364 lines
21 KiB
Markdown
364 lines
21 KiB
Markdown
|
|
# 12 | atomic:要保证原子操作,一定要使用这几种方法
|
|||
|
|
|
|||
|
|
你好,我是鸟窝。
|
|||
|
|
|
|||
|
|
前面我们在学习Mutex、RWMutex等并发原语的实现时,你可以看到,最底层是通过atomic包中的一些原子操作来实现的。当时,为了让你的注意力集中在这些原语的功能实现上,我并没有展开介绍这些原子操作是干什么用的。
|
|||
|
|
|
|||
|
|
你可能会说,这些并发原语已经可以应对大多数的并发场景了,为啥还要学习原子操作呢?其实,这是因为,在很多场景中,使用并发原语实现起来比较复杂,而原子操作可以帮助我们更轻松地实现底层的优化。
|
|||
|
|
|
|||
|
|
所以,现在,我会专门用一节课,带你仔细地了解一下什么是原子操作,atomic包都提供了哪些实现原子操作的方法。另外,我还会带你实现一个基于原子操作的数据结构。好了,接下来我们先来学习下什么是原子操作。
|
|||
|
|
|
|||
|
|
# 原子操作的基础知识
|
|||
|
|
|
|||
|
|
Package sync/atomic 实现了同步算法底层的原子的内存操作原语,我们把它叫做原子操作原语,它提供了一些实现原子操作的方法。
|
|||
|
|
|
|||
|
|
之所以叫原子操作,是因为一个原子在执行的时候,其它线程不会看到执行一半的操作结果。在其它线程看来,原子操作要么执行完了,要么还没有执行,就像一个最小的粒子-原子一样,不可分割。
|
|||
|
|
|
|||
|
|
CPU提供了基础的原子操作,不过,不同架构的系统的原子操作是不一样的。
|
|||
|
|
|
|||
|
|
对于单处理器单核系统来说,如果一个操作是由一个CPU指令来实现的,那么它就是原子操作,比如它的XCHG和INC等指令。如果操作是基于多条指令来实现的,那么,执行的过程中可能会被中断,并执行上下文切换,这样的话,原子性的保证就被打破了,因为这个时候,操作可能只执行了一半。
|
|||
|
|
|
|||
|
|
在多处理器多核系统中,原子操作的实现就比较复杂了。
|
|||
|
|
|
|||
|
|
由于cache的存在,单个核上的单个指令进行原子操作的时候,你要确保其它处理器或者核不访问此原子操作的地址,或者是确保其它处理器或者核总是访问原子操作之后的最新的值。x86架构中提供了指令前缀LOCK,LOCK保证了指令(比如LOCK CMPXCHG op1、op2)不会受其它处理器或CPU核的影响,有些指令(比如XCHG)本身就提供Lock的机制。不同的CPU架构提供的原子操作指令的方式也是不同的,比如对于多核的MIPS和ARM,提供了LL/SC(Load Link/Store Conditional)指令,可以帮助实现原子操作(ARMLL/SC指令 LDREX和STREX)。
|
|||
|
|
|
|||
|
|
**因为不同的CPU架构甚至不同的版本提供的原子操作的指令是不同的,所以,要用一种编程语言实现支持不同架构的原子操作是相当有难度的**。不过,还好这些都不需要你操心,因为Go提供了一个通用的原子操作的API,将更底层的不同的架构下的实现封装成atomic包,提供了修改类型的原子操作([atomic read-modify-write](https://preshing.com/20150402/you-can-do-any-kind-of-atomic-read-modify-write-operation/),RMW)和加载存储类型的原子操作([Load和Store](https://preshing.com/20130618/atomic-vs-non-atomic-operations/))的API,稍后我会一一介绍。
|
|||
|
|
|
|||
|
|
有的代码也会因为架构的不同而不同。有时看起来貌似一个操作是原子操作,但实际上,对于不同的架构来说,情况是不一样的。比如下面的代码的第4行,是将一个64位的值赋值给变量i:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
const x int64 = 1 + 1<<33
|
|||
|
|
|
|||
|
|
func main() {
|
|||
|
|
var i = x
|
|||
|
|
_ = i
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
