|
|
|
|
|
# 25 | 用户态内存映射:如何找到正确的会议室?
|
|
|
|
|
|
|
|
|
|
|
|
前面几节,我们既看了虚拟内存空间如何组织的,也看了物理页面如何管理的。现在我们需要一些数据结构,将二者关联起来。
|
|
|
|
|
|
|
|
|
|
|
|
## mmap的原理
|
|
|
|
|
|
|
|
|
|
|
|
在虚拟地址空间那一节,我们知道,每一个进程都有一个列表vm\_area\_struct,指向虚拟地址空间的不同的内存块,这个变量的名字叫**mmap**。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct mm_struct {
|
|
|
|
|
|
struct vm_area_struct *mmap; /* list of VMAs */
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
struct vm_area_struct {
|
|
|
|
|
|
/*
|
|
|
|
|
|
* For areas with an address space and backing store,
|
|
|
|
|
|
* linkage into the address_space->i_mmap interval tree.
|
|
|
|
|
|
*/
|
|
|
|
|
|
struct {
|
|
|
|
|
|
struct rb_node rb;
|
|
|
|
|
|
unsigned long rb_subtree_last;
|
|
|
|
|
|
} shared;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/*
|
|
|
|
|
|
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
|
|
|
|
|
|
* list, after a COW of one of the file pages. A MAP_SHARED vma
|
|
|
|
|
|
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
|
|
|
|
|
|
* or brk vma (with NULL file) can only be in an anon_vma list.
|
|
|
|
|
|
*/
|
|
|
|
|
|
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
|
|
|
|
|
|
* page_table_lock */
|
|
|
|
|
|
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/* Function pointers to deal with this struct. */
|
|
|
|
|
|
const struct vm_operations_struct *vm_ops;
|
|
|
|
|
|
/* Information about our backing store: */
|
|
|
|
|
|
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
|
|
|
|
|
|
units */
|
|
|
|
|
|
struct file * vm_file; /* File we map to (can be NULL). */
|
|
|
|
|
|
void * vm_private_data; /* was vm_pte (shared mem) */
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
其实内存映射不仅仅是物理内存和虚拟内存之间的映射,还包括将文件中的内容映射到虚拟内存空间。这个时候,访问内存空间就能够访问到文件里面的数据。而仅有物理内存和虚拟内存的映射,是一种特殊情况。
|
|
|
|
|
|
|
|
|
|
|
|
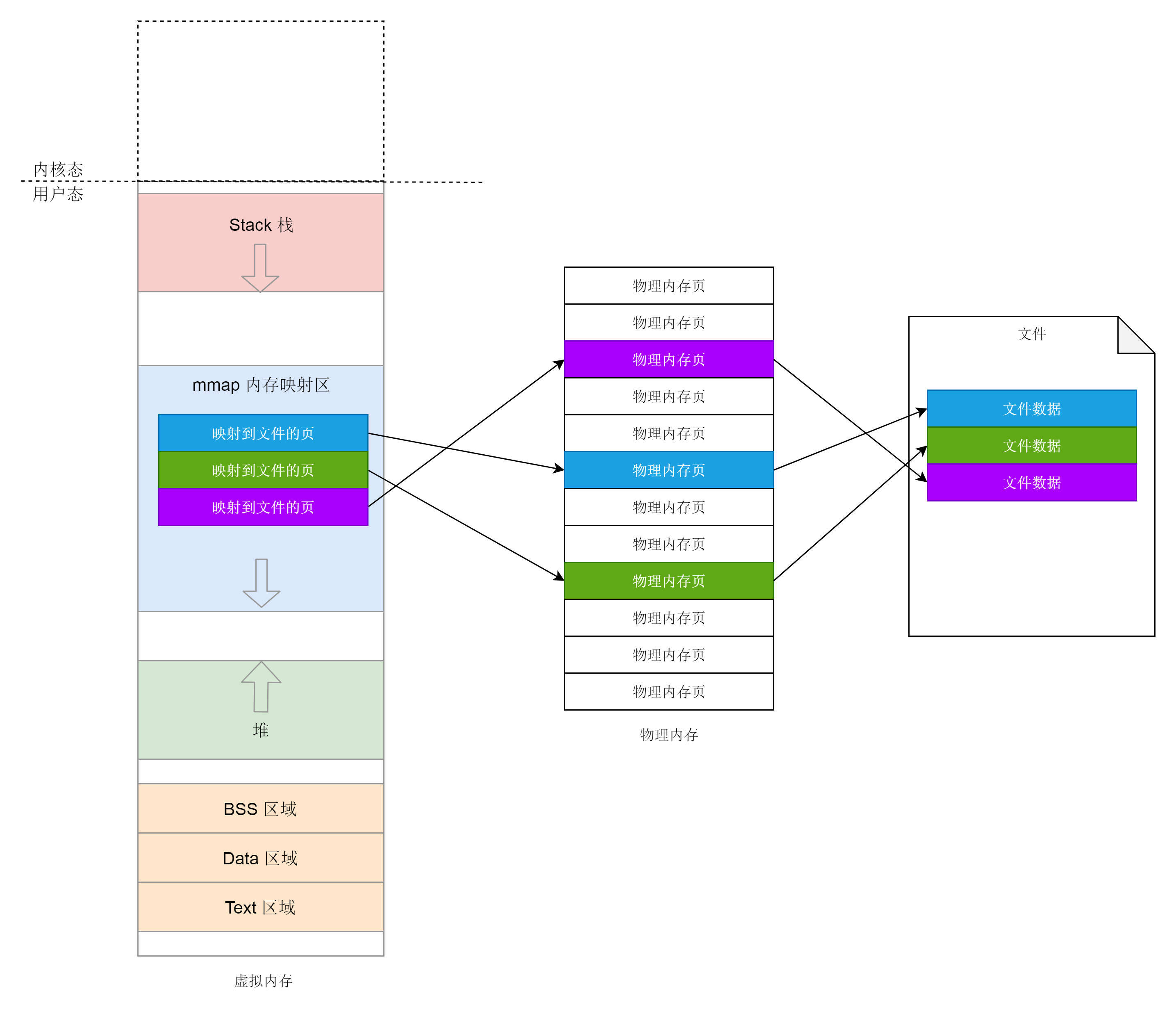
|
|
|
|
|
|
|
|
|
|
|
|
前面咱们讲堆的时候讲过,如果我们要申请小块内存,就用brk。brk函数之前已经解析过了,这里就不多说了。如果申请一大块内存,就要用mmap。对于堆的申请来讲,mmap是映射内存空间到物理内存。
|
|
|
|
|
|
|
|
|
|
|
|
另外,如果一个进程想映射一个文件到自己的虚拟内存空间,也要通过mmap系统调用。这个时候mmap是映射内存空间到物理内存再到文件。可见mmap这个系统调用是核心,我们现在来看mmap这个系统调用。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
|
|
|
|
|
|
unsigned long, prot, unsigned long, flags,
|
|
|
|
|
|
unsigned long, fd, unsigned long, off)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
|
|
|
|
|
|
unsigned long, prot, unsigned long, flags,
|
|
|
|
|
|
unsigned long, fd, unsigned long, pgoff)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct file *file = NULL;
|
|
|
|
|
|
......
