|
|
|
|
|
# 006 | 精读2017年EMNLP最佳短论文
|
|
|
|
|
|
|
|
|
|
|
|
在今年的EMNLP大会上,有两类研究论文得到发表,一类是8页的长研究论文,主要是比较完整的研究结果;另一类是4页的短研究论文,主要是比较新的有待进一步推敲的研究结果。大会从长研究论文中选出两篇最佳论文,从短论文中选出一篇最佳论文。
|
|
|
|
|
|
|
|
|
|
|
|
前面我们分别讨论了两篇最佳长论文,今天,我就带你认真剖析一下EMNLP 2017年的最佳短论文《多智能体对话中,自然语言并非“自然”出现》(Natural Language Does Not Merge ‘Naturally’ in Multi-Agent Dialog)。我们今天讲的论文虽然是最佳短论文,但是作者们已经在arXiv发表了较长的文章版本,因此我今天的讲解将基于arXiv的长版本。
|
|
|
|
|
|
|
|
|
|
|
|
这篇文章研究的一个主要命题就是,多个“机器人”(Agent)对话中如何才能避免产生“非自然”(Unnatural)的对话。以前很多机器人对话的研究都关注准确率的高低,但实际上机器人产生的对话是不自然的,人类交流不会用这样的方式。这篇文章希望探讨的就是这样非自然的对话是如何产生的,有没有什么方式避免这样的结果。
|
|
|
|
|
|
|
|
|
|
|
|
## 作者群信息介绍
|
|
|
|
|
|
|
|
|
|
|
|
第一作者萨特维克·库托儿(Satwik Kottur)来自卡内基梅隆大学,博士第四年,研究领域为计算机视觉、自然语言和机器学习。2016年暑假他在Snapchat的研究团队实习,研究对话系统中的个性化问题。2017年暑假在Facebook研究院实习,做视觉对话系统(Visual Dialog System)的研究。近两年,萨特维克已在多个国际顶级会议如ICML 2017、IJCAI 2017、CVPR 2017、ICCV 2017以及NIPS 2017发表了多篇高质量研究论文,包括这篇EMNLP 2017的最佳短论文,可以说是一颗冉冉升起的学术新星。
|
|
|
|
|
|
|
|
|
|
|
|
第二作者何塞·毛拉(José M. F. Moura)是萨特维克在卡内基梅隆大学的导师。何塞是NAE(美国国家工程院)院士和IEEE(电气电子工程师学会)院士,长期从事信号处理以及大数据、数据科学的研究工作。他当选2018年IEEE总裁,负责IEEE下一个阶段的发展。
|
|
|
|
|
|
|
|
|
|
|
|
第三作者斯特凡·李(Stefan Lee)是来自乔治亚理工大学的研究科学家,之前在弗吉尼亚理工大学任职,长期从事计算机视觉、自然语言处理等多方面的研究。斯特凡2016年博士毕业于印第安纳大学计算机系。
|
|
|
|
|
|
|
|
|
|
|
|
第四作者德鲁·巴塔(Dhruv Batra)目前是Facebook研究院的科学家,也是乔治亚理工大学的助理教授。德鲁2010年博士毕业于卡内基梅隆大学;2010年到2012年在位于芝加哥的丰田理工大学担任研究助理教授;2013年到2016年在弗吉尼亚大学任教。德鲁长期从事人工智能特别是视觉系统以及人机交互系统的研究工作。文章的第三作者斯特凡是德鲁长期的研究合作者,他们一起已经发表了包括本文在内的多篇高质量论文。
|
|
|
|
|
|
|
|
|
|
|
|
## 论文的主要贡献
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看看这篇文章主要解决了一个什么场景下的问题。
|
|
|
|
|
|
|
|
|
|
|
|
人工智能的一个核心场景,或者说想要实现的一个目标,就是能够建立一个目标导向(Goal-Driven)的自动对话系统(Dialog System)。具体来说,在这样的系统中,机器人能够感知它们的环境(包括视觉、听觉以及其他感官),然后能和人或者其他机器人利用自然语言进行对话,从而实现某种目的。
|
|
|
