|
|
|
|
|
# 16 | 调度(中):主动调度是如何发生的?
|
|
|
|
|
|
|
|
|
|
|
|
上一节,我们为调度准备了这么多的数据结构,这一节我们来看调度是如何发生的。
|
|
|
|
|
|
|
|
|
|
|
|
所谓进程调度,其实就是一个人在做A项目,在某个时刻,换成做B项目去了。发生这种情况,主要有两种方式。
|
|
|
|
|
|
|
|
|
|
|
|
**方式一**:A项目做着做着,发现里面有一条指令sleep,也就是要休息一下,或者在等待某个I/O事件。那没办法了,就要主动让出CPU,然后可以开始做B项目。
|
|
|
|
|
|
|
|
|
|
|
|
**方式二**:A项目做着做着,旷日持久,实在受不了了。项目经理介入了,说这个项目A先停停,B项目也要做一下,要不然B项目该投诉了。
|
|
|
|
|
|
|
|
|
|
|
|
## 主动调度
|
|
|
|
|
|
|
|
|
|
|
|
我们这一节先来看方式一,主动调度。
|
|
|
|
|
|
|
|
|
|
|
|
这里我找了几个代码片段。**第一个片段是Btrfs,等待一个写入**。[B](https://zh.wikipedia.org/wiki/Btrfs)[trfs](https://zh.wikipedia.org/wiki/Btrfs)(B-Tree)是一种文件系统,感兴趣你可以自己去了解一下。
|
|
|
|
|
|
|
|
|
|
|
|
这个片段可以看作写入块设备的一个典型场景。写入需要一段时间,这段时间用不上CPU,还不如主动让给其他进程。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static void btrfs_wait_for_no_snapshoting_writes(struct btrfs_root *root)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
do {
|
|
|
|
|
|
prepare_to_wait(&root->subv_writers->wait, &wait,
|
|
|
|
|
|
TASK_UNINTERRUPTIBLE);
|
|
|
|
|
|
writers = percpu_counter_sum(&root->subv_writers->counter);
|
|
|
|
|
|
if (writers)
|
|
|
|
|
|
schedule();
|
|
|
|
|
|
finish_wait(&root->subv_writers->wait, &wait);
|
|
|
|
|
|
} while (writers);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
另外一个例子是,**从Tap网络设备等待一个读取**。Tap网络设备是虚拟机使用的网络设备。当没有数据到来的时候,它也需要等待,所以也会选择把CPU让给其他进程。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static ssize_t tap_do_read(struct tap_queue *q,
|
|
|
|
|
|
struct iov_iter *to,
|
|
|
|
|
|
int noblock, struct sk_buff *skb)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
while (1) {
|
|
|
|
|
|
if (!noblock)
|
|
|
|
|
|
prepare_to_wait(sk_sleep(&q->sk), &wait,
|
|
|
|
|
|
TASK_INTERRUPTIBLE);
|
|
|
|
|
|
......
|
|
|
|
|
|
/* Nothing to read, let's sleep */
|
|
|
|
|
|
schedule();
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
你应该知道,计算机主要处理计算、网络、存储三个方面。计算主要是CPU和内存的合作;网络和存储则多是和外部设备的合作;在操作外部设备的时候,往往需要让出CPU,就像上面两段代码一样,选择调用schedule()函数。
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们就来看**schedule函数的调用过程**。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
asmlinkage __visible void __sched schedule(void)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct task_struct *tsk = current;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
sched_submit_work(tsk);
|
|
|
|
|
|
do {
|
|
|
|
|
|
preempt_disable();
|
|
|
|
|
|
__schedule(false);
|
|
|
|
|
|
sched_preempt_enable_no_resched();
|
|
|
|
|
|
} while (need_resched());
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这段代码的主要逻辑是在\_\_schedule函数中实现的。这个函数比较复杂,我们分几个部分来讲解。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static void __sched notrace __schedule(bool preempt)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct task_struct *prev, *next;
|
|
|
|
|
|
unsigned long *switch_count;
|
|
|
|
|
|
struct rq_flags rf;
|
|
|
|
|
|
struct rq *rq;
|
|
|
|
|
|
int cpu;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
cpu = smp_processor_id();
|
|
|
|
|
|
rq = cpu_rq(cpu);
|
|
|
|
|
|
prev = rq->curr;
|
|
|
|
|
|
......