|
|
|
|
|
|
file = fget(fd);
|
|
|
|
|
|
......
|
|
|
|
|
|
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
|
|
|
|
|
|
return retval;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
如果要映射到文件,fd会传进来一个文件描述符,并且mmap\_pgoff里面通过fget函数,根据文件描述符获得struct file。struct file表示打开的一个文件。
|
|
|
|
|
|
|
|
|
|
|
|
接下来的调用链是vm\_mmap\_pgoff->do\_mmap\_pgoff->do\_mmap。这里面主要干了两件事情:
|
|
|
|
|
|
|
|
|
|
|
|
* 调用get\_unmapped\_area找到一个没有映射的区域;
|
|
|
|
|
|
|
|
|
|
|
|
* 调用mmap\_region映射这个区域。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看get\_unmapped\_area函数。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
unsigned long
|
|
|
|
|
|
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
|
|
|
|
|
|
unsigned long pgoff, unsigned long flags)
|
|
|
|
|
|
{
|
|
|
|
|
|
unsigned long (*get_area)(struct file *, unsigned long,
|
|
|
|
|
|
unsigned long, unsigned long, unsigned long);
|
|
|
|
|
|
......
|
|
|
|
|
|
get_area = current->mm->get_unmapped_area;
|
|
|
|
|
|
if (file) {
|
|
|
|
|
|
if (file->f_op->get_unmapped_area)
|
|
|
|
|
|
get_area = file->f_op->get_unmapped_area;
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里面如果是匿名映射,则调用mm\_struct里面的get\_unmapped\_area函数。这个函数其实是arch\_get\_unmapped\_area。它会调用find\_vma\_prev,在表示虚拟内存区域的vm\_area\_struct红黑树上找到相应的位置。之所以叫prev,是说这个时候虚拟内存区域还没有建立,找到前一个vm\_area\_struct。
|
|
|
|
|
|
|
|
|
|
|
|
如果不是匿名映射,而是映射到一个文件,这样在Linux里面,每个打开的文件都有一个struct file结构,里面有一个file\_operations,用来表示和这个文件相关的操作。如果是我们熟知的ext4文件系统,调用的是thp\_get\_unmapped\_area。如果我们仔细看这个函数,最终还是调用mm\_struct里面的get\_unmapped\_area函数。殊途同归。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
const struct file_operations ext4_file_operations = {
|
|
|
|
|
|
......
|
|
|
|
|
|
.mmap = ext4_file_mmap
|
|
|
|
|
|
.get_unmapped_area = thp_get_unmapped_area,
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
unsigned long __thp_get_unmapped_area(struct file *filp, unsigned long len,
|
|
|
|
|
|
loff_t off, unsigned long flags, unsigned long size)
|
|
|
|
|
|
{
|
|
|
|
|
|
unsigned long addr;
|
|
|
|
|
|
loff_t off_end = off + len;
|
|
|
|
|
|
loff_t off_align = round_up(off, size);
|
|
|
|
|
|
unsigned long len_pad;
|
|
|
|
|
|
len_pad = len + size;
|
|
|
|
|
|
......
|
|
|
|
|
|
addr = current->mm->get_unmapped_area(filp, 0, len_pad,
|
|
|
|
|
|
off >> PAGE_SHIFT, flags);
|
|
|
|
|
|
addr += (off - addr) & (size - 1);
|
|
|
|
|
|
return addr;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
我们再来看mmap\_region,看它如何映射这个虚拟内存区域。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
unsigned long mmap_region(struct file *file, unsigned long addr,
|
|
|
|
|
|
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
|
|
|
|
|
|
struct list_head *uf)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct mm_struct *mm = current->mm;
|
|
|
|
|
|
struct vm_area_struct *vma, *prev;
|
|
|
|
|
|
struct rb_node **rb_link, *rb_parent;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/*
|
|
|
|
|
|
* Can we just expand an old mapping?
|
|
|
|
|
|
*/
|
|
|
|
|
|
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
|
|
|
|
|
|
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
|
|
|
|
|
|
if (vma)
|
|
|
|
|
|
goto out;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/*
|
|
|
|
|
|
* Determine the object being mapped and call the appropriate
|
|
|
|
|
|
* specific mapper. the address has already been validated, but
|
|
|
|
|
|
* not unmapped, but the maps are removed from the list.
|
|
|
|
|
|
*/
|
|
|
|
|
|
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
|
|
|
|
|
|
if (!vma) {
|
|
|
|
|
|
error = -ENOMEM;
|
|
|
|
|
|
goto unacct_error;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
vma->vm_mm = mm;
|
|
|
|
|
|
vma->vm_start = addr;
|
|
|
|
|
|
vma->vm_end = addr + len;
|
|
|
|
|
|
vma->vm_flags = vm_flags;
|
|
|
|
|
|
vma->vm_page_prot = vm_get_page_prot(vm_flags);
|
|
|
|
|
|
vma->vm_pgoff = pgoff;
|
|
|
|
|
|
INIT_LIST_HEAD(&vma->anon_vma_chain);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (file) {
|
|
|
|
|
|
vma->vm_file = get_file(file);
|
|
|
|
|
|
error = call_mmap(file, vma);
|
|
|
|
|
|
addr = vma->vm_start;
|
|
|
|
|
|
vm_flags = vma->vm_flags;
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
vma_link(mm, vma, prev, rb_link, rb_parent);
|
|
|
|
|
|
return addr;
|
|
|
|
|
|
.....
