|
|
|
|
|
# 35 | 块设备(下):如何建立代理商销售模式?
|
|
|
|
|
|
|
|
|
|
|
|
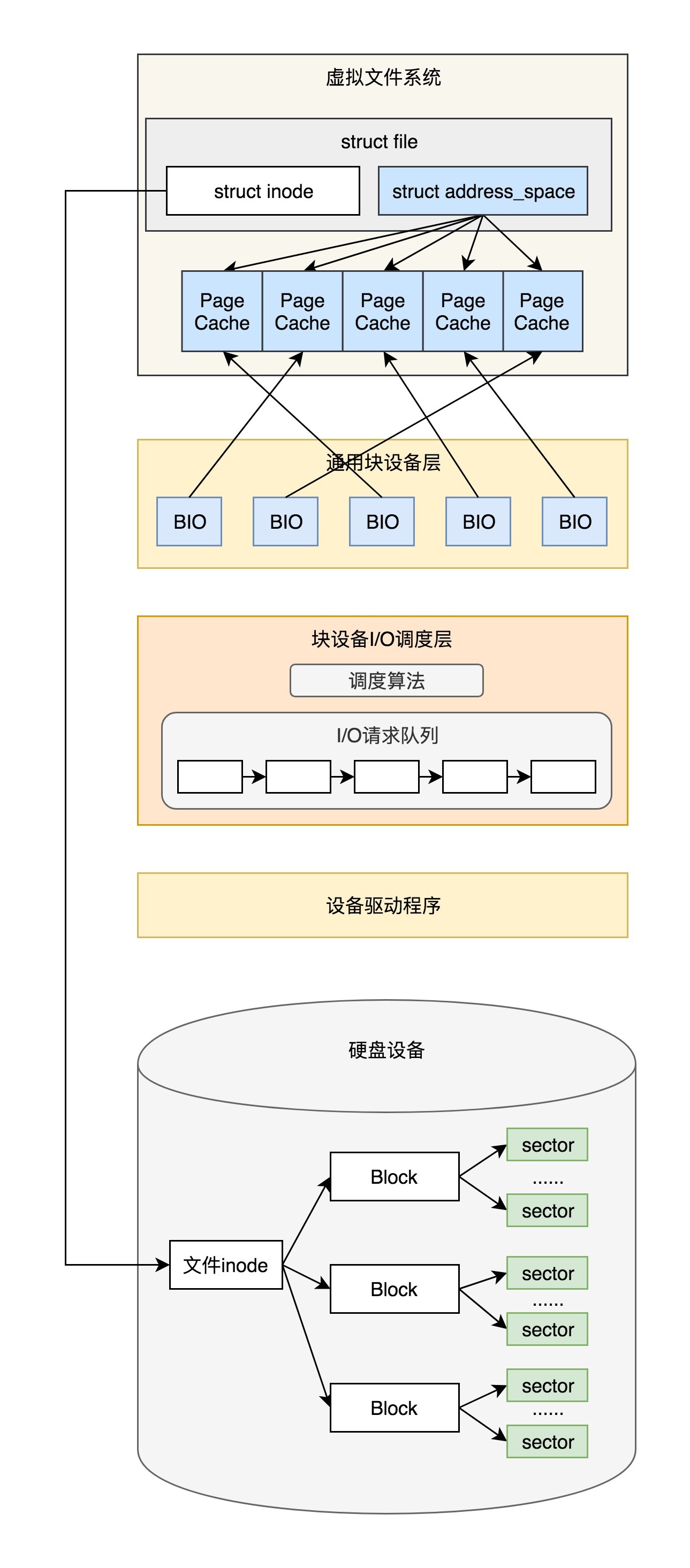
在[文件系统](https://time.geekbang.org/column/article/97876)那一节,我们讲了文件的写入,到了设备驱动这一层,就没有再往下分析。上一节我们又讲了mount一个块设备,将block\_device信息放到了ext4文件系统的super\_block里面,有了这些基础,是时候把整个写入的故事串起来了。
|
|
|
|
|
|
|
|
|
|
|
|
还记得咱们在文件系统那一节分析写入流程的时候,对于ext4文件系统,最后调用的是ext4\_file\_write\_iter,它将I/O的调用分成两种情况:
|
|
|
|
|
|
|
|
|
|
|
|
第一是**直接I/O**。最终我们调用的是generic\_file\_direct\_write,这里调用的是mapping->a\_ops->direct\_IO,实际调用的是ext4\_direct\_IO,往设备层写入数据。
|
|
|
|
|
|
|
|
|
|
|
|
第二种是**缓存I/O**。最终我们会将数据从应用拷贝到内存缓存中,但是这个时候,并不执行真正的I/O操作。它们只将整个页或其中部分标记为脏。写操作由一个timer触发,那个时候,才调用wb\_workfn往硬盘写入页面。
|
|
|
|
|
|
|
|
|
|
|
|
接下来的调用链为:wb\_workfn->wb\_do\_writeback->wb\_writeback->writeback\_sb\_inodes->\_\_writeback\_single\_inode->do\_writepages。在do\_writepages中,我们要调用mapping->a\_ops->writepages,但实际调用的是ext4\_writepages,往设备层写入数据。