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
首先,在当前的CPU上,我们取出任务队列rq。
|
|
|
|
|
|
|
|
|
|
|
|
task\_struct \*prev指向这个CPU的任务队列上面正在运行的那个进程curr。为啥是prev?因为一旦将来它被切换下来,那它就成了前任了。
|
|
|
|
|
|
|
|
|
|
|
|
接下来代码如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
next = pick_next_task(rq, prev, &rf);
|
|
|
|
|
|
clear_tsk_need_resched(prev);
|
|
|
|
|
|
clear_preempt_need_resched();
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
第二步,获取下一个任务,task\_struct \*next指向下一个任务,这就是**继任**。
|
|
|
|
|
|
|
|
|
|
|
|
pick\_next\_task的实现如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static inline struct task_struct *
|
|
|
|
|
|
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
|
|
|
|
|
|
{
|
|
|
|
|
|
const struct sched_class *class;
|
|
|
|
|
|
struct task_struct *p;
|
|
|
|
|
|
/*
|
|
|
|
|
|
* Optimization: we know that if all tasks are in the fair class we can call that function directly, but only if the @prev task wasn't of a higher scheduling class, because otherwise those loose the opportunity to pull in more work from other CPUs.
|
|
|
|
|
|
*/
|
|
|
|
|
|
if (likely((prev->sched_class == &idle_sched_class ||
|
|
|
|
|
|
prev->sched_class == &fair_sched_class) &&
|
|
|
|
|
|
rq->nr_running == rq->cfs.h_nr_running)) {
|
|
|
|
|
|
p = fair_sched_class.pick_next_task(rq, prev, rf);
|
|
|
|
|
|
if (unlikely(p == RETRY_TASK))
|
|
|
|
|
|
goto again;
|
|
|
|
|
|
/* Assumes fair_sched_class->next == idle_sched_class */
|
|
|
|
|
|
if (unlikely(!p))
|
|
|
|
|
|
p = idle_sched_class.pick_next_task(rq, prev, rf);
|
|
|
|
|
|
return p;
|
|
|
|
|
|
}
|
|
|
|
|
|
again:
|
|
|
|
|
|
for_each_class(class) {
|
|
|
|
|
|
p = class->pick_next_task(rq, prev, rf);
|
|
|
|
|
|
if (p) {
|
|
|
|
|
|
if (unlikely(p == RETRY_TASK))
|
|
|
|
|
|
goto again;
|
|
|
|
|
|
return p;
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
我们来看again这里,就是咱们上一节讲的依次调用调度类。但是这里有了一个优化,因为大部分进程是普通进程,所以大部分情况下会调用上面的逻辑,调用的就是fair\_sched\_class.pick\_next\_task。
|
|
|
|
|
|
|
|
|
|
|
|
根据上一节对于fair\_sched\_class的定义,它调用的是pick\_next\_task\_fair,代码如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static struct task_struct *
|
|
|
|
|
|
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct cfs_rq *cfs_rq = &rq->cfs;
|
|
|
|
|
|
struct sched_entity *se;
|
|
|
|
|
|
struct task_struct *p;
|
|
|
|
|
|
int new_tasks;
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
对于CFS调度类,取出相应的队列cfs\_rq,这就是我们上一节讲的那棵红黑树。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct sched_entity *curr = cfs_rq->curr;
|
|
|
|
|
|
if (curr) {
|
|
|
|
|
|
if (curr->on_rq)
|
|
|
|
|
|
update_curr(cfs_rq);
|
|
|
|
|
|
else
|
|
|
|
|
|
curr = NULL;
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
se = pick_next_entity(cfs_rq, curr);
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
取出当前正在运行的任务curr,如果依然是可运行的状态,也即处于进程就绪状态,则调用update\_curr更新vruntime。update\_curr咱们上一节就见过了,它会根据实际运行时间算出vruntime来。
|
|
|
|
|
|
|
|
|
|
|
|
接着,pick\_next\_entity从红黑树里面,取最左边的一个节点。这个函数的实现我们上一节也讲过了。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
p = task_of(se);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (prev != p) {
|
|
|
|
|
|
struct sched_entity *pse = &prev->se;
|
|
|
|
|
|
......