|
|
|
|
|
|
|
|
|
目前对目标导向的自动对话系统的研究主要有两种思路。
|
|
|
|
|
|
|
|
|
|
|
|
一种思路是把整个问题看做静态的监督学习任务(Supervised Learning),希望利用大量的数据,通过神经对话模型(Neural Dialog Models)来对对话系统进行建模。这个模式虽然在近些年的研究中取得了一些成绩,但是仍然很难解决一个大问题,那就是产生的“对话”其实不像真人对话,不具备真实语言的很多特性。
|
|
|
|
|
|
|
|
|
|
|
|
另外一种思路则把学习对话系统的任务看做一个连续的过程,然后用强化学习(Reinforcement Learning)的模式来对整个对话系统建模。
|
|
|
|
|
|
|
|
|
|
|
|
这篇文章尝试探讨,在什么样的情况下能够让机器人学习到类似人的语言。文章的一个核心发现就是,自然语言并不是自然出现的。在目前的研究状态下,**自然语言的出现还是一个没有确定答案的开放问题**。可以说,这就是这篇最佳短论文的主要贡献。
|
|
|
|
|
|
|
|
|
|
|
|
## 论文的核心方法
|
|
|
|
|
|
|
|
|
|
|
|
整篇文章其实是建立在一个虚拟的机器人交互场景里,也就是有两个机器人互相对话的一个环境。这个环境里有非常有限的物件(Object),每个物件包括三种属性(颜色、形状和样式),每一个属性包括四种可能取值,这样,在这个虚拟的环境中一共就有64个物件。
|
|
|
|
|
|
|
|
|
|
|
|
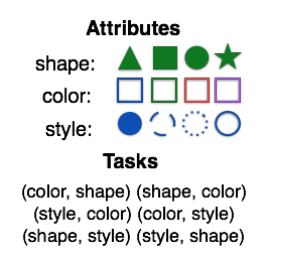
|
|
|
|
|
|
|
|
|
|
|
|
交互任务其实是两个机器人进行“猜谜”。为了区分,我们把两个机器人分为Q机器人和A机器人。猜谜一开始的时候,A机器人得到一个物件,也就是三种属性的某种实现组合,Q机器人并不知道这个物件。这个时候,Q机器人拿到两个属性的名字,需要通过对话最终猜出A拿到的这个物件所对应属性的取值。
|
|
|
|
|
|
|
|
|
|
|
|
在这个“游戏”的过程中,A是不知道Q手上的两个属性究竟是什么的,而Q也不知道A所拿的物件以及物件所对应属性的取值。因此,对话就是Q能够取得成功的关键因素。
|
|
|
|
|
|
|
|
|
|
|
|
在这篇文章里,Q和A的这个游戏**通过强化学习进行建模**。Q保持一组参数用于记录当前的状态。这组状态有最开始需要猜的属性,以及后面到当前状态为止所有Q的回答以及A的问题。类似地,A也保持这么一组状态,用于记录到目前位置的信息。这个强化学习最终的回馈是,当最后的预测值完全正确时,会有一个正1的反馈,而错误的话就是负10的反馈。
|
|
|
|
|
|
|
|
|
|
|
|
Q和A的模型都有三个模块:听、说和预测。以Q来举例,“听”模块是从要猜的属性这个任务开始,往后每一个步骤接受A的语句,从而更新自己的内部状态。“说”模块是根据当前的内部状态,决定下一步需要说的语句。最后“预测”模块则是根据所有的状态预测最后的属性值。
|
|
|
|
|
|
|
|
|
|
|
|
A机器人的结构是对称的。每一个模块本身都是一个 **LSTM** (Long Short-Term Memory,长短期记忆)模型。当然,所有这些LSTM模型的参数是不一样的。整个模型采用了**REINFORCE算法**(也被称作“vanilla” policy gradient,“基本”策略梯度)来学习参数,而具体的实现则采用了PyTorch软件包。
|
|
|
|
|
|
|
|
|
|
|
|
## 方法的实验效果
|
|
|
|
|
|
|
|
|
|
|
|
在提出的方法上,作者们展示了Q均能很快地以比较高的准确度做出预测,并且在和A的互动中产生了“语言”。不过遗憾的是,通过观察,作者们发现这样的“语言”往往并不自然。最直观的一种情况就是,A可以忽视掉Q的各种反应,而直接把A的内部信息通过某种编码直接“暴露”给Q,从而Q可以很快赢得游戏,取得几乎完美的预测结果。这显然不是想要的结果。