|
|
|
|
|
|
|
|
|
|
|
|
这一节,我们就沿着这两种情况分析下去。
|
|
|
|
|
|
|
|
|
|
|
|
## 直接I/O如何访问块设备?
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看第一种情况,直接I/O调用到ext4\_direct\_IO。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static ssize_t ext4_direct_IO(struct kiocb *iocb, struct iov_iter *iter)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct file *file = iocb->ki_filp;
|
|
|
|
|
|
struct inode *inode = file->f_mapping->host;
|
|
|
|
|
|
size_t count = iov_iter_count(iter);
|
|
|
|
|
|
loff_t offset = iocb->ki_pos;
|
|
|
|
|
|
ssize_t ret;
|
|
|
|
|
|
......
|
|
|
|
|
|
ret = ext4_direct_IO_write(iocb, iter);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
static ssize_t ext4_direct_IO_write(struct kiocb *iocb, struct iov_iter *iter)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct file *file = iocb->ki_filp;
|
|
|
|
|
|
struct inode *inode = file->f_mapping->host;
|
|
|
|
|
|
struct ext4_inode_info *ei = EXT4_I(inode);
|
|
|
|
|
|
ssize_t ret;
|
|
|
|
|
|
loff_t offset = iocb->ki_pos;
|
|
|
|
|
|
size_t count = iov_iter_count(iter);
|
|
|
|
|
|
......
|
|
|
|
|
|
ret = __blockdev_direct_IO(iocb, inode, inode->i_sb->s_bdev, iter,
|
|
|
|
|
|
get_block_func, ext4_end_io_dio, NULL,
|
|
|
|
|
|
dio_flags);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
……
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在ext4\_direct\_IO\_write调用\_\_blockdev\_direct\_IO,有个参数你需要特别注意一下,那就是inode->i\_sb->s\_bdev。通过当前文件的inode,我们可以得到super\_block。这个super\_block中的s\_bdev,就是咱们上一节填进去的那个block\_device。
|
|
|
|
|
|
|
|
|
|
|
|
\_\_blockdev\_direct\_IO会调用do\_blockdev\_direct\_IO,在这里面我们要准备一个struct dio结构和struct dio\_submit结构,用来描述将要发生的写入请求。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static inline ssize_t
|
|
|
|
|
|
do_blockdev_direct_IO(struct kiocb *iocb, struct inode *inode,
|
|
|
|
|
|
struct block_device *bdev, struct iov_iter *iter,
|
|
|
|
|
|
get_block_t get_block, dio_iodone_t end_io,
|
|
|
|
|
|
dio_submit_t submit_io, int flags)
|
|
|
|
|
|
{
|
|
|
|
|
|
unsigned i_blkbits = ACCESS_ONCE(inode->i_blkbits);
|
|
|
|
|
|
unsigned blkbits = i_blkbits;
|
|
|
|
|
|
unsigned blocksize_mask = (1 << blkbits) - 1;
|
|
|
|
|
|
ssize_t retval = -EINVAL;
|
|
|
|
|
|
size_t count = iov_iter_count(iter);
|
|
|
|
|
|
loff_t offset = iocb->ki_pos;
|
|
|
|
|
|
loff_t end = offset + count;
|
|
|
|
|
|
struct dio *dio;
|
|
|
|
|
|
struct dio_submit sdio = { 0, };
|
|
|
|
|
|
struct buffer_head map_bh = { 0, };
|
|
|
|
|
|
......