|
|
|
|
|
|
put_prev_entity(cfs_rq, pse);
|
|
|
|
|
|
set_next_entity(cfs_rq, se);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
return p
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
task\_of得到下一个调度实体对应的task\_struct,如果发现继任和前任不一样,这就说明有一个更需要运行的进程了,就需要更新红黑树了。前面前任的vruntime更新过了,put\_prev\_entity放回红黑树,会找到相应的位置,然后set\_next\_entity将继任者设为当前任务。
|
|
|
|
|
|
|
|
|
|
|
|
第三步,当选出的继任者和前任不同,就要进行上下文切换,继任者进程正式进入运行。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
if (likely(prev != next)) {
|
|
|
|
|
|
rq->nr_switches++;
|
|
|
|
|
|
rq->curr = next;
|
|
|
|
|
|
++*switch_count;
|
|
|
|
|
|
......
|
|
|
|
|
|
rq = context_switch(rq, prev, next, &rf);
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 进程上下文切换
|
|
|
|
|
|
|
|
|
|
|
|
上下文切换主要干两件事情,一是切换进程空间,也即虚拟内存;二是切换寄存器和CPU上下文。
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看context\_switch的实现。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/*
|
|
|
|
|
|
* context_switch - switch to the new MM and the new thread's register state.
|
|
|
|
|
|
*/
|
|
|
|
|
|
static __always_inline struct rq *
|
|
|
|
|
|
context_switch(struct rq *rq, struct task_struct *prev,
|
|
|
|
|
|
struct task_struct *next, struct rq_flags *rf)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct mm_struct *mm, *oldmm;
|
|
|
|
|
|
......
|
|
|
|
|
|
mm = next->mm;
|
|
|
|
|
|
oldmm = prev->active_mm;
|
|
|
|
|
|
......
|
|
|
|
|
|
switch_mm_irqs_off(oldmm, mm, next);
|
|
|
|
|
|
......
|
|
|
|
|
|
/* Here we just switch the register state and the stack. */
|
|
|
|
|
|
switch_to(prev, next, prev);
|
|
|
|
|
|
barrier();
|
|
|
|
|
|
return finish_task_switch(prev);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里首先是内存空间的切换,里面涉及内存管理的内容比较多。内存管理后面我们会有专门的章节来讲,这里你先知道有这么一回事就行了。
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们看switch\_to。它就是寄存器和栈的切换,它调用到了\_\_switch\_to\_asm。这是一段汇编代码,主要用于栈的切换。
|
|
|
|
|
|
|
|
|
|
|
|
对于32位操作系统来讲,切换的是栈顶指针esp。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/*
|
|
|
|
|
|
* %eax: prev task
|
|
|
|
|
|
* %edx: next task
|
|
|
|
|
|
*/
|
|
|
|
|
|
ENTRY(__switch_to_asm)
|
|
|
|
|
|
......
|
|
|
|
|
|
/* switch stack */
|
|
|
|
|
|
movl %esp, TASK_threadsp(%eax)
|
|
|
|
|
|
movl TASK_threadsp(%edx), %esp
|
|
|
|
|
|
......
|
|
|
|
|
|
jmp __switch_to
|
|
|
|
|
|
END(__switch_to_asm)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
对于64位操作系统来讲,切换的是栈顶指针rsp。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/*
|
|
|
|
|
|
* %rdi: prev task
|
|
|
|
|
|
* %rsi: next task
|
|
|
|
|
|
*/
|
|
|
|
|
|
ENTRY(__switch_to_asm)
|
|
|
|
|
|
......