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
还记得咱们刚找到了虚拟内存区域的前一个vm\_area\_struct,我们首先要看,是否能够基于它进行扩展,也即调用vma\_merge,和前一个vm\_area\_struct合并到一起。
|
|
|
|
|
|
|
|
|
|
|
|
如果不能,就需要调用kmem\_cache\_zalloc,在Slub里面创建一个新的vm\_area\_struct对象,设置起始和结束位置,将它加入队列。如果是映射到文件,则设置vm\_file为目标文件,调用call\_mmap。其实就是调用file\_operations的mmap函数。对于ext4文件系统,调用的是ext4\_file\_mmap。从这个函数的参数可以看出,这一刻文件和内存开始发生关系了。这里我们将vm\_area\_struct的内存操作设置为文件系统操作,也就是说,读写内存其实就是读写文件系统。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
|
|
|
|
|
|
{
|
|
|
|
|
|
return file->f_op->mmap(file, vma);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
vma->vm_ops = &ext4_file_vm_ops;
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
我们再回到mmap\_region函数。最终,vma\_link函数将新创建的vm\_area\_struct挂在了mm\_struct里面的红黑树上。
|
|
|
|
|
|
|
|
|
|
|
|
这个时候,从内存到文件的映射关系,至少要在逻辑层面建立起来。那从文件到内存的映射关系呢?vma\_link还做了另外一件事情,就是\_\_vma\_link\_file。这个东西要用于建立这层映射关系。
|
|
|
|
|
|
|
|
|
|
|
|
对于打开的文件,会有一个结构struct file来表示。它有个成员指向struct address\_space结构,这里面有棵变量名为i\_mmap的红黑树,vm\_area\_struct就挂在这棵树上。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct address_space {
|
|
|
|
|
|
struct inode *host; /* owner: inode, block_device */
|
|
|
|
|
|
......
|
|
|
|
|
|
struct rb_root i_mmap; /* tree of private and shared mappings */
|
|
|
|
|
|
......
|
|
|
|
|
|
const struct address_space_operations *a_ops; /* methods */
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
static void __vma_link_file(struct vm_area_struct *vma)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct file *file;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
file = vma->vm_file;
|
|
|
|
|
|
if (file) {
|
|
|
|
|
|
struct address_space *mapping = file->f_mapping;
|
|
|
|
|
|
vma_interval_tree_insert(vma, &mapping->i_mmap);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
到这里,内存映射的内容要告一段落了。你可能会困惑,好像还没和物理内存发生任何关系,还是在虚拟内存里面折腾呀?
|
|
|
|
|
|
|
|
|
|
|
|
对的,因为到目前为止,我们还没有开始真正访问内存呀!这个时候,内存管理并不直接分配物理内存,因为物理内存相对于虚拟地址空间太宝贵了,只有等你真正用的那一刻才会开始分配。
|
|
|
|
|
|
|
|
|
|
|
|
## 用户态缺页异常
|
|
|
|
|
|
|
|
|
|
|
|
一旦开始访问虚拟内存的某个地址,如果我们发现,并没有对应的物理页,那就触发缺页中断,调用do\_page\_fault。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
dotraplinkage void notrace
|
|
|
|
|
|
do_page_fault(struct pt_regs *regs, unsigned long error_code)
|
|
|
|
|
|
{
|
|
|
|
|
|
unsigned long address = read_cr2(); /* Get the faulting address */
|
|
|
|
|
|
......
|
|
|
|
|
|
__do_page_fault(regs, error_code, address);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/*
|
|
|
|
|
|
* This routine handles page faults. It determines the address,
|
|
|
|
|
|
* and the problem, and then passes it off to one of the appropriate
|
|
|
|
|
|
* routines.
|
|
|
|
|
|
*/
|
|
|
|
|
|
static noinline void
|
|
|
|
|
|
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
|
|
|
|
|
|
unsigned long address)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct vm_area_struct *vma;
|
|
|
|
|
|
struct task_struct *tsk;
|
|
|
|
|
|
struct mm_struct *mm;
|
|
|
|
|
|
tsk = current;
|
|
|
|
|
|
mm = tsk->mm;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (unlikely(fault_in_kernel_space(address))) {
|
|
|
|
|
|
if (vmalloc_fault(address) >= 0)
|
|
|
|
|
|
return;
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
vma = find_vma(mm, address);
|
|
|
|
|
|
......
|
|
|
|
|
|
fault = handle_mm_fault(vma, address, flags);
|
|
|
|
|
|
......
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在\_\_do\_page\_fault里面,先要判断缺页中断是否发生在内核。如果发生在内核则调用vmalloc\_fault,这就和咱们前面学过的虚拟内存的布局对应上了。在内核里面,vmalloc区域需要内核页表映射到物理页。咱们这里把内核的这部分放放,接着看用户空间的部分。
|
|
|
|
|
|
|
|
|
|
|
|
接下来在用户空间里面,找到你访问的那个地址所在的区域vm\_area\_struct,然后调用handle\_mm\_fault来映射这个区域。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
|
|
|
|
|
|
unsigned int flags)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct vm_fault vmf = {
|
|
|
|
|
|
.vma = vma,
|
|
|
|
|
|
.address = address & PAGE_MASK,
|
|
|
|
|
|
.flags = flags,
|
|
|
|
|
|
.pgoff = linear_page_index(vma, address),
|
|
|
|
|
|
.gfp_mask = __get_fault_gfp_mask(vma),
|
|
|
|
|
|
};
|
|
|
|
|
|
struct mm_struct *mm = vma->vm_mm;
|
|
|
|
|
|
pgd_t *pgd;
|
|
|
|
|
|
p4d_t *p4d;
|
|
|
|
|
|
int ret;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
pgd = pgd_offset(mm, address);
|
|
|
|
|
|
p4d = p4d_alloc(mm, pgd, address);
|
|
|
|
|
|
......