|
|
|
|
|
|
dio = kmem_cache_alloc(dio_cache, GFP_KERNEL);
|
|
|
|
|
|
dio->flags = flags;
|
|
|
|
|
|
dio->i_size = i_size_read(inode);
|
|
|
|
|
|
dio->inode = inode;
|
|
|
|
|
|
if (iov_iter_rw(iter) == WRITE) {
|
|
|
|
|
|
dio->op = REQ_OP_WRITE;
|
|
|
|
|
|
dio->op_flags = REQ_SYNC | REQ_IDLE;
|
|
|
|
|
|
if (iocb->ki_flags & IOCB_NOWAIT)
|
|
|
|
|
|
dio->op_flags |= REQ_NOWAIT;
|
|
|
|
|
|
} else {
|
|
|
|
|
|
dio->op = REQ_OP_READ;
|
|
|
|
|
|
}
|
|
|
|
|
|
sdio.blkbits = blkbits;
|
|
|
|
|
|
sdio.blkfactor = i_blkbits - blkbits;
|
|
|
|
|
|
sdio.block_in_file = offset >> blkbits;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
sdio.get_block = get_block;
|
|
|
|
|
|
dio->end_io = end_io;
|
|
|
|
|
|
sdio.submit_io = submit_io;
|
|
|
|
|
|
sdio.final_block_in_bio = -1;
|
|
|
|
|
|
sdio.next_block_for_io = -1;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
dio->iocb = iocb;
|
|
|
|
|
|
dio->refcount = 1;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
sdio.iter = iter;
|
|
|
|
|
|
sdio.final_block_in_request =
|
|
|
|
|
|
(offset + iov_iter_count(iter)) >> blkbits;
|
|
|
|
|
|
......
|
|
|
|
|
|
sdio.pages_in_io += iov_iter_npages(iter, INT_MAX);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
retval = do_direct_IO(dio, &sdio, &map_bh);
|
|
|
|
|
|
.....
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
do\_direct\_IO里面有两层循环,第一层循环是依次处理这次要写入的所有块。对于每一块,取出对应的内存中的页page,在这一块中,有写入的起始地址from和终止地址to,所以,第二层循环就是依次处理from到to的数据,调用submit\_page\_section,提交到块设备层进行写入。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int do_direct_IO(struct dio *dio, struct dio_submit *sdio,
|
|
|
|
|
|
struct buffer_head *map_bh)
|
|
|
|
|
|
{
|
|
|
|
|
|
const unsigned blkbits = sdio->blkbits;
|
|
|
|
|
|
const unsigned i_blkbits = blkbits + sdio->blkfactor;
|
|
|
|
|
|
int ret = 0;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
while (sdio->block_in_file < sdio->final_block_in_request) {
|
|
|
|
|
|
struct page *page;
|
|
|
|
|
|
size_t from, to;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
page = dio_get_page(dio, sdio);
|
|
|
|
|
|
from = sdio->head ? 0 : sdio->from;
|
|
|
|
|
|
to = (sdio->head == sdio->tail - 1) ? sdio->to : PAGE_SIZE;
|
|
|
|
|
|
sdio->head++;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
while (from < to) {
|
|
|
|
|
|
unsigned this_chunk_bytes; /* # of bytes mapped */
|
|
|
|
|
|
unsigned this_chunk_blocks; /* # of blocks */
|
|
|
|
|
|
......
|
|
|
|
|
|
ret = submit_page_section(dio, sdio, page,
|
|
|
|
|
|
from,
|
|
|
|
|
|
this_chunk_bytes,
|
|
|
|
|
|
sdio->next_block_for_io,
|
|
|
|
|
|
map_bh);
|
|
|
|
|
|
......
|
|
|
|
|
|
sdio->next_block_for_io += this_chunk_blocks;
|
|
|
|
|
|
sdio->block_in_file += this_chunk_blocks;
|
|
|
|
|
|
from += this_chunk_bytes;
|
|
|
|
|
|
dio->result += this_chunk_bytes;
|
|
|
|
|
|
sdio->blocks_available -= this_chunk_blocks;
|
|
|
|
|
|
if (sdio->block_in_file == sdio->final_block_in_request)
|
|
|
|
|
|
break;
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
submit\_page\_section会调用dio\_bio\_submit,进而调用submit\_bio向块设备层提交数据。其中,参数struct bio是将数据传给块设备的通用传输对象。定义如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/**
|
|
|
|
|
|
* submit_bio - submit a bio to the block device layer for I/O
|
|
|
|
|
|
* @bio: The &struct bio which describes the I/O
|
|
|
|
|
|
*/
|
|
|
|
|
|
blk_qc_t submit_bio(struct bio *bio)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
return generic_make_request(bio);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 缓存I/O如何访问块设备?