如果你使用GOARCH=386的架构去编译这段代码,那么,第5行其实是被拆成了两个指令,分别操作低32位和高32位(使用 GOARCH=386 go tool compile -N -l test.go;GOARCH=386 go tool objdump -gnu test.o反编译试试):
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
如果GOARCH=amd64的架构去编译这段代码,那么,第5行其中的赋值操作其实是一条指令:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
所以,如果要想保证原子操作,切记一定要使用atomic提供的方法。
|
|||
|
|
|
|||
|
|
好了,了解了什么是原子操作以及不同系统的不同原子操作,接下来,我来介绍下atomic原子操作的应用场景。
|
|||
|
|
|
|||
|
|
# atomic原子操作的应用场景
|
|||
|
|
|
|||
|
|
开篇我说过,使用atomic的一些方法,我们可以实现更底层的一些优化。如果使用Mutex等并发原语进行这些优化,虽然可以解决问题,但是这些并发原语的实现逻辑比较复杂,对性能还是有一定的影响的。
|
|||
|
|
|
|||
|
|
举个例子:假设你想在程序中使用一个标志(flag,比如一个bool类型的变量),来标识一个定时任务是否已经启动执行了,你会怎么做呢?
|
|||
|
|
|
|||
|
|
我们先来看看加锁的方法。如果使用Mutex和RWMutex,在读取和设置这个标志的时候加锁,是可以做到互斥的、保证同一时刻只有一个定时任务在执行的,所以使用Mutex或者RWMutex是一种解决方案。
|
|||
|
|
|
|||
|
|
其实,这个场景中的问题不涉及到对资源复杂的竞争逻辑,只是会并发地读写这个标志,这类场景就适合使用atomic的原子操作。具体怎么做呢?你可以使用一个uint32类型的变量,如果这个变量的值是0,就标识没有任务在执行,如果它的值是1,就标识已经有任务在完成了。你看,是不是很简单呢?
|
|||
|
|
|
|||
|
|
再来看一个例子。假设你在开发应用程序的时候,需要从配置服务器中读取一个节点的配置信息。而且,在这个节点的配置发生变更的时候,你需要重新从配置服务器中拉取一份新的配置并更新。你的程序中可能有多个goroutine都依赖这份配置,涉及到对这个配置对象的并发读写,你可以使用读写锁实现对配置对象的保护。在大部分情况下,你也可以利用atomic实现配置对象的更新和加载。
|
|||
|
|
|
|||
|
|
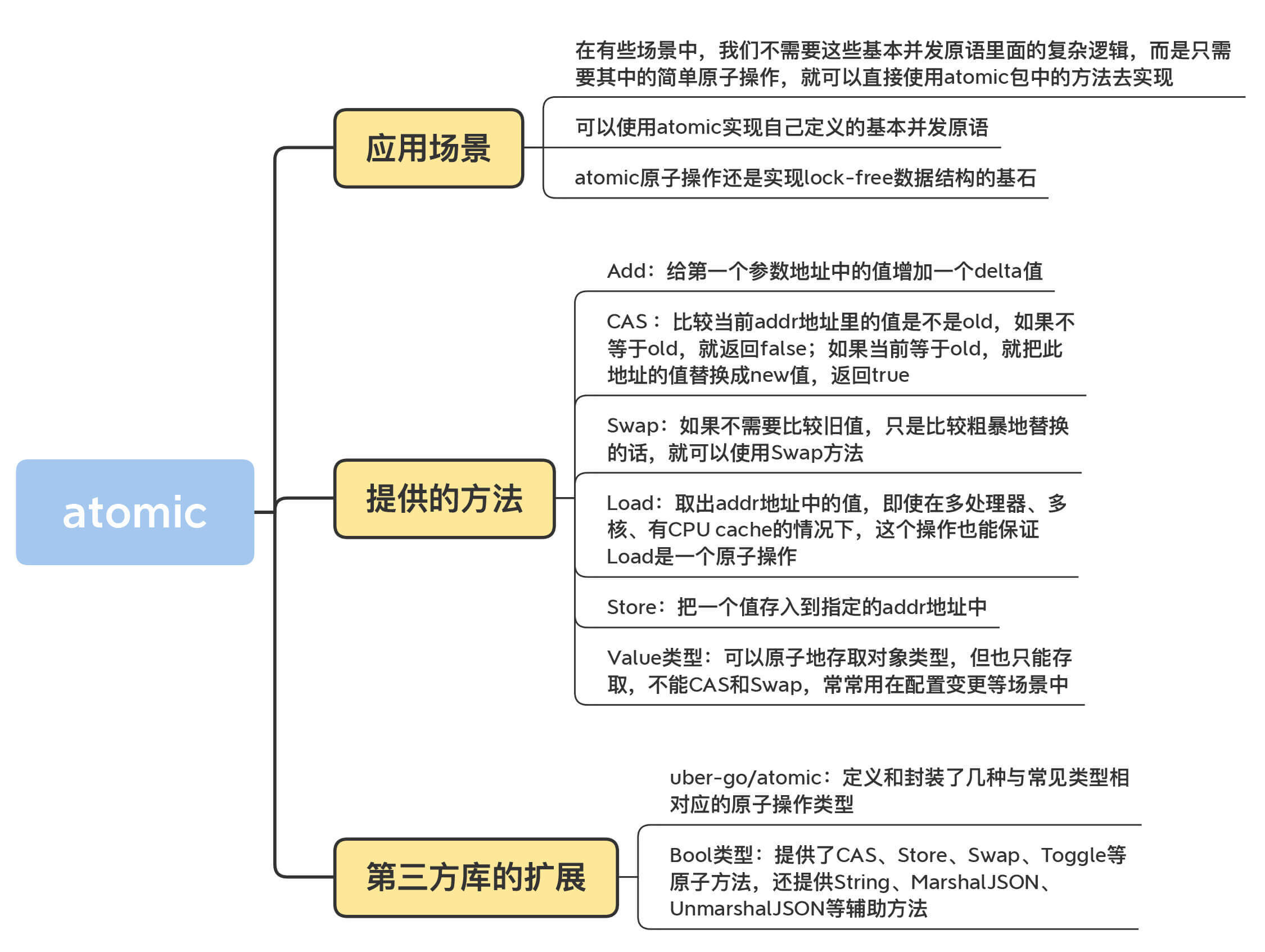
分析到这里,可以看到,这两个例子都可以使用基本并发原语来实现的,只不过,我们不需要这些基本并发原语里面的复杂逻辑,而是只需要其中的简单原子操作,所以,这些场景可以直接使用atomic包中的方法去实现。
|
|||
|
|
|
|||
|
|
**有时候,你也可以使用atomic实现自己定义的基本并发原语**,比如Go issue有人提议的CondMutex、Mutex.LockContext、WaitGroup.Go等,我们可以使用atomic或者基于它的更高一级的并发原语去实现。我先前讲的几种基本并发原语的底层(比如Mutex),就是基于通过atomic的方法实现的。
|
|||
|
|
|
|||
|
|
除此之外,atomic原子操作还是实现lock-free数据结构的基石。
|
|||
|
|
|
|||
|
|
在实现lock-free的数据结构时,我们可以不使用互斥锁,这样就不会让线程因为等待互斥锁而阻塞休眠,而是让线程保持继续处理的状态。另外,不使用互斥锁的话,lock-free的数据结构还可以提供并发的性能。
|
|||
|
|
|
|||
|
|
不过,lock-free的数据结构实现起来比较复杂,需要考虑的东西很多,有兴趣的同学可以看一位微软专家写的一篇经验分享:[Lockless Programming Considerations for Xbox 360 and Microsoft Windows](https://docs.microsoft.com/zh-cn/windows/win32/dxtecharts/lockless-programming),这里我们不细谈了。不过,这节课的最后我会带你开发一个lock-free的queue,来学习下使用atomic操作实现lock-free数据结构的方法,你可以拿它和使用互斥锁实现的queue做性能对比,看看在性能上是否有所提升。
|
|||
|
|
|
|||
|
|
看到这里,你是不是觉得atomic非常重要呢?不过,要想能够灵活地应用atomic,我们首先得知道atomic提供的所有方法。