|
|
|
|
|
|
vmf.pud = pud_alloc(mm, p4d, address);
|
|
|
|
|
|
......
|
|
|
|
|
|
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
|
|
|
|
|
|
......
|
|
|
|
|
|
return handle_pte_fault(&vmf);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
到这里,终于看到了我们熟悉的PGD、P4G、PUD、PMD、PTE,这就是前面讲页表的时候,讲述的四级页表的概念,因为暂且不考虑五级页表,我们暂时忽略P4G。
|
|
|
|
|
|
|
|
|
|
|
|
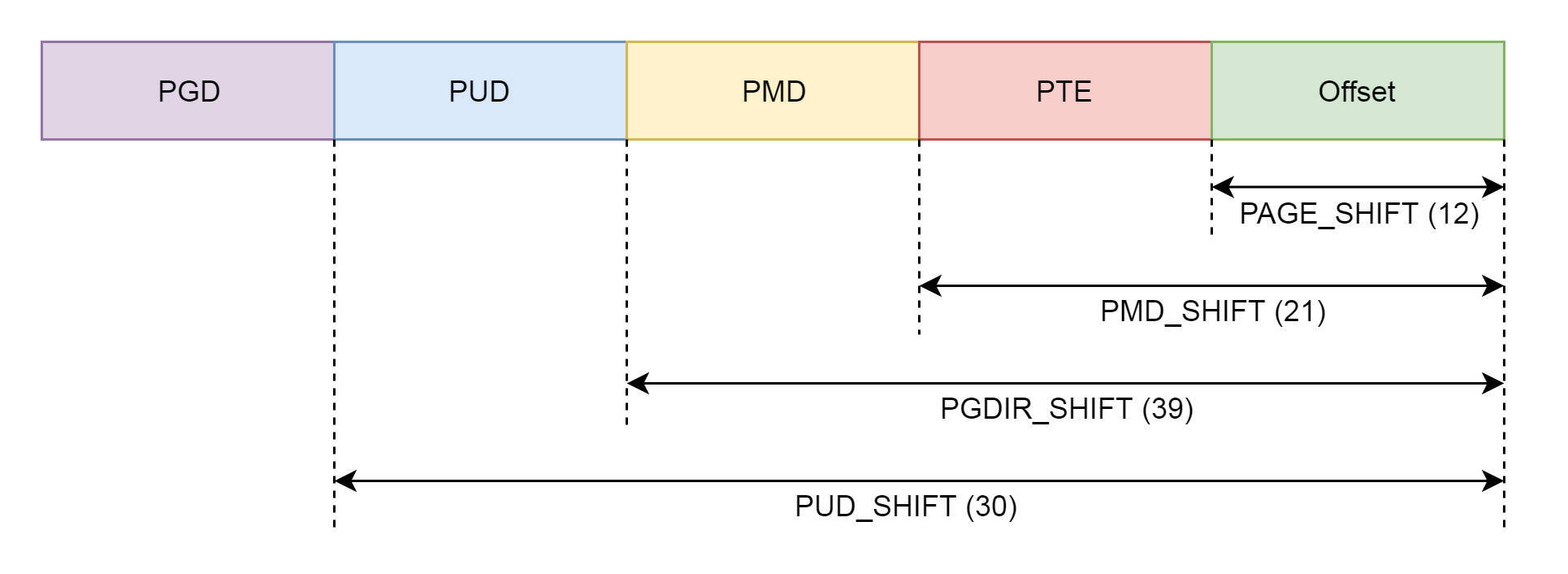
|
|
|
|
|
|
|
|
|
|
|
|
pgd\_t 用于全局页目录项,pud\_t 用于上层页目录项,pmd\_t 用于中间页目录项,pte\_t 用于直接页表项。
|
|
|
|
|
|
|
|
|
|
|
|
每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶级的pgd存放在task\_struct中的mm\_struct的pgd变量里面。
|
|
|
|
|
|
|
|
|
|
|
|
在一个进程新创建的时候,会调用fork,对于内存的部分会调用copy\_mm,里面调用dup\_mm。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/*
|
|
|
|
|
|
* Allocate a new mm structure and copy contents from the
|
|
|
|
|
|
* mm structure of the passed in task structure.