|
|
|
|
|
|
|
|
|
|
|
|
我们再来看第二种情况,缓存I/O调用到ext4\_writepages。这个函数比较长,我们这里只截取最重要的部分来讲解。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int ext4_writepages(struct address_space *mapping,
|
|
|
|
|
|
struct writeback_control *wbc)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
struct mpage_da_data mpd;
|
|
|
|
|
|
struct inode *inode = mapping->host;
|
|
|
|
|
|
struct ext4_sb_info *sbi = EXT4_SB(mapping->host->i_sb);
|
|
|
|
|
|
......
|
|
|
|
|
|
mpd.do_map = 0;
|
|
|
|
|
|
mpd.io_submit.io_end = ext4_init_io_end(inode, GFP_KERNEL);
|
|
|
|
|
|
ret = mpage_prepare_extent_to_map(&mpd);
|
|
|
|
|
|
/* Submit prepared bio */
|
|
|
|
|
|
ext4_io_submit(&mpd.io_submit);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里比较重要的一个数据结构是struct mpage\_da\_data。这里面有文件的inode、要写入的页的偏移量,还有一个重要的struct ext4\_io\_submit,里面有通用传输对象bio。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct mpage_da_data {
|
|
|
|
|
|
struct inode *inode;
|
|
|
|
|
|
......
|
|
|
|
|
|
pgoff_t first_page; /* The first page to write */
|
|
|
|
|
|
pgoff_t next_page; /* Current page to examine */
|
|
|
|
|
|
pgoff_t last_page; /* Last page to examine */
|
|
|
|
|
|
struct ext4_map_blocks map;
|
|
|
|
|
|
struct ext4_io_submit io_submit; /* IO submission data */
|
|
|
|
|
|
unsigned int do_map:1;
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
struct ext4_io_submit {
|
|
|
|
|
|
......
|
|
|
|
|
|
struct bio *io_bio;
|
|
|
|
|
|
ext4_io_end_t *io_end;
|
|
|
|
|
|
sector_t io_next_block;
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在ext4\_writepages中,mpage\_prepare\_extent\_to\_map用于初始化这个struct mpage\_da\_data结构。接下来的调用链为:mpage\_prepare\_extent\_to\_map->mpage\_process\_page\_bufs->mpage\_submit\_page->ext4\_bio\_write\_page->io\_submit\_add\_bh。
|
|
|
|
|
|
|
|
|
|
|
|
在io\_submit\_add\_bh中,此时的bio还是空的,因而我们要调用io\_submit\_init\_bio,初始化bio。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int io_submit_init_bio(struct ext4_io_submit *io,
|
|
|
|
|
|
struct buffer_head *bh)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct bio *bio;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
bio = bio_alloc(GFP_NOIO, BIO_MAX_PAGES);
|
|
|
|
|
|
if (!bio)
|
|
|
|
|
|
return -ENOMEM;
|
|
|
|
|
|
wbc_init_bio(io->io_wbc, bio);
|
|
|
|
|
|
bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9);
|
|
|
|
|
|
bio->bi_bdev = bh->b_bdev;
|
|
|
|
|
|
bio->bi_end_io = ext4_end_bio;
|
|
|
|
|
|
bio->bi_private = ext4_get_io_end(io->io_end);
|
|
|
|
|
|
io->io_bio = bio;
|
|
|
|
|
|
io->io_next_block = bh->b_blocknr;
|
|
|
|
|
|
return 0;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
我们再回到ext4\_writepages中。在bio初始化完之后,我们要调用ext4\_io\_submit,提交I/O。在这里我们又是调用submit\_bio,向块设备层传输数据。ext4\_io\_submit的实现如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
void ext4_io_submit(struct ext4_io_submit *io)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct bio *bio = io->io_bio;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (bio) {
|
|
|
|
|
|
int io_op_flags = io->io_wbc->sync_mode == WB_SYNC_ALL ?
|
|
|
|
|
|
REQ_SYNC : 0;
|
|
|
|
|
|
io->io_bio->bi_write_hint = io->io_end->inode->i_write_hint;
|
|
|
|
|
|
bio_set_op_attrs(io->io_bio, REQ_OP_WRITE, io_op_flags);
|
|
|
|
|
|
submit_bio(io->io_bio);
|
|
|
|
|
|
}
|
|
|
|
|
|
io->io_bio = NULL;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 如何向块设备层提交请求?