|
|||
|
|
|
|||
|
|
# atomic提供的方法
|
|||
|
|
|
|||
|
|
目前的Go的泛型的特性还没有发布,Go的标准库中的很多实现会显得非常啰嗦,多个类型会实现很多类似的方法,尤其是atomic包,最为明显。相信泛型支持之后,atomic的API会清爽很多。
|
|||
|
|
|
|||
|
|
atomic为了支持int32、int64、uint32、uint64、uintptr、Pointer(Add方法不支持)类型,分别提供了AddXXX、CompareAndSwapXXX、SwapXXX、LoadXXX、StoreXXX等方法。不过,你也不要担心,你只要记住了一种数据类型的方法的意义,其它数据类型的方法也是一样的。
|
|||
|
|
|
|||
|
|
关于atomic,还有一个地方你一定要记住,**atomic操作的对象是一个地址,你需要把可寻址的变量的地址作为参数传递给方法,而不是把变量的值传递给方法**。
|
|||
|
|
|
|||
|
|
好了,下面我就来给你介绍一下atomic提供的方法。掌握了这些,你就可以说完全掌握了atomic包。
|
|||
|
|
|
|||
|
|
## Add
|
|||
|
|
|
|||
|
|
首先,我们来看Add方法的签名:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
其实,Add方法就是给第一个参数地址中的值增加一个delta值。
|
|||
|
|
|
|||
|
|
对于有符号的整数来说,delta可以是一个负数,相当于减去一个值。对于无符号的整数和uinptr类型来说,怎么实现减去一个值呢?毕竟,atomic并没有提供单独的减法操作。
|
|||
|
|
|
|||
|
|
我来跟你说一种方法。你可以利用计算机补码的规则,把减法变成加法。以uint32类型为例:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
AddUint32(&x, ^uint32(c-1)).
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
如果是对uint64的值进行操作,那么,就把上面的代码中的uint32替换成uint64。
|
|||
|
|
|
|||
|
|
尤其是减1这种特殊的操作,我们可以简化为:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
AddUint32(&x, ^uint32(0))
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
好了,我们再来看看CAS方法。
|
|||
|
|
|
|||
|
|
## CAS (CompareAndSwap)
|
|||
|
|
|
|||
|
|
以int32为例,我们学习一下CAS提供的功能。在CAS的方法签名中,需要提供要操作的地址、原数据值、新值,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们来看下这个方法的功能。
|
|||
|
|
|
|||
|
|
这个方法会比较当前addr地址里的值是不是old,如果不等于old,就返回false;如果等于old,就把此地址的值替换成new值,返回true。这就相当于“判断相等才替换”。
|
|||
|
|
|
|||
|
|
如果使用伪代码来表示这个原子操作,代码如下:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
if *addr == old {
|
|||
|
|
*addr = new
|
|||
|
|
return true
|
|||
|
|
}
|
|||
|
|
return false
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
它支持的类型和方法如图所示:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
## Swap
|
|||
|
|
|
|||
|
|
如果不需要比较旧值,只是比较粗暴地替换的话,就可以使用Swap方法,它替换后还可以返回旧值,伪代码如下:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
old = *addr
|
|||
|
|
*addr = new
|
|||
|
|
return old