|
|
|
|
|
|
*/
|
|
|
|
|
|
static struct mm_struct *dup_mm(struct task_struct *tsk)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct mm_struct *mm, *oldmm = current->mm;
|
|
|
|
|
|
mm = allocate_mm();
|
|
|
|
|
|
memcpy(mm, oldmm, sizeof(*mm));
|
|
|
|
|
|
if (!mm_init(mm, tsk, mm->user_ns))
|
|
|
|
|
|
goto fail_nomem;
|
|
|
|
|
|
err = dup_mmap(mm, oldmm);
|
|
|
|
|
|
return mm;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在这里,除了创建一个新的mm\_struct,并且通过memcpy将它和父进程的弄成一模一样之外,我们还需要调用mm\_init进行初始化。接下来,mm\_init调用mm\_alloc\_pgd,分配全局页目录项,赋值给mm\_struct的pgd成员变量。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static inline int mm_alloc_pgd(struct mm_struct *mm)
|
|
|
|
|
|
{
|
|
|
|
|
|
mm->pgd = pgd_alloc(mm);
|
|
|
|
|
|
return 0;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
pgd\_alloc里面除了分配PGD之外,还做了很重要的一个事情,就是调用pgd\_ctor。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static void pgd_ctor(struct mm_struct *mm, pgd_t *pgd)
|
|
|
|
|
|
{
|
|
|
|
|
|
/* If the pgd points to a shared pagetable level (either the
|
|
|
|
|
|
ptes in non-PAE, or shared PMD in PAE), then just copy the
|
|
|
|
|
|
references from swapper_pg_dir. */
|
|
|
|
|
|
if (CONFIG_PGTABLE_LEVELS == 2 ||
|
|
|
|
|
|
(CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) ||
|
|
|
|
|
|
CONFIG_PGTABLE_LEVELS >= 4) {
|
|
|
|
|
|
clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY,
|
|
|
|
|
|
swapper_pg_dir + KERNEL_PGD_BOUNDARY,
|
|
|
|
|
|
KERNEL_PGD_PTRS);
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
pgd\_ctor干了什么事情呢?我们注意看里面的注释,它拷贝了对于swapper\_pg\_dir的引用。swapper\_pg\_dir是内核页表的最顶级的全局页目录。
|
|
|
|
|
|
|
|
|
|
|
|
一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表,这就和上面遇到的vmalloc有关系了。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表。至于swapper\_pg\_dir是什么,怎么初始化的,怎么工作的,我们还是先放一放,放到下一节统一讨论。
|
|
|
|
|
|
|
|
|
|
|
|
至此,一个进程fork完毕之后,有了内核页表,有了自己顶级的pgd,但是对于用户地址空间来讲,还完全没有映射过。这需要等到这个进程在某个CPU上运行,并且对内存访问的那一刻了。
|
|
|
|
|
|
|
|
|
|
|
|
当这个进程被调度到某个CPU上运行的时候,咱们在[调度](https://time.geekbang.org/column/article/93251)那一节讲过,要调用context\_switch进行上下文切换。对于内存方面的切换会调用switch\_mm\_irqs\_off,这里面会调用 load\_new\_mm\_cr3。
|
|
|
|
|
|
|
|
|
|
|
|
cr3是CPU的一个寄存器,它会指向当前进程的顶级pgd。如果CPU的指令要访问进程的虚拟内存,它就会自动从cr3里面得到pgd在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
|
|
|
|
|
|
|
|
|
|
|
|
这里需要注意两点。第一点,cr3里面存放当前进程的顶级pgd,这个是硬件的要求。cr3里面需要存放pgd在物理内存的地址,不能是虚拟地址。因而load\_new\_mm\_cr3里面会使用\_\_pa,将mm\_struct里面的成员变量pgd(mm\_struct里面存的都是虚拟地址)变为物理地址,才能加载到cr3里面去。
|
|
|
|
|
|
|
|
|
|
|
|
第二点,用户进程在运行的过程中,访问虚拟内存中的数据,会被cr3里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态。
|
|
|
|
|
|
|
|
|
|
|
|
只有访问虚拟内存的时候,发现没有映射到物理内存,页表也没有创建过,才触发缺页异常。进入内核调用do\_page\_fault,一直调用到\_\_handle\_mm\_fault,这才有了上面解析到这个函数的时候,我们看到的代码。既然原来没有创建过页表,那只好补上这一课。于是,\_\_handle\_mm\_fault调用pud\_alloc和pmd\_alloc,来创建相应的页目录项,最后调用handle\_pte\_fault来创建页表项。
|
|
|
|
|
|
|
|
|
|
|
|
绕了一大圈,终于将页表整个机制的各个部分串了起来。但是咱们的故事还没讲完,物理的内存还没找到。我们还得接着分析handle\_pte\_fault的实现。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int handle_pte_fault(struct vm_fault *vmf)
|
|
|
|
|
|
{
|
|
|
|
|
|
pte_t entry;
|
|
|
|
|
|
......
|
|
|
|
|
|
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
|
|
|
|
|
|
vmf->orig_pte = *vmf->pte;
|
|
|
|
|
|
......
|
|
|
|
|
|
if (!vmf->pte) {
|
|
|
|
|
|
if (vma_is_anonymous(vmf->vma))
|
|
|
|
|
|
return do_anonymous_page(vmf);
|
|
|
|
|
|
else
|
|
|
|
|
|
return do_fault(vmf);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (!pte_present(vmf->orig_pte))
|
|
|
|
|
|
return do_swap_page(vmf);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里面总的来说分了三种情况。如果PTE,也就是页表项,从来没有出现过,那就是新映射的页。如果是匿名页,就是第一种情况,应该映射到一个物理内存页,在这里调用的是do\_anonymous\_page。如果是映射到文件,调用的就是do\_fault,这是第二种情况。如果PTE原来出现过,说明原来页面在物理内存中,后来换出到硬盘了,现在应该换回来,调用的是do\_swap\_page。
|
|
|
|
|
|
|
|
|
|
|
|
我们来看第一种情况,do\_anonymous\_page。对于匿名页的映射,我们需要先通过pte\_alloc分配一个页表项,然后通过alloc\_zeroed\_user\_highpage\_movable分配一个页。之后它会调用alloc\_pages\_vma,并最终调用\_\_alloc\_pages\_nodemask。
|
|
|
|
|
|
|
|
|
|
|
|
这个函数你还记得吗?就是咱们伙伴系统的核心函数,专门用来分配物理页面的。do\_anonymous\_page接下来要调用mk\_pte,将页表项指向新分配的物理页,set\_pte\_at会将页表项塞到页表里面。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int do_anonymous_page(struct vm_fault *vmf)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct vm_area_struct *vma = vmf->vma;
|
|
|
|
|
|
struct mem_cgroup *memcg;
|
|
|
|
|
|
struct page *page;
|
|
|
|
|
|
int ret = 0;
|
|
|
|
|
|
pte_t entry;
|
|
|
|
|
|
......
|
|
|
|
|
|
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
|
|
|
|
|
|
return VM_FAULT_OOM;
|
|
|
|
|
|
......
|
|
|
|
|
|
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
|
|
|
|
|
|
......
|
|
|
|
|
|
entry = mk_pte(page, vma->vm_page_prot);
|
|
|
|
|
|
if (vma->vm_flags & VM_WRITE)
|
|
|
|
|
|
entry = pte_mkwrite(pte_mkdirty(entry));
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
|
|
|
|
|
|
&vmf->ptl);
|
|
|
|
|
|
......
