|
|
|
|
|
# 14 | 进程数据结构(下):项目多了就需要项目管理系统
|
|
|
|
|
|
|
|
|
|
|
|
上两节,我们解读了task\_struct的大部分的成员变量。这样一个任务执行的方方面面,都可以很好地管理起来,但是其中有一个问题我们没有谈。在程序执行过程中,一旦调用到系统调用,就需要进入内核继续执行。那如何将用户态的执行和内核态的执行串起来呢?
|
|
|
|
|
|
|
|
|
|
|
|
这就需要以下两个重要的成员变量:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct thread_info thread_info;
|
|
|
|
|
|
void *stack;
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 用户态函数栈
|
|
|
|
|
|
|
|
|
|
|
|
在用户态中,程序的执行往往是一个函数调用另一个函数。函数调用都是通过栈来进行的。我们前面大致讲过函数栈的原理,今天我们仔细分析一下。
|
|
|
|
|
|
|
|
|
|
|
|
函数调用其实也很简单。如果你去看汇编语言的代码,其实就是指令跳转,从代码的一个地方跳到另外一个地方。这里比较棘手的问题是,参数和返回地址应该怎么传递过去呢?
|
|
|
|
|
|
|
|
|
|
|
|
我们看函数的调用过程,A调用B、调用C、调用D,然后返回C、返回B、返回A,这是一个后进先出的过程。有没有觉得这个过程很熟悉?没错,咱们数据结构里学的栈,也是后进先出的,所以用栈保存这些最合适。
|
|
|
|
|
|
|
|
|
|
|
|
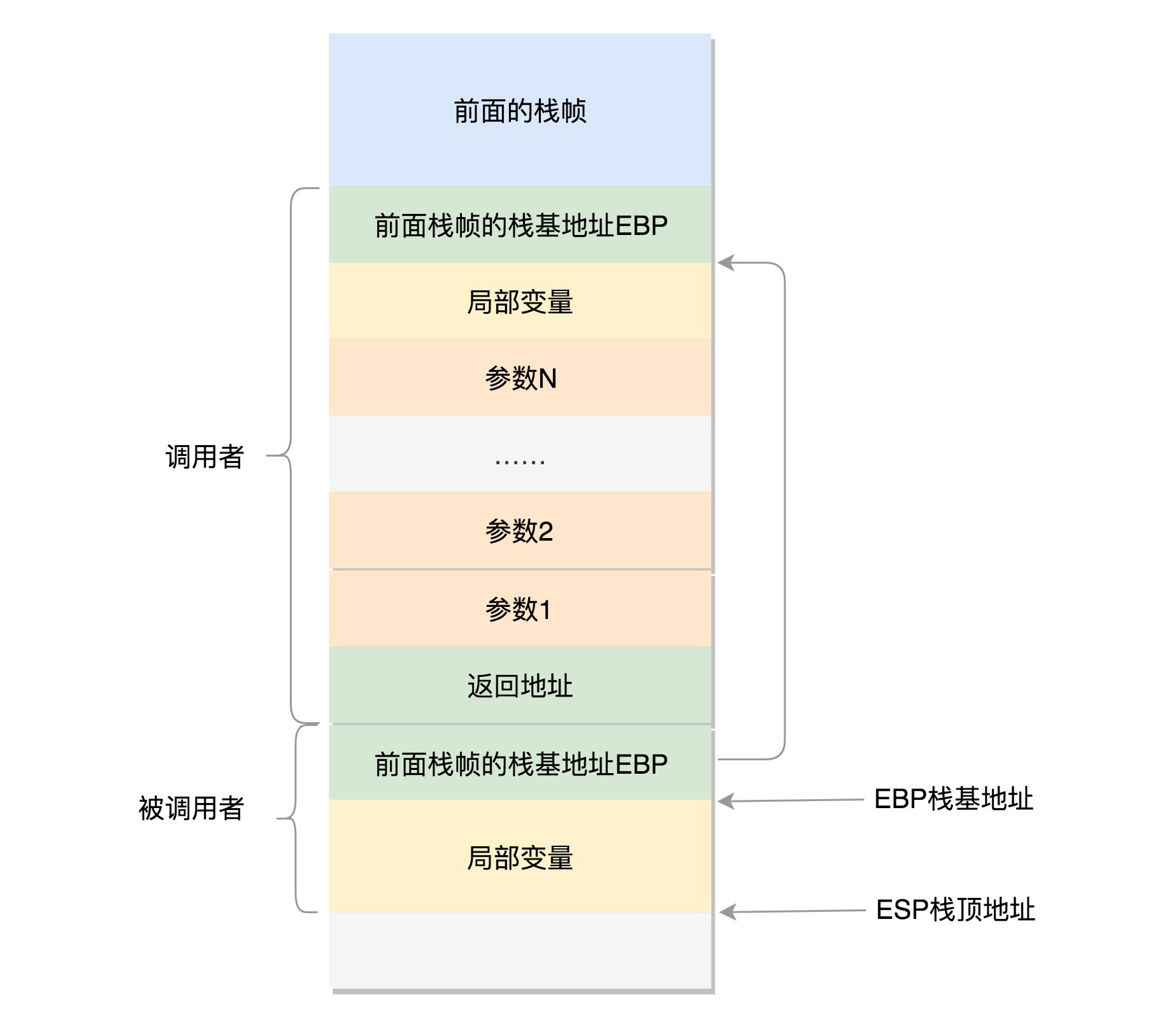
在进程的内存空间里面,栈是一个从高地址到低地址,往下增长的结构,也就是上面是栈底,下面是栈顶,入栈和出栈的操作都是从下面的栈顶开始的。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看32位操作系统的情况。在CPU里,**ESP**(Extended Stack Pointer)是栈顶指针寄存器,入栈操作Push和出栈操作Pop指令,会自动调整ESP的值。另外有一个寄存器**EBP**(Extended Base Pointer),是栈基地址指针寄存器,指向当前栈帧的最底部。
|
|
|
|
|
|
|
|
|
|
|
|
例如,A调用B,A的栈里面包含A函数的局部变量,然后是调用B的时候要传给它的参数,然后返回A的地址,这个地址也应该入栈,这就形成了A的栈帧。接下来就是B的栈帧部分了,先保存的是A栈帧的栈底位置,也就是EBP。因为在B函数里面获取A传进来的参数,就是通过这个指针获取的,接下来保存的是B的局部变量等等。
|
|
|
|
|
|
|
|
|
|
|
|