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
它支持的数据类型和方法如图所示:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
## Load
|
|||
|
|
|
|||
|
|
Load方法会取出addr地址中的值,即使在多处理器、多核、有CPU cache的情况下,这个操作也能保证Load是一个原子操作。
|
|||
|
|
|
|||
|
|
它支持的数据类型和方法如图所示:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
## Store
|
|||
|
|
|
|||
|
|
Store方法会把一个值存入到指定的addr地址中,即使在多处理器、多核、有CPU cache的情况下,这个操作也能保证Store是一个原子操作。别的goroutine通过Load读取出来,不会看到存取了一半的值。
|
|||
|
|
|
|||
|
|
它支持的数据类型和方法如图所示:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
## Value类型
|
|||
|
|
|
|||
|
|
刚刚说的都是一些比较常见的类型,其实,atomic还提供了一个特殊的类型:Value。它可以原子地存取对象类型,但也只能存取,不能CAS和Swap,常常用在配置变更等场景中。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
接下来,我以一个配置变更的例子,来演示Value类型的使用。这里定义了一个Value类型的变量config, 用来存储配置信息。
|
|||
|
|
|
|||
|
|
首先,我们启动一个goroutine,然后让它随机sleep一段时间,之后就变更一下配置,并通过我们前面学到的Cond并发原语,通知其它的reader去加载新的配置。
|
|||
|
|
|
|||
|
|
接下来,我们启动一个goroutine等待配置变更的信号,一旦有变更,它就会加载最新的配置。
|
|||
|
|
|
|||
|
|
通过这个例子,你可以了解到Value的Store/Load方法的使用,因为它只有这两个方法,只要掌握了它们的使用,你就完全掌握了Value类型。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
type Config struct {
|
|||
|
|
NodeName string
|
|||
|
|
Addr string
|
|||
|
|
Count int32
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
func loadNewConfig() Config {
|
|||
|
|
return Config{
|
|||
|
|
NodeName: "北京",
|
|||
|
|
Addr: "10.77.95.27",
|
|||
|
|
Count: rand.Int31(),
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
func main() {
|
|||
|
|
var config atomic.Value
|
|||
|
|
config.Store(loadNewConfig())
|
|||
|
|
var cond = sync.NewCond(&sync.Mutex{})
|
|||
|
|
|
|||
|
|
// 设置新的config
|
|||
|
|
go func() {
|
|||
|
|
for {
|
|||
|
|
time.Sleep(time.Duration(5+rand.Int63n(5)) * time.Second)
|
|||
|
|
config.Store(loadNewConfig())
|
|||
|
|
cond.Broadcast() // 通知等待着配置已变更
|
|||
|
|
}
|
|||
|
|
}()
|
|||
|
|
|
|||
|
|
go func() {
|
|||
|
|
for {
|
|||
|
|
cond.L.Lock()
|
|||
|
|
cond.Wait() // 等待变更信号
|
|||
|
|
c := config.Load().(Config) // 读取新的配置
|
|||
|
|
fmt.Printf("new config: %+v\n", c)
|
|||
|
|