|
|
|
|
|
|
/* switch stack */
|
|
|
|
|
|
movq %rsp, TASK_threadsp(%rdi)
|
|
|
|
|
|
movq TASK_threadsp(%rsi), %rsp
|
|
|
|
|
|
......
|
|
|
|
|
|
jmp __switch_to
|
|
|
|
|
|
END(__switch_to_asm)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
最终,都返回了\_\_switch\_to这个函数。这个函数对于32位和64位操作系统虽然有不同的实现,但里面做的事情是差不多的。所以我这里仅仅列出64位操作系统做的事情。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
__visible __notrace_funcgraph struct task_struct *
|
|
|
|
|
|
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct thread_struct *prev = &prev_p->thread;
|
|
|
|
|
|
struct thread_struct *next = &next_p->thread;
|
|
|
|
|
|
......
|
|
|
|
|
|
int cpu = smp_processor_id();
|
|
|
|
|
|
struct tss_struct *tss = &per_cpu(cpu_tss, cpu);
|
|
|
|
|
|
......
|
|
|
|
|
|
load_TLS(next, cpu);
|
|
|
|
|
|
......
|
|
|
|
|
|
this_cpu_write(current_task, next_p);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/* Reload esp0 and ss1. This changes current_thread_info(). */
|
|
|
|
|
|
load_sp0(tss, next);
|
|
|
|
|
|
......
|
|
|
|
|
|
return prev_p;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里面有一个Per CPU的结构体tss。这是个什么呢?
|
|
|
|
|
|
|
|
|
|
|
|
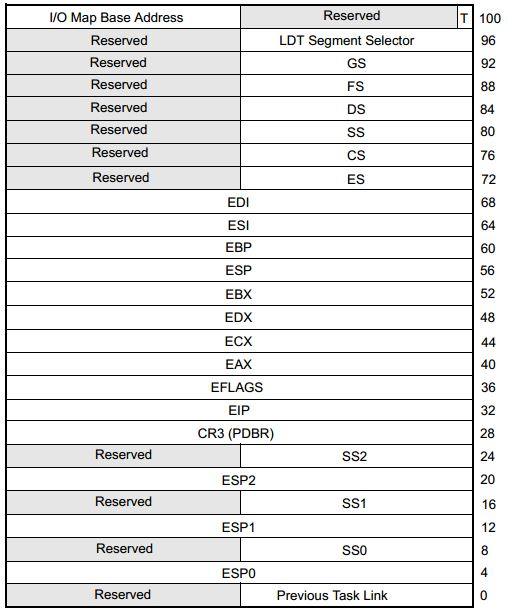
在x86体系结构中,提供了一种以硬件的方式进行进程切换的模式,对于每个进程,x86希望在内存里面维护一个TSS(Task State Segment,任务状态段)结构。这里面有所有的寄存器。
|
|
|
|
|
|
|
|
|
|
|
|
另外,还有一个特殊的寄存器TR(Task Register,任务寄存器),指向某个进程的TSS。更改TR的值,将会触发硬件保存CPU所有寄存器的值到当前进程的TSS中,然后从新进程的TSS中读出所有寄存器值,加载到CPU对应的寄存器中。
|
|
|
|
|
|
|
|
|
|
|
|
下图就是32位的TSS结构。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
图片来自Intel® 64 and IA-32 Architectures Software Developer’s Manual Combined Volumes
|
|
|
|
|
|
|
|
|
|
|
|
但是这样有个缺点。我们做进程切换的时候,没必要每个寄存器都切换,这样每个进程一个TSS,就需要全量保存,全量切换,动作太大了。
|
|
|
|
|
|
|
|
|
|
|
|
于是,Linux操作系统想了一个办法。还记得在系统初始化的时候,会调用cpu\_init吗?这里面会给每一个CPU关联一个TSS,然后将TR指向这个TSS,然后在操作系统的运行过程中,TR就不切换了,永远指向这个TSS。TSS用数据结构tss\_struct表示,在x86\_hw\_tss中可以看到和上图相应的结构。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
void cpu_init(void)
|
|
|
|
|
|
{
|
|
|
|
|
|
int cpu = smp_processor_id();
|
|
|
|
|
|
struct task_struct *curr = current;
|
|
|
|
|
|
struct tss_struct *t = &per_cpu(cpu_tss, cpu);
|
|
|
|
|
|
......