当B返回的时候,返回值会保存在EAX寄存器中,从栈中弹出返回地址,将指令跳转回去,参数也从栈中弹出,然后继续执行A。
|
|
|
|
|
|
|
|
|
|
|
|
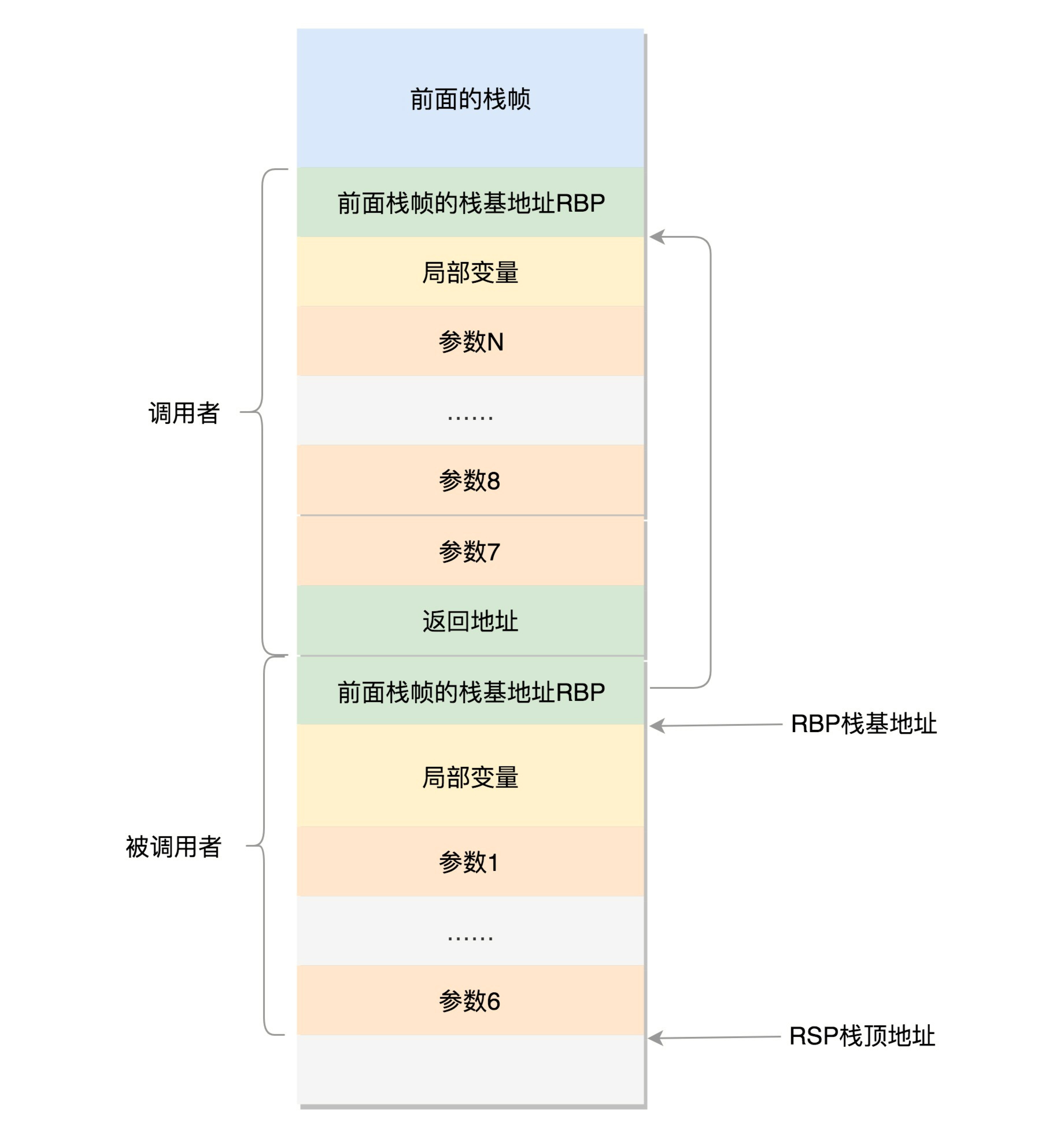
对于64位操作系统,模式多少有些不一样。因为64位操作系统的寄存器数目比较多。rax用于保存函数调用的返回结果。栈顶指针寄存器变成了rsp,指向栈顶位置。堆栈的Pop和Push操作会自动调整rsp,栈基指针寄存器变成了rbp,指向当前栈帧的起始位置。
|
|
|
|
|
|
|
|
|
|
|
|
改变比较多的是参数传递。rdi、rsi、rdx、rcx、r8、r9这6个寄存器,用于传递存储函数调用时的6个参数。如果超过6的时候,还是需要放到栈里面。
|
|
|
|
|
|
|
|
|
|
|
|
然而,前6个参数有时候需要进行寻址,但是如果在寄存器里面,是没有地址的,因而还是会放到栈里面,只不过放到栈里面的操作是被调用函数做的。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
以上的栈操作,都是在进程的内存空间里面进行的。
|
|
|
|
|
|
|
|
|
|
|
|
## 内核态函数栈
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们通过系统调用,从进程的内存空间到内核中了。内核中也有各种各样的函数调用来调用去的,也需要这样一个机制,这该怎么办呢?