cond.L.Unlock()
|
|||
|
|
}
|
|||
|
|
}()
|
|||
|
|
|
|||
|
|
select {}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
好了,关于标准库的atomic提供的方法,到这里我们就学完了。事实上,atomic包提供了非常好的支持各种平台的一致性的API,绝大部分项目都是直接使用它。接下来,我再给你介绍一下第三方库,帮助你稍微开拓一下思维。
|
|||
|
|
|
|||
|
|
# 第三方库的扩展
|
|||
|
|
|
|||
|
|
其实,atomic的API已经算是很简单的了,它提供了包一级的函数,可以对几种类型的数据执行原子操作。
|
|||
|
|
|
|||
|
|
不过有一点让人觉得不爽的是,或者是让熟悉面向对象编程的程序员不爽的是,函数调用有一点点麻烦。所以,有些人就对这些函数做了进一步的包装,跟atomic中的Value类型类似,这些类型也提供了面向对象的使用方式,比如关注度比较高的[uber-go/atomic](https://github.com/uber-go/atomic),它定义和封装了几种与常见类型相对应的原子操作类型,这些类型提供了原子操作的方法。这些类型包括Bool、Duration、Error、Float64、Int32、Int64、String、Uint32、Uint64等。
|
|||
|
|
|
|||
|
|
比如Bool类型,提供了CAS、Store、Swap、Toggle等原子方法,还提供String、MarshalJSON、UnmarshalJSON等辅助方法,确实是一个精心设计的atomic扩展库。关于这些方法,你一看名字就能猜出来它们的功能,我就不多说了。
|
|||
|
|
|
|||
|
|
其它的数据类型也和Bool类型相似,使用起来就像面向对象的编程一样,你可以看下下面的这段代码。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
var running atomic.Bool
|
|||
|
|
running.Store(true)
|
|||
|
|
running.Toggle()
|
|||
|
|
fmt.Println(running.Load()) // false
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
# 使用atomic实现Lock-Free queue
|
|||
|
|
|
|||
|
|
atomic常常用来实现Lock-Free的数据结构,这次我会给你展示一个Lock-Free queue的实现。
|
|||
|
|
|
|||
|
|
Lock-Free queue最出名的就是 Maged M. Michael 和 Michael L. Scott 1996年发表的[论文](https://www.cs.rochester.edu/u/scott/papers/1996_PODC_queues.pdf)中的算法,算法比较简单,容易实现,伪代码的每一行都提供了注释,我就不在这里贴出伪代码了,因为我们使用Go实现这个数据结构的代码几乎和伪代码一样:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
package queue
|
|||
|
|
import (
|
|||
|
|
"sync/atomic"
|
|||
|
|
"unsafe"
|
|||
|
|
)
|
|||
|
|
// lock-free的queue
|
|||
|
|
type LKQueue struct {
|
|||
|
|
head unsafe.Pointer
|
|||
|
|
tail unsafe.Pointer
|
|||
|
|
}
|
|||
|
|
// 通过链表实现,这个数据结构代表链表中的节点
|
|||
|
|
type node struct {
|
|||
|
|
value interface{}
|
|||
|
|
next unsafe.Pointer
|
|||
|
|
}
|
|||
|
|
func NewLKQueue() *LKQueue {
|
|||
|
|
n := unsafe.Pointer(&node{})
|
|||
|
|
return &LKQueue{head: n, tail: n}
|
|||
|
|
}
|
|||
|
|
// 入队
|
|||
|
|
func (q *LKQueue) Enqueue(v interface{}) {
|