|
|
|
|
|
|
|
|
|
|
|
|
作者们发现,在词汇量(Vocabulary)非常大的情况下,这种情况尤其容易发生,那就是A把自己的整个状态都暴露给Q。于是,作者们假定**要想出现比较有意义的交流,词汇数目一定不能过大**。
|
|
|
|
|
|
|
|
|
|
|
|
于是,作者们采用了限制词汇数目的方式,让词汇数目与属性的可能值和属性数目相等,这样就限制了在完美情况下交流的复杂度,使得A没办法过度交流。然而,这样的策略可以很好地对一个属性做出判断,但是无法对属性的叠加(因为Q最终是要猜两个属性)做出判断。
|
|
|
|
|
|
|
|
|
|
|
|
文章给出的一个解决方案是,让A机器人忘记过去的状态,强行让A机器人学习使用相同的一组状态来表达相同的意思,而不是有可能使用新的状态。**在这样的限制条件以及无记忆两种约束下,A和Q的对话呈现出显著的自然语言的叠加性特征,而且在没有出现过的属性上表现出了接近两倍的准确率**,这是之前的方法所不能达到的效果。
|
|
|
|
|
|
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
|
|
|
|
|
|
今天我为你讲了EMNLP 2017年的最佳短论文,这篇文章介绍了在一个机器人对话系统中,如何能让机器人的对话更贴近人之间的行为。
|
|
|
|
|
|
|
|
|
|
|
|
这篇文章也是**第一篇从谈话的自然程度**,而不是从预测准确度去分析对话系统的论文。文章的一个核心观点是,如果想让对话自然,就必须避免机器人简单地把答案泄露给对方,或者说要避免有过大的词汇库。
|
|
|
|
|
|
|
|
|
|
|
|
一起来回顾下要点:第一,我简要介绍了这篇文章的作者群信息,文章作者在相关领域均发表过多篇高质量研究成果论文。第二,这篇文章论证了多智能体对话中自然语言的出现并不自然。第三,论文提出在词汇量限制条件和无记忆约束下,机器人对话可以呈现出一定的自然语言特征。
|
|
|
|
|
|
|
|
|
|
|
|
最后,给你留一个思考题,文章讲的是一个比较简单的对话场景,有一个局限的词汇库,如果是真实的人与人或者机器与机器的对话,我们如何来确定需要多大的词汇量呢?
|
|
|
|
|
|
|
|
|
|
|
|
欢迎你给我留言,和我一起讨论。
|
|
|
|
|
|
|
|
|
|
|
|
**名词解释**:
|
|
|
|
|
|
|
|
|
|
|
|
**ICML 2017**,International Conference on Machine Learning ,国际机器学习大会。
|
|
|
|
|
|
|
|
|
|
|
|
**IJCAI 2017**, International Joint Conference on Artificial Intelligence,人工智能国际联合大会。
|
|
|
|
|
|
|
|
|
|
|
|
**CVPR 2017**,Conference on Computer Vision and Pattern Recognition,国际计算机视觉与模式识别会议。
|
|
|
|
|
|
|
|
|
|
|
|
**ICCV 2017**,International Conference on Computer Vision,国际计算机视觉大会。
|
|
|
|
|
|
|
|
|
|
|
|
**NIPS 2017**,Annual Conference on Neural Information Processing Systems,神经信息处理系统大会。
|
|
|
|
|
|
|
|
|
|
|
|
拓展阅读:[Natural Language Does Not Merge ‘Naturally’ in Multi-Agent Dialog](http://aclweb.org/anthology/D17-1320)
|
|
|
|
|
|
|