|
|
|
|
|
|
|
|
|
|
|
|
这时候,上面的成员变量stack,也就是内核栈,就派上了用场。
|
|
|
|
|
|
|
|
|
|
|
|
Linux给每个task都分配了内核栈。在32位系统上arch/x86/include/asm/page\_32\_types.h,是这样定义的:一个PAGE\_SIZE是4K,左移一位就是乘以2,也就是8K。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#define THREAD_SIZE_ORDER 1
|
|
|
|
|
|
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
内核栈在64位系统上arch/x86/include/asm/page\_64\_types.h,是这样定义的:在PAGE\_SIZE的基础上左移两位,也即16K,并且要求起始地址必须是8192的整数倍。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#ifdef CONFIG_KASAN
|
|
|
|
|
|
#define KASAN_STACK_ORDER 1
|
|
|
|
|
|
#else
|
|
|
|
|
|
#define KASAN_STACK_ORDER 0
|
|
|
|
|
|
#endif
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
|
|
|
|
|
|
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
内核栈是一个非常特殊的结构,如下图所示:
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
这段空间的最低位置,是一个thread\_info结构。这个结构是对task\_struct结构的补充。因为task\_struct结构庞大但是通用,不同的体系结构就需要保存不同的东西,所以往往与体系结构有关的,都放在thread\_info里面。
|
|
|
|
|
|
|
|
|
|
|
|
在内核代码里面有这样一个union,将thread\_info和stack放在一起,在include/linux/sched.h文件中就有。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
union thread_union {
|
|
|
|
|
|
#ifndef CONFIG_THREAD_INFO_IN_TASK
|
|
|
|
|
|
struct thread_info thread_info;
|
|
|
|
|
|
#endif
|
|
|
|
|
|
unsigned long stack[THREAD_SIZE/sizeof(long)];
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这个union就是这样定义的,开头是thread\_info,后面是stack。
|
|
|
|
|
|
|
|
|
|
|
|
在内核栈的最高地址端,存放的是另一个结构pt\_regs,定义如下。其中,32位和64位的定义不一样。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#ifdef __i386__
|
|
|
|
|
|
struct pt_regs {
|
|
|
|
|
|
unsigned long bx;
|
|
|
|
|
|
unsigned long cx;
|
|
|
|
|
|
unsigned long dx;
|
|
|
|
|
|
unsigned long si;
|
|
|
|
|
|
unsigned long di;
|
|
|
|
|
|
unsigned long bp;
|
|
|
|
|
|
unsigned long ax;
|
|
|
|
|
|
unsigned long ds;
|
|
|
|
|
|
unsigned long es;
|
|
|
|
|
|
unsigned long fs;
|
|
|
|
|
|
unsigned long gs;
|
|
|
|
|
|
unsigned long orig_ax;
|
|
|
|
|
|
unsigned long ip;
|
|
|
|
|
|
unsigned long cs;
|
|
|
|
|
|
unsigned long flags;
|
|
|
|
|
|
unsigned long sp;
|
|
|
|
|
|
unsigned long ss;
|
|
|
|
|
|
};
|
|
|
|
|
|
#else
|
|
|
|
|
|
struct pt_regs {
|
|
|
|
|
|
unsigned long r15;
|
|
|
|
|
|
unsigned long r14;
|
|
|
|
|
|
unsigned long r13;
|
|
|
|
|
|
unsigned long r12;
|
|
|
|
|
|
unsigned long bp;
|
|
|
|
|
|
unsigned long bx;
|
|
|
|
|
|
unsigned long r11;
|
|
|
|
|
|
unsigned long r10;
|
|
|
|
|
|
unsigned long r9;
|
|
|
|
|
|
unsigned long r8;
|
|
|
|
|
|
unsigned long ax;
|
|
|
|
|
|
unsigned long cx;
|
|
|
|
|
|
unsigned long dx;
|
|
|
|
|
|
unsigned long si;
|
|
|
|
|
|
unsigned long di;
|
|
|
|
|
|
unsigned long orig_ax;
|
|
|
|
|
|
unsigned long ip;
|
|
|
|
|
|
unsigned long cs;
|
|
|
|
|
|
unsigned long flags;
|
|
|
|
|
|
unsigned long sp;
|
|
|
|
|
|
unsigned long ss;
|
|
|
|
|
|
/* top of stack page */
|
|
|
|
|
|
};
|
|
|
|
|
|
#endif
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
看到这个是不是很熟悉?咱们在讲系统调用的时候,已经多次见过这个结构。当系统调用从用户态到内核态的时候,首先要做的第一件事情,就是将用户态运行过程中的CPU上下文保存起来,其实主要就是保存在这个结构的寄存器变量里。这样当从内核系统调用返回的时候,才能让进程在刚才的地方接着运行下去。
|
|
|
|
|
|
|
|
|
|
|
|
如果我们对比系统调用那一节的内容,你会发现系统调用的时候,压栈的值的顺序和struct pt\_regs中寄存器定义的顺序是一样的。
|
|
|
|
|
|
|
|
|
|
|
|
在内核中,CPU的寄存器ESP或者RSP,已经指向内核栈的栈顶,在内核态里的调用都有和用户态相似的过程。
|
|
|
|
|
|
|
|
|
|
|
|
## 通过task\_struct找内核栈
|
|
|
|
|
|
|
|
|
|
|
|
如果有一个task\_struct的stack指针在手,你可以通过下面的函数找到这个线程内核栈:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static inline void *task_stack_page(const struct task_struct *task)
|
|
|
|
|
|
{
|
|
|
|
|
|
return task->stack;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
从task\_struct如何得到相应的pt\_regs呢?我们可以通过下面的函数:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/*
|
|
|
|
|
|
* TOP_OF_KERNEL_STACK_PADDING reserves 8 bytes on top of the ring0 stack.