|||
|
|
n := &node{value: v}
|
|||
|
|
for {
|
|||
|
|
tail := load(&q.tail)
|
|||
|
|
next := load(&tail.next)
|
|||
|
|
if tail == load(&q.tail) { // 尾还是尾
|
|||
|
|
if next == nil { // 还没有新数据入队
|
|||
|
|
if cas(&tail.next, next, n) { //增加到队尾
|
|||
|
|
cas(&q.tail, tail, n) //入队成功,移动尾巴指针
|
|||
|
|
return
|
|||
|
|
}
|
|||
|
|
} else { // 已有新数据加到队列后面,需要移动尾指针
|
|||
|
|
cas(&q.tail, tail, next)
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
// 出队,没有元素则返回nil
|
|||
|
|
func (q *LKQueue) Dequeue() interface{} {
|
|||
|
|
for {
|
|||
|
|
head := load(&q.head)
|
|||
|
|
tail := load(&q.tail)
|
|||
|
|
next := load(&head.next)
|
|||
|
|
if head == load(&q.head) { // head还是那个head
|
|||
|
|
if head == tail { // head和tail一样
|
|||
|
|
if next == nil { // 说明是空队列
|
|||
|
|
return nil
|
|||
|
|
}
|
|||
|
|
// 只是尾指针还没有调整,尝试调整它指向下一个
|
|||
|
|
cas(&q.tail, tail, next)
|
|||
|
|
} else {
|
|||
|
|
// 读取出队的数据
|
|||
|
|
v := next.value
|
|||
|
|
// 既然要出队了,头指针移动到下一个
|
|||
|
|
if cas(&q.head, head, next) {
|
|||
|
|
return v // Dequeue is done. return
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// 将unsafe.Pointer原子加载转换成node
|
|||
|
|
func load(p *unsafe.Pointer) (n *node) {
|
|||
|
|
return (*node)(atomic.LoadPointer(p))
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// 封装CAS,避免直接将*node转换成unsafe.Pointer
|
|||
|
|
func cas(p *unsafe.Pointer, old, new *node) (ok bool) {
|
|||
|
|
return atomic.CompareAndSwapPointer(
|
|||
|
|
p, unsafe.Pointer(old), unsafe.Pointer(new))
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我来给你介绍下这里的主要逻辑。
|
|||
|
|
|
|||
|
|
这个lock-free的实现使用了一个辅助头指针(head),头指针不包含有意义的数据,只是一个辅助的节点,这样的话,出队入队中的节点会更简单。
|
|||
|
|
|
|||
|
|
入队的时候,通过CAS操作将一个元素添加到队尾,并且移动尾指针。
|
|||
|
|
|
|||
|
|
出队的时候移除一个节点,并通过CAS操作移动head指针,同时在必要的时候移动尾指针。
|
|||
|
|
|
|||
|
|
# 总结
|
|||
|
|
|
|||
|
|
好了,我们来小结一下。这节课,我们学习了atomic的基本使用方法,以及它提供的几种方法,包括Add、CAS、Swap、Load、Store、Value类型。除此之外,我还介绍了一些第三方库,并且带你实现了Lock-free queue。到这里,相信你已经掌握了atomic提供的各种方法,并且能够应用到实践中了。
|
|||
|
|
|
|||
|
|
最后,我还想和你讨论一个额外的问题:对一个地址的赋值是原子操作吗?