|
|
|
|
|
|
load_sp0(t, thread);
|
|
|
|
|
|
set_tss_desc(cpu, t);
|
|
|
|
|
|
load_TR_desc();
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
struct tss_struct {
|
|
|
|
|
|
/*
|
|
|
|
|
|
* The hardware state:
|
|
|
|
|
|
*/
|
|
|
|
|
|
struct x86_hw_tss x86_tss;
|
|
|
|
|
|
unsigned long io_bitmap[IO_BITMAP_LONGS + 1];
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在Linux中,真的参与进程切换的寄存器很少,主要的就是栈顶寄存器。
|
|
|
|
|
|
|
|
|
|
|
|
于是,在task\_struct里面,还有一个我们原来没有注意的成员变量thread。这里面保留了要切换进程的时候需要修改的寄存器。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/* CPU-specific state of this task: */
|
|
|
|
|
|
struct thread_struct thread;
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
所谓的进程切换,就是将某个进程的thread\_struct里面的寄存器的值,写入到CPU的TR指向的tss\_struct,对于CPU来讲,这就算是完成了切换。
|
|
|
|
|
|
|
|
|
|
|
|
例如\_\_switch\_to中的load\_sp0,就是将下一个进程的thread\_struct的sp0的值加载到tss\_struct里面去。
|
|
|
|
|
|
|
|
|
|
|
|
## 指令指针的保存与恢复
|
|
|
|
|
|
|
|
|
|
|
|
你是不是觉得,这样真的就完成切换了吗?是的,不信我们来**盘点**一下。
|
|
|
|
|
|
|
|
|
|
|
|
从进程A切换到进程B,用户栈要不要切换呢?当然要,其实早就已经切换了,就在切换内存空间的时候。每个进程的用户栈都是独立的,都在内存空间里面。
|
|
|
|
|
|
|
|
|
|
|
|
那内核栈呢?已经在\_\_switch\_to里面切换了,也就是将current\_task指向当前的task\_struct。里面的void \*stack指针,指向的就是当前的内核栈。
|
|
|
|
|
|
|
|
|
|
|
|
内核栈的栈顶指针呢?在\_\_switch\_to\_asm里面已经切换了栈顶指针,并且将栈顶指针在\_\_switch\_to加载到了TSS里面。
|
|
|
|
|
|
|
|
|
|
|
|
用户栈的栈顶指针呢?如果当前在内核里面的话,它当然是在内核栈顶部的pt\_regs结构里面呀。当从内核返回用户态运行的时候,pt\_regs里面有所有当时在用户态的时候运行的上下文信息,就可以开始运行了。
|
|
|
|
|
|
|
|
|
|
|
|
唯一让人不容易理解的是指令指针寄存器,它应该指向下一条指令的,那它是如何切换的呢?这里有点绕,请你仔细看。
|
|
|
|
|
|
|
|
|
|
|
|
这里我先明确一点,进程的调度都最终会调用到\_\_schedule函数。为了方便你记住,我姑且给它起个名字,就叫“**进程调度第一定律**”。后面我们会多次用到这个定律,你一定要记住。
|
|
|
|
|
|
|
|
|
|
|
|