|
|
|
|
|
|
* This is necessary to guarantee that the entire "struct pt_regs"
|
|
|
|
|
|
* is accessible even if the CPU haven't stored the SS/ESP registers
|
|
|
|
|
|
* on the stack (interrupt gate does not save these registers
|
|
|
|
|
|
* when switching to the same priv ring).
|
|
|
|
|
|
* Therefore beware: accessing the ss/esp fields of the
|
|
|
|
|
|
* "struct pt_regs" is possible, but they may contain the
|
|
|
|
|
|
* completely wrong values.
|
|
|
|
|
|
*/
|
|
|
|
|
|
#define task_pt_regs(task) \
|
|
|
|
|
|
({ \
|
|
|
|
|
|
unsigned long __ptr = (unsigned long)task_stack_page(task); \
|
|
|
|
|
|
__ptr += THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING; \
|
|
|
|
|
|
((struct pt_regs *)__ptr) - 1; \
|
|
|
|
|
|
})
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
你会发现,这是先从task\_struct找到内核栈的开始位置。然后这个位置加上THREAD\_SIZE就到了最后的位置,然后转换为struct pt\_regs,再减一,就相当于减少了一个pt\_regs的位置,就到了这个结构的首地址。
|
|
|
|
|
|
|
|
|
|
|
|
这里面有一个TOP\_OF\_KERNEL\_STACK\_PADDING,这个的定义如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#ifdef CONFIG_X86_32
|
|
|
|
|
|
# ifdef CONFIG_VM86
|
|
|
|
|
|
# define TOP_OF_KERNEL_STACK_PADDING 16
|
|
|
|
|
|
# else
|
|
|
|
|
|
# define TOP_OF_KERNEL_STACK_PADDING 8
|
|
|
|
|
|
# endif
|
|
|
|
|
|
#else
|
|
|
|
|
|
# define TOP_OF_KERNEL_STACK_PADDING 0
|
|
|
|
|
|
#endif
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
也就是说,32位机器上是8,其他是0。这是为什么呢?因为压栈pt\_regs有两种情况。我们知道,CPU用ring来区分权限,从而Linux可以区分内核态和用户态。
|
|
|
|
|
|
|
|
|
|
|
|
因此,第一种情况,我们拿涉及从用户态到内核态的变化的系统调用来说。因为涉及权限的改变,会压栈保存SS、ESP寄存器的,这两个寄存器共占用8个byte。
|
|
|
|
|
|
|
|
|
|
|
|
另一种情况是,不涉及权限的变化,就不会压栈这8个byte。这样就会使得两种情况不兼容。如果没有压栈还访问,就会报错,所以还不如预留在这里,保证安全。在64位上,修改了这个问题,变成了定长的。
|
|
|
|
|
|
|
|
|
|
|
|
好了,现在如果你task\_struct在手,就能够轻松得到内核栈和内核寄存器。
|
|
|
|
|
|
|
|
|
|
|
|
## 通过内核栈找task\_struct
|
|
|
|
|
|
|
|
|
|
|
|
那如果一个当前在某个CPU上执行的进程,想知道自己的task\_struct在哪里,又该怎么办呢?