|
|
|
|
|
|
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
第二种情况映射到文件do\_fault,最终我们会调用\_\_do\_fault。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int __do_fault(struct vm_fault *vmf)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct vm_area_struct *vma = vmf->vma;
|
|
|
|
|
|
int ret;
|
|
|
|
|
|
......
|
|
|
|
|
|
ret = vma->vm_ops->fault(vmf);
|
|
|
|
|
|
......
|
|
|
|
|
|
return ret;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里调用了struct vm\_operations\_struct vm\_ops的fault函数。还记得咱们上面用mmap映射文件的时候,对于ext4文件系统,vm\_ops指向了ext4\_file\_vm\_ops,也就是调用了ext4\_filemap\_fault。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static const struct vm_operations_struct ext4_file_vm_ops = {
|
|
|
|
|
|
.fault = ext4_filemap_fault,
|
|
|
|
|
|
.map_pages = filemap_map_pages,
|
|
|
|
|
|
.page_mkwrite = ext4_page_mkwrite,
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
int ext4_filemap_fault(struct vm_fault *vmf)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct inode *inode = file_inode(vmf->vma->vm_file);
|
|
|
|
|
|
......
|
|
|
|
|
|
err = filemap_fault(vmf);
|
|
|
|
|
|
......
|
|
|
|
|
|
return err;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
ext4\_filemap\_fault里面的逻辑我们很容易就能读懂。vm\_file就是咱们当时mmap的时候映射的那个文件,然后我们需要调用filemap\_fault。对于文件映射来说,一般这个文件会在物理内存里面有页面作为它的缓存,find\_get\_page就是找那个页。如果找到了,就调用do\_async\_mmap\_readahead,预读一些数据到内存里面;如果没有,就跳到no\_cached\_page。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
int filemap_fault(struct vm_fault *vmf)
|
|
|
|
|
|
{
|
|
|
|
|
|
int error;
|
|
|
|
|
|
struct file *file = vmf->vma->vm_file;
|
|
|
|
|
|
struct address_space *mapping = file->f_mapping;
|
|
|
|
|
|
struct inode *inode = mapping->host;
|
|
|
|
|
|
pgoff_t offset = vmf->pgoff;
|
|
|
|
|
|
struct page *page;
|
|
|
|
|
|
int ret = 0;
|
|
|
|
|
|
......
|
|
|
|
|
|
page = find_get_page(mapping, offset);
|
|
|
|
|
|
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
|
|
|
|
|
|
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
|
|
|
|
|
|
} else if (!page) {
|
|
|
|
|
|
goto no_cached_page;
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
vmf->page = page;
|
|
|
|
|
|
return ret | VM_FAULT_LOCKED;
|
|
|
|
|
|
no_cached_page:
|
|
|
|
|
|
error = page_cache_read(file, offset, vmf->gfp_mask);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
如果没有物理内存中的缓存页,那我们就调用page\_cache\_read。在这里显示分配一个缓存页,将这一页加到lru表里面,然后在address\_space中调用address\_space\_operations的readpage函数,将文件内容读到内存中。address\_space的作用咱们上面也介绍过了。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int page_cache_read(struct file *file, pgoff_t offset, gfp_t gfp_mask)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct address_space *mapping = file->f_mapping;
|
|
|
|
|
|
struct page *page;
|
|
|
|
|
|
......
|
|
|
|
|
|
page = __page_cache_alloc(gfp_mask|__GFP_COLD);
|
|
|
|
|
|
......
|
|
|
|
|
|
ret = add_to_page_cache_lru(page, mapping, offset, gfp_mask & GFP_KERNEL);
|
|
|
|
|
|
......
|
|
|
|
|
|
ret = mapping->a_ops->readpage(file, page);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
struct address\_space\_operations对于ext4文件系统的定义如下所示。这么说来,上面的readpage调用的其实是ext4\_readpage。因为我们还没讲到文件系统,这里我们不详细介绍ext4\_readpage具体干了什么。你只要知道,最后会调用ext4\_read\_inline\_page,这里面有部分逻辑和内存映射有关就行了。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static const struct address_space_operations ext4_aops = {
|
|
|
|
|
|
.readpage = ext4_readpage,
|
|
|
|
|
|
.readpages = ext4_readpages,
|
|
|
|
|
|
......
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
static int ext4_read_inline_page(struct inode *inode, struct page *page)
|
|
|
|
|
|
{
|
|
|
|
|
|
void *kaddr;
|
|
|
|
|
|
......
|
|
|
|
|
|
kaddr = kmap_atomic(page);
|
|
|
|
|
|
ret = ext4_read_inline_data(inode, kaddr, len, &iloc);
|
|
|
|
|
|
flush_dcache_page(page);
|
|
|
|
|
|
kunmap_atomic(kaddr);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在ext4\_read\_inline\_page函数里,我们需要先调用kmap\_atomic,将物理内存映射到内核的虚拟地址空间,得到内核中的地址kaddr。 我们在前面提到过kmap\_atomic,它是用来做临时内核映射的。本来把物理内存映射到用户虚拟地址空间,不需要在内核里面映射一把。但是,现在因为要从文件里面读取数据并写入这个物理页面,又不能使用物理地址,我们只能使用虚拟地址,这就需要在内核里面临时映射一把。临时映射后,ext4\_read\_inline\_data读取文件到这个虚拟地址。读取完毕后,我们取消这个临时映射kunmap\_atomic就行了。
|
|
|
|
|
|
|
|
|
|
|
|
至于kmap\_atomic的具体实现,我们还是放到内核映射部分再讲。
|
|
|
|
|
|
|
|
|
|
|
|
我们再来看第三种情况,do\_swap\_page。之前我们讲过物理内存管理,你这里可以回忆一下。如果长时间不用,就要换出到硬盘,也就是swap,现在这部分数据又要访问了,我们还得想办法再次读到内存中来。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
int do_swap_page(struct vm_fault *vmf)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct vm_area_struct *vma = vmf->vma;
|
|
|
|
|
|
struct page *page, *swapcache;
|
|
|
|
|
|
struct mem_cgroup *memcg;
|
|
|
|
|
|
swp_entry_t entry;
|
|
|
|
|
|
pte_t pte;
|
|
|
|
|
|
......
