_lua_block {
|
|
|
|
|
|
ngx.ctx.foo = 76
|
|
|
|
|
|
}
|
|
|
|
|
|
access_by_lua_block {
|
|
|
|
|
|
ngx.ctx.foo = ngx.ctx.foo + 3
|
|
|
|
|
|
}
|
|
|
|
|
|
content_by_lua_block {
|
|
|
|
|
|
ngx.say(ngx.ctx.foo)
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
你可以看到,我们定义了一个变量 `foo`,存放在 `ngx.ctx` 中。这个变量跨越了 rewrite、access 和 content 三个阶段,最终在 content 阶段打印出了值,并且是我们预期的 79。
|
|
|
|
|
|
|
|
|
|
|
|
当然,`ngx.ctx` 也有自己的局限性:
|
|
|
|
|
|
|
|
|
|
|
|
* 比如说,使用 `ngx.location.capture` 创建的子请求,会有自己独立的 `ngx.ctx` 数据,和父请求的 `ngx.ctx` 互不影响;
|
|
|
|
|
|
* 再如,使用 `ngx.exec` 创建的内部重定向,会销毁原始请求的 `ngx.ctx`,重新生成空白的 `ngx.ctx`。
|
|
|
|
|
|
|
|
|
|
|
|
这两个局限,在官方文档中都有详细的[代码示例](https://github.com/openresty/lua-nginx-module#ngxctx),如果你有兴趣可以自行查阅。
|
|
|
|
|
|
|
|
|
|
|
|
## 写在最后
|
|
|
|
|
|
|
|
|
|
|
|
最后,我再多说几句。这节课,我们学习的是 OpenResty 的原理和几个重要的概念,不过,你并不需要背得滚瓜烂熟,毕竟,这些概念总是在和实际需求以及代码结合在一起时,才会变得有意义并生动起来。
|
|
|
|
|
|
|
|
|
|
|
|
不知道你是如何理解的呢?欢迎留言和我一起探讨,也欢迎你把这篇文章分享给你的同事、朋友,我们一起交流,一起进步。
|
|
|
|
|
|
|