|
|
|
|
|
|
|
|
|
|
|
|
这个艰巨的任务要交给thread\_info这个结构。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct thread_info {
|
|
|
|
|
|
struct task_struct *task; /* main task structure */
|
|
|
|
|
|
__u32 flags; /* low level flags */
|
|
|
|
|
|
__u32 status; /* thread synchronous flags */
|
|
|
|
|
|
__u32 cpu; /* current CPU */
|
|
|
|
|
|
mm_segment_t addr_limit;
|
|
|
|
|
|
unsigned int sig_on_uaccess_error:1;
|
|
|
|
|
|
unsigned int uaccess_err:1; /* uaccess failed */
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里面有个成员变量task指向task\_struct,所以我们常用current\_thread\_info()->task来获取task\_struct。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static inline struct thread_info *current_thread_info(void)
|
|
|
|
|
|
{
|
|
|
|
|
|
return (struct thread_info *)(current_top_of_stack() - THREAD_SIZE);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
而thread\_info的位置就是内核栈的最高位置,减去THREAD\_SIZE,就到了thread\_info的起始地址。
|
|
|
|
|
|
|
|
|
|
|
|
但是现在变成这样了,只剩下一个flags。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct thread_info {
|
|
|
|
|
|
unsigned long flags; /* low level flags */
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
那这时候怎么获取当前运行中的task\_struct呢?current\_thread\_info有了新的实现方式。
|
|
|
|
|
|
|
|
|
|
|
|
在include/linux/thread\_info.h中定义了current\_thread\_info。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#include <asm/current.h>
|
|
|
|
|
|
#define current_thread_info() ((struct thread_info *)current)
|
|
|
|
|
|
#endif
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
那current又是什么呢?在arch/x86/include/asm/current.h中定义了。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct task_struct;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DECLARE_PER_CPU(struct task_struct *, current_task);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
static __always_inline struct task_struct *get_current(void)
|
|
|
|
|
|
{
|
|
|
|
|
|
return this_cpu_read_stable(current_task);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#define current get_current
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
到这里,你会发现,新的机制里面,每个CPU运行的task\_struct不通过thread\_info获取了,而是直接放在Per CPU 变量里面了。
|