我们用最前面的例子仔细分析这个过程。本来一个进程A在用户态是要写一个文件的,写文件的操作用户态没办法完成,就要通过系统调用到达内核态。在这个切换的过程中,用户态的指令指针寄存器是保存在pt\_regs里面的,到了内核态,就开始沿着写文件的逻辑一步一步执行,结果发现需要等待,于是就调用\_\_schedule函数。
|
|
|
|
|
|
|
|
|
|
|
|
这个时候,进程A在内核态的指令指针是指向\_\_schedule了。这里请记住,A进程的内核栈会保存这个\_\_schedule的调用,而且知道这是从btrfs\_wait\_for\_no\_snapshoting\_writes这个函数里面进去的。
|
|
|
|
|
|
|
|
|
|
|
|
\_\_schedule里面经过上面的层层调用,到达了context\_switch的最后三行指令(其中barrier语句是一个编译器指令,用于保证switch\_to和finish\_task\_switch的执行顺序,不会因为编译阶段优化而改变,这里咱们可以忽略它)。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
switch_to(prev, next, prev);
|
|
|
|
|
|
barrier();
|
|
|
|
|
|
return finish_task_switch(prev);
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
当进程A在内核里面执行switch\_to的时候,内核态的指令指针也是指向这一行的。但是在switch\_to里面,将寄存器和栈都切换到成了进程B的,唯一没有变的就是指令指针寄存器。当switch\_to返回的时候,指令指针寄存器指向了下一条语句finish\_task\_switch。
|
|
|
|
|
|
|
|
|
|
|
|
但这个时候的finish\_task\_switch已经不是进程A的finish\_task\_switch了,而是进程B的finish\_task\_switch了。
|
|
|
|
|
|
|
|
|
|
|
|
这样合理吗?你怎么知道进程B当时被切换下去的时候,执行到哪里了?恢复B进程执行的时候一定在这里呢?这时候就要用到咱的“进程调度第一定律”了。
|
|
|
|
|
|
|
|
|
|
|
|
当年B进程被别人切换走的时候,也是调用\_\_schedule,也是调用到switch\_to,被切换成为C进程的,所以,B进程当年的下一个指令也是finish\_task\_switch,这就说明指令指针指到这里是没有错的。
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们要从finish\_task\_switch完毕后,返回\_\_schedule的调用了。返回到哪里呢?按照函数返回的原理,当然是从内核栈里面去找,是返回到btrfs\_wait\_for\_no\_snapshoting\_writes吗?当然不是了,因为btrfs\_wait\_for\_no\_snapshoting\_writes是在A进程的内核栈里面的,它早就被切换走了,应该从B进程的内核栈里面找。
|
|
|
|
|
|
|
|
|
|
|
|
假设,B就是最前面例子里面调用tap\_do\_read读网卡的进程。它当年调用\_\_schedule的时候,是从tap\_do\_read这个函数调用进去的。
|
|
|
|
|
|
|
|
|
|
|
|
当然,B进程的内核栈里面放的是tap\_do\_read。于是,从\_\_schedule返回之后,当然是接着tap\_do\_read运行,然后在内核运行完毕后,返回用户态。这个时候,B进程内核栈的pt\_regs也保存了用户态的指令指针寄存器,就接着在用户态的下一条指令开始运行就可以了。
|
|
|
|
|
|
|
|
|
|
|
|