|
|||
|
|
|
|||
|
|
这是一个很有趣的问题,如果是原子操作,还要atomic包干什么?官方的文档中并没有特意的介绍,不过,在一些issue或者论坛中,每当有人谈到这个问题时,总是会被建议用atomic包。
|
|||
|
|
|
|||
|
|
[Dave Cheney](https://dave.cheney.net/2018/01/06/if-aligned-memory-writes-are-atomic-why-do-we-need-the-sync-atomic-package)就谈到过这个问题,讲得非常好。我来给你总结一下他讲的知识点,这样你就比较容易理解使用atomic和直接内存操作的区别了。
|
|||
|
|
|
|||
|
|
在现在的系统中,write的地址基本上都是对齐的(aligned)。 比如,32位的操作系统、CPU以及编译器,write的地址总是4的倍数,64位的系统总是8的倍数(还记得WaitGroup针对64位系统和32位系统对state1的字段不同的处理吗)。对齐地址的写,不会导致其他人看到只写了一半的数据,因为它通过一个指令就可以实现对地址的操作。如果地址不是对齐的话,那么,处理器就需要分成两个指令去处理,如果执行了一个指令,其它人就会看到更新了一半的错误的数据,这被称做撕裂写(torn write) 。所以,你可以认为赋值操作是一个原子操作,这个“原子操作”可以认为是保证数据的完整性。
|
|||
|
|
|
|||
|
|
但是,对于现代的多处理多核的系统来说,由于cache、指令重排,可见性等问题,我们对原子操作的意义有了更多的追求。在多核系统中,一个核对地址的值的更改,在更新到主内存中之前,是在多级缓存中存放的。这时,多个核看到的数据可能是不一样的,其它的核可能还没有看到更新的数据,还在使用旧的数据。
|
|||
|
|
|
|||
|
|
多处理器多核心系统为了处理这类问题,使用了一种叫做内存屏障(memory fence或memory barrier)的方式。一个写内存屏障会告诉处理器,必须要等到它管道中的未完成的操作(特别是写操作)都被刷新到内存中,再进行操作。此操作还会让相关的处理器的CPU缓存失效,以便让它们从主存中拉取最新的值。
|
|||
|
|
|
|||
|
|
atomic包提供的方法会提供内存屏障的功能,所以,atomic不仅仅可以保证赋值的数据完整性,还能保证数据的可见性,一旦一个核更新了该地址的值,其它处理器总是能读取到它的最新值。但是,需要注意的是,因为需要处理器之间保证数据的一致性,atomic的操作也是会降低性能的。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
# 思考题
|
|||
|
|
|
|||
|
|
atomic.Value只有Load/Store方法,你是不是感觉意犹未尽?你可以尝试为Value类型增加 Swap和CompareAndSwap方法(可以参考一下[这份资料](https://github.com/golang/go/issues/39351))。
|
|||
|
|
|
|||
|
|
欢迎在留言区写下你的思考和答案,我们一起交流讨论。如果你觉得有所收获,也欢迎你把今天的内容分享给你的朋友或同事。
|
|||
|
|
|