|
|
|
|
|
|
|
|
|
|
|
多核情况下,CPU是同时运行的,但是它们共同使用其他的硬件资源的时候,我们需要解决多个CPU之间的同步问题。
|
|
|
|
|
|
|
|
|
|
|
|
Per CPU变量是内核中一种重要的同步机制。顾名思义,Per CPU变量就是为每个CPU构造一个变量的副本,这样多个CPU各自操作自己的副本,互不干涉。比如,当前进程的变量current\_task就被声明为Per CPU变量。
|
|
|
|
|
|
|
|
|
|
|
|
要使用Per CPU变量,首先要声明这个变量,在arch/x86/include/asm/current.h中有:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
DECLARE_PER_CPU(struct task_struct *, current_task);
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
然后是定义这个变量,在arch/x86/kernel/cpu/common.c中有:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
DEFINE_PER_CPU(struct task_struct *, current_task) = &init_task;
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
也就是说,系统刚刚初始化的时候,current\_task都指向init\_task。
|
|
|
|
|
|
|
|
|
|
|
|
当某个CPU上的进程进行切换的时候,current\_task被修改为将要切换到的目标进程。例如,进程切换函数\_\_switch\_to就会改变current\_task。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
__visible __notrace_funcgraph struct task_struct *
|
|
|
|
|
|
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
this_cpu_write(current_task, next_p);
|
|
|
|
|
|
......
|
|
|
|
|
|
return prev_p;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
当要获取当前的运行中的task\_struct的时候,就需要调用this\_cpu\_read\_stable进行读取。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#define this_cpu_read_stable(var) percpu_stable_op("mov", var)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
好了,现在如果你是一个进程,正在某个CPU上运行,就能够轻松得到task\_struct了。
|
|
|
|
|
|
|
|
|
|
|
|
## 总结时刻
|
|
|
|
|
|
|
|
|
|
|
|
这一节虽然只介绍了内核栈,但是内容更加重要。如果说task\_struct的其他成员变量都是和进程管理有关的,内核栈是和进程运行有关系的。
|
|
|
|
|
|
|
|
|
|
|
|
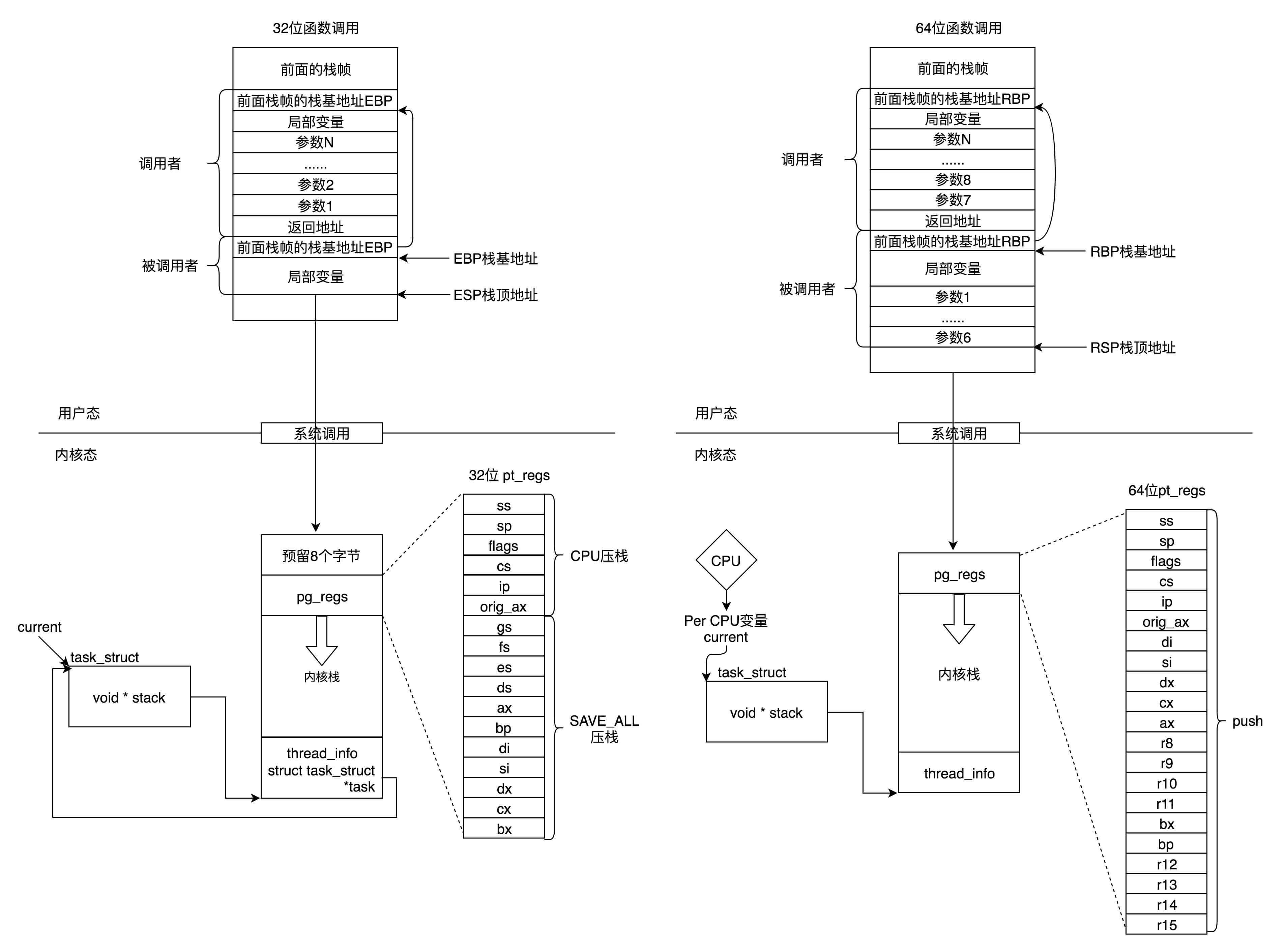
我这里画了一张图总结一下32位和64位的工作模式,左边是32位的,右边是64位的。
|
|
|
|
|
|
|
|
|
|
|
|
* 在用户态,应用程序进行了至少一次函数调用。32位和64的传递参数的方式稍有不同,32位的就是用函数栈,64位的前6个参数用寄存器,其他的用函数栈。
|
|
|
|
|
|
|
|
|
|
|
|
* 在内核态,32位和64位都使用内核栈,格式也稍有不同,主要集中在pt\_regs结构上。
|
|
|
|
|
|
|
|
|
|
|
|
* 在内核态,32位和64位的内核栈和task\_struct的关联关系不同。32位主要靠thread\_info,64位主要靠Per-CPU变量。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## 课堂练习
|
|
|
|
|
|
|
|
|
|
|
|
这一节讲函数调用的时候,我们讲了函数栈的工作模式。请你写一个程序,然后编译为汇编语言,打开看一下,函数栈是如何起作用的。
|
|
|
|
|
|
|
|
|
|
|
|
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|