假设,我们只有一个CPU,从B切换到C,从C又切换到A。在C切换到A的时候,还是按照“进程调度第一定律”,C进程还是会调用\_\_schedule到达switch\_to,在里面切换成为A的内核栈,然后运行finish\_task\_switch。
|
|
|
|
|
|
|
|
|
|
|
|
这个时候运行的finish\_task\_switch,才是A进程的finish\_task\_switch。运行完毕从\_\_schedule返回的时候,从内核栈上才知道,当年是从btrfs\_wait\_for\_no\_snapshoting\_writes调用进去的,因而应该返回btrfs\_wait\_for\_no\_snapshoting\_writes继续执行,最后内核执行完毕返回用户态,同样恢复pt\_regs,恢复用户态的指令指针寄存器,从用户态接着运行。
|
|
|
|
|
|
|
|
|
|
|
|
到这里你是不是有点理解为什么switch\_to有三个参数呢?为啥有两个prev呢?其实我们从定义就可以看到。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#define switch_to(prev, next, last) \
|
|
|
|
|
|
do { \
|
|
|
|
|
|
prepare_switch_to(prev, next); \
|
|
|
|
|
|
\
|
|
|
|
|
|
((last) = __switch_to_asm((prev), (next))); \
|
|
|
|
|
|
} while (0)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在上面的例子中,A切换到B的时候,运行到\_\_switch\_to\_asm这一行的时候,是在A的内核栈上运行的,prev是A,next是B。但是,A执行完\_\_switch\_to\_asm之后就被切换走了,当C再次切换到A的时候,运行到\_\_switch\_to\_asm,是从C的内核栈运行的。这个时候,prev是C,next是A,但是\_\_switch\_to\_asm里面切换成为了A当时的内核栈。
|
|
|
|
|
|
|
|
|
|
|
|
还记得当年的场景“prev是A,next是B”,\_\_switch\_to\_asm里面return prev的时候,还没return的时候,prev这个变量里面放的还是C,因而它会把C放到返回结果中。但是,一旦return,就会弹出A当时的内核栈。这个时候,prev变量就变成了A,next变量就变成了B。这就还原了当年的场景,好在返回值里面的last还是C。
|
|
|
|
|
|
|
|
|
|
|
|
通过三个变量switch\_to(prev = A, next=B, last=C),A进程就明白了,我当时被切换走的时候,是切换成B,这次切换回来,是从C回来的。
|
|
|
|
|
|
|
|
|
|
|
|
## 总结时刻
|
|
|
|
|
|
|
|
|
|
|
|
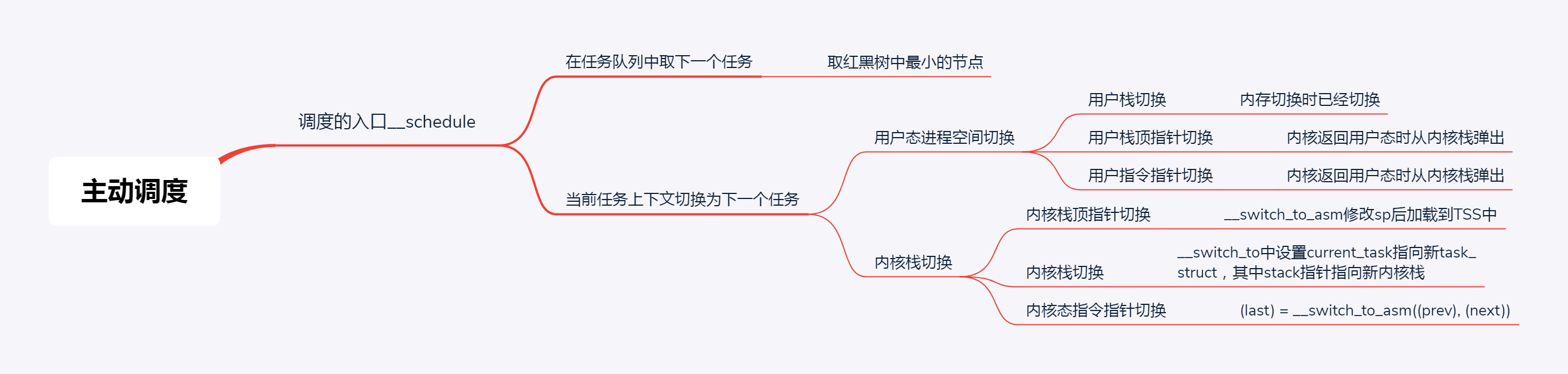
这一节我们讲主动调度的过程,也即一个运行中的进程主动调用\_\_schedule让出CPU。在\_\_schedule里面会做两件事情,第一是选取下一个进程,第二是进行上下文切换。而上下文切换又分用户态进程空间的切换和内核态的切换。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## 课堂练习
|
|
|
|
|
|
|
|
|
|
|
|
你知道应该用什么命令查看进程的运行时间和上下文切换次数吗?
|
|
|
|
|
|
|
|
|
|
|
|
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。
|
|
|
|
|
|
|