|
|
|
|
|
|
entry = pte_to_swp_entry(vmf->orig_pte);
|
|
|
|
|
|
......
|
|
|
|
|
|
page = lookup_swap_cache(entry);
|
|
|
|
|
|
if (!page) {
|
|
|
|
|
|
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE, vma,
|
|
|
|
|
|
vmf->address);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
swapcache = page;
|
|
|
|
|
|
......
|
|
|
|
|
|
pte = mk_pte(page, vma->vm_page_prot);
|
|
|
|
|
|
......
|
|
|
|
|
|
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
|
|
|
|
|
|
vmf->orig_pte = pte;
|
|
|
|
|
|
......
|
|
|
|
|
|
swap_free(entry);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
do\_swap\_page函数会先查找swap文件有没有缓存页。如果没有,就调用swapin\_readahead,将swap文件读到内存中来,形成内存页,并通过mk\_pte生成页表项。set\_pte\_at将页表项插入页表,swap\_free将swap文件清理。因为重新加载回内存了,不再需要swap文件了。
|
|
|
|
|
|
|
|
|
|
|
|
swapin\_readahead会最终调用swap\_readpage,在这里,我们看到了熟悉的readpage函数,也就是说读取普通文件和读取swap文件,过程是一样的,同样需要用kmap\_atomic做临时映射。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
int swap_readpage(struct page *page, bool do_poll)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct bio *bio;
|
|
|
|
|
|
int ret = 0;
|
|
|
|
|
|
struct swap_info_struct *sis = page_swap_info(page);
|
|
|
|
|
|
blk_qc_t qc;
|
|
|
|
|
|
struct block_device *bdev;
|
|
|
|
|
|
......
|
|
|
|
|
|
if (sis->flags & SWP_FILE) {
|
|
|
|
|
|
struct file *swap_file = sis->swap_file;
|
|
|
|
|
|
struct address_space *mapping = swap_file->f_mapping;
|
|
|
|
|
|
ret = mapping->a_ops->readpage(swap_file, page);
|
|
|
|
|
|
return ret;
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
通过上面复杂的过程,用户态缺页异常处理完毕了。物理内存中有了页面,页表也建立好了映射。接下来,用户程序在虚拟内存空间里面,可以通过虚拟地址顺利经过页表映射的访问物理页面上的数据了。
|
|
|
|
|
|
|
|
|
|
|
|
为了加快映射速度,我们不需要每次从虚拟地址到物理地址的转换都走一遍页表。
|
|
|
|
|
|
|
|
|
|
|
|
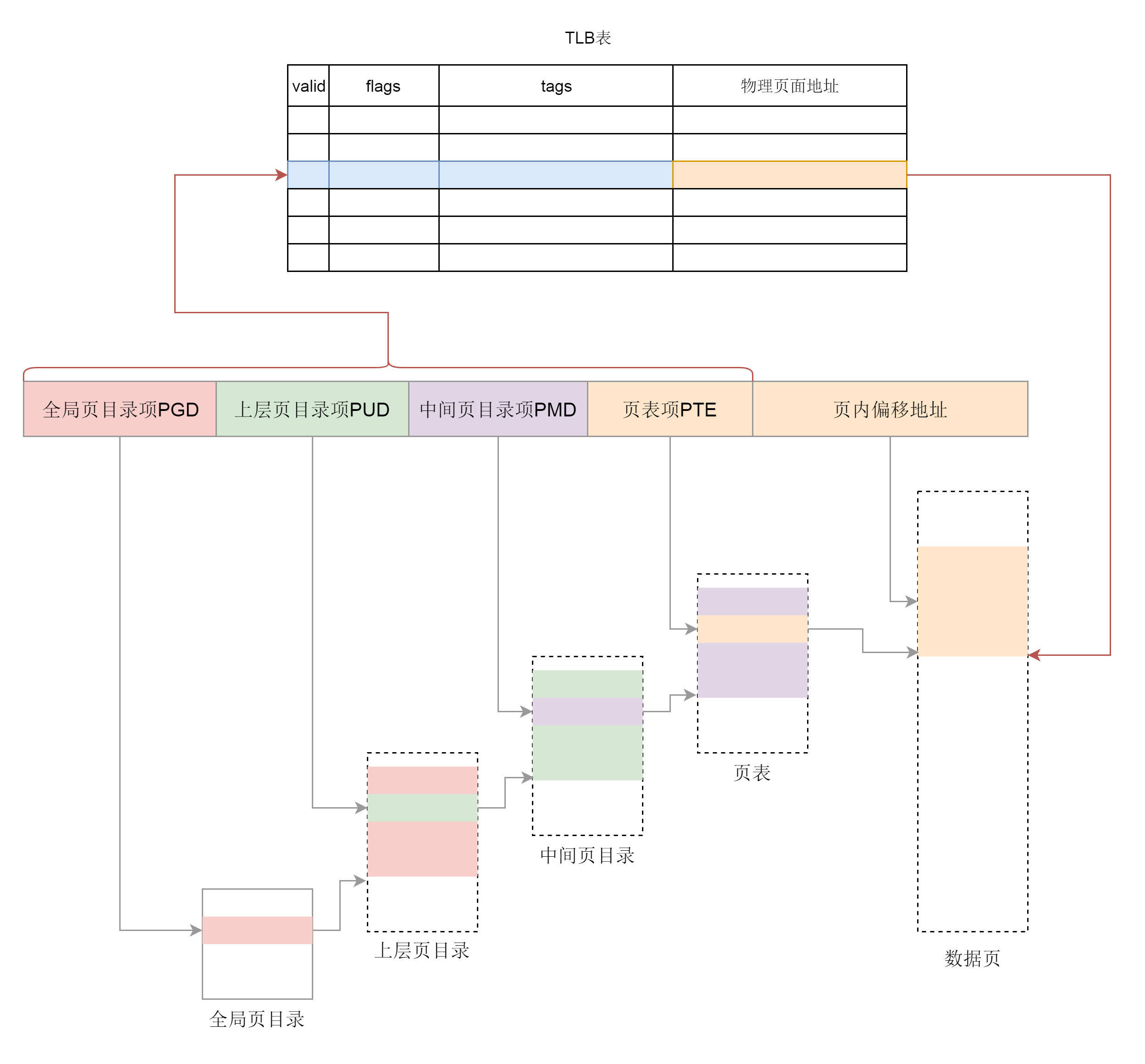
|
|
|
|
|
|
|
|
|
|
|
|
页表一般都很大,只能存放在内存中。操作系统每次访问内存都要折腾两步,先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。
|
|
|
|
|
|
|
|
|
|
|
|
为了提高映射速度,我们引入了**TLB**(Translation Lookaside Buffer),我们经常称为**快表**,专门用来做地址映射的硬件设备。它不在内存中,可存储的数据比较少,但是比内存要快。所以,我们可以想象,TLB就是页表的Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。
|
|
|
|
|
|
|
|
|
|
|
|
有了TLB之后,地址映射的过程就像图中画的。我们先查块表,块表中有映射关系,然后直接转换为物理地址。如果在TLB查不到映射关系时,才会到内存中查询页表。
|
|
|
|
|
|
|
|
|
|
|
|
## 总结时刻
|
|
|
|
|
|
|
|
|
|
|
|
用户态的内存映射机制,我们解析的差不多了,我们来总结一下,用户态的内存映射机制包含以下几个部分。
|
|
|
|
|
|
|
|
|
|
|
|
* 用户态内存映射函数mmap,包括用它来做匿名映射和文件映射。
|
|
|
|
|
|
|
|
|
|
|
|
* 用户态的页表结构,存储位置在mm\_struct中。
|
|
|
|
|
|
|
|
|
|
|
|
* 在用户态访问没有映射的内存会引发缺页异常,分配物理页表、补齐页表。如果是匿名映射则分配物理内存;如果是swap,则将swap文件读入;如果是文件映射,则将文件读入。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
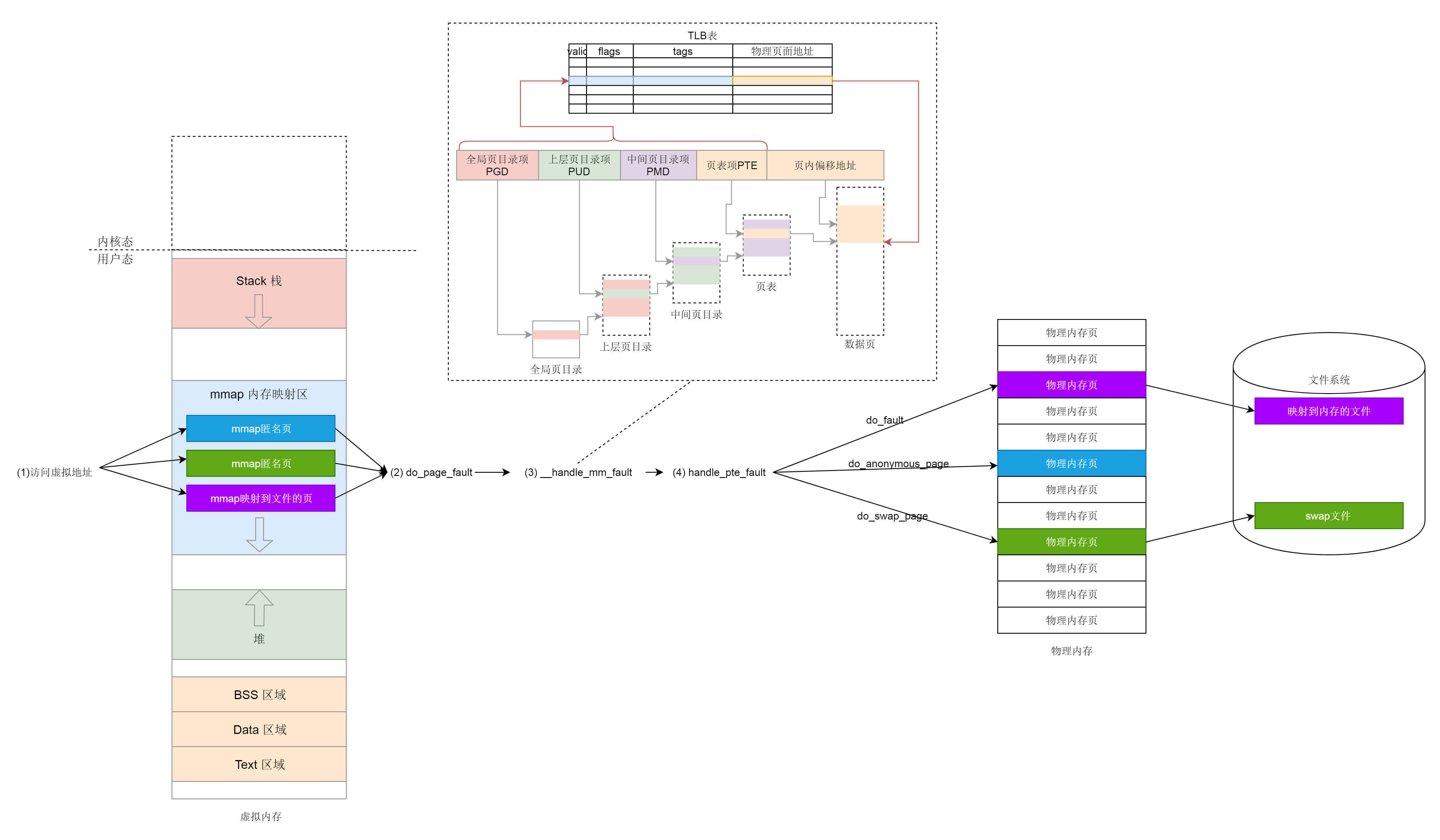
|
|
|
|
|
|
|
|
|
|
|
|
## 课堂练习
|
|
|
|
|
|
|
|
|
|
|
|
你可以试着用mmap系统调用,写一个程序来映射一个文件,并读取文件的内容。
|
|
|
|
|
|
|
|
|
|
|
|
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|