|
|
|
|
|
|
|
|
|
|
|
|
既然不管是直接I/O,还是缓存I/O,最后都到了submit\_bio里面,那我们就来重点分析一下它。
|
|
|
|
|
|
|
|
|
|
|
|
submit\_bio会调用generic\_make\_request。代码如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
blk_qc_t generic_make_request(struct bio *bio)
|
|
|
|
|
|
{
|
|
|
|
|
|
/*
|
|
|
|
|
|
* bio_list_on_stack[0] contains bios submitted by the current
|
|
|
|
|
|
* make_request_fn.
|
|
|
|
|
|
* bio_list_on_stack[1] contains bios that were submitted before
|
|
|
|
|
|
* the current make_request_fn, but that haven't been processed
|
|
|
|
|
|
* yet.
|
|
|
|
|
|
*/
|
|
|
|
|
|
struct bio_list bio_list_on_stack[2];
|
|
|
|
|
|
blk_qc_t ret = BLK_QC_T_NONE;
|
|
|
|
|
|
......
|
|
|
|
|
|
if (current->bio_list) {
|
|
|
|
|
|
bio_list_add(¤t->bio_list[0], bio);
|
|
|
|
|
|
goto out;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
bio_list_init(&bio_list_on_stack[0]);
|
|
|
|
|
|
current->bio_list = bio_list_on_stack;
|
|
|
|
|
|
do {
|
|
|
|
|
|
struct request_queue *q = bdev_get_queue(bio->bi_bdev);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (likely(blk_queue_enter(q, bio->bi_opf & REQ_NOWAIT) == 0)) {
|
|
|
|
|
|
struct bio_list lower, same;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/* Create a fresh bio_list for all subordinate requests */
|
|
|
|
|
|
bio_list_on_stack[1] = bio_list_on_stack[0];
|
|
|
|
|
|
bio_list_init(&bio_list_on_stack[0]);
|
|
|
|
|
|
ret = q->make_request_fn(q, bio);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
blk_queue_exit(q);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/* sort new bios into those for a lower level
|
|
|
|
|
|
* and those for the same level
|
|
|
|
|
|
*/
|
|
|
|
|
|
bio_list_init(&lower);
|
|
|
|
|
|
bio_list_init(&same);
|
|
|
|
|
|
while ((bio = bio_list_pop(&bio_list_on_stack[0])) != NULL)
|
|
|
|
|
|
if (q == bdev_get_queue(bio->bi_bdev))
|
|
|
|
|
|
bio_list_add(&same, bio);
|
|
|
|
|
|
else
|
|
|
|
|
|
bio_list_add(&lower, bio);
|
|
|
|
|
|
/* now assemble so we handle the lowest level first */
|
|
|
|
|
|
bio_list_merge(&bio_list_on_stack[0], &lower);
|
|
|
|
|
|
bio_list_merge(&bio_list_on_stack[0], &same);
|
|
|
|
|
|
bio_list_merge(&bio_list_on_stack[0], &bio_list_on_stack[1]);
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
bio = bio_list_pop(&bio_list_on_stack[0]);
|
|
|
|
|
|
} while (bio);
|
|
|
|
|
|
current->bio_list = NULL; /* deactivate */
|
|
|
|
|
|
out:
|
|
|
|
|
|
return ret;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里的逻辑有点复杂,我们先来看大的逻辑。在do-while中,我们先是获取一个请求队列request\_queue,然后调用这个队列的make\_request\_fn函数。
|
|
|
|
|
|
|
|
|
|
|
|
### 块设备队列结构
|
|
|
|
|
|
|
|
|
|
|
|
如果再来看struct block\_device结构和struct gendisk结构,我们会发现,每个块设备都有一个请求队列struct request\_queue,用于处理上层发来的请求。
|
|
|
|
|
|
|
|
|
|
|
|
在每个块设备的驱动程序初始化的时候,会生成一个request\_queue。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct request_queue {
|
|
|
|
|
|
/*
|
|
|
|
|
|
* Together with queue_head for cacheline sharing
|
|
|
|
|
|
*/
|
|
|
|
|
|
struct list_head queue_head;
|
|
|
|
|
|
struct request *last_merge;
|
|
|
|
|
|
struct elevator_queue *elevator;
|
|
|
|
|
|
......
|
|
|
|
|
|
request_fn_proc *request_fn;
|
|
|
|
|
|
make_request_fn *make_request_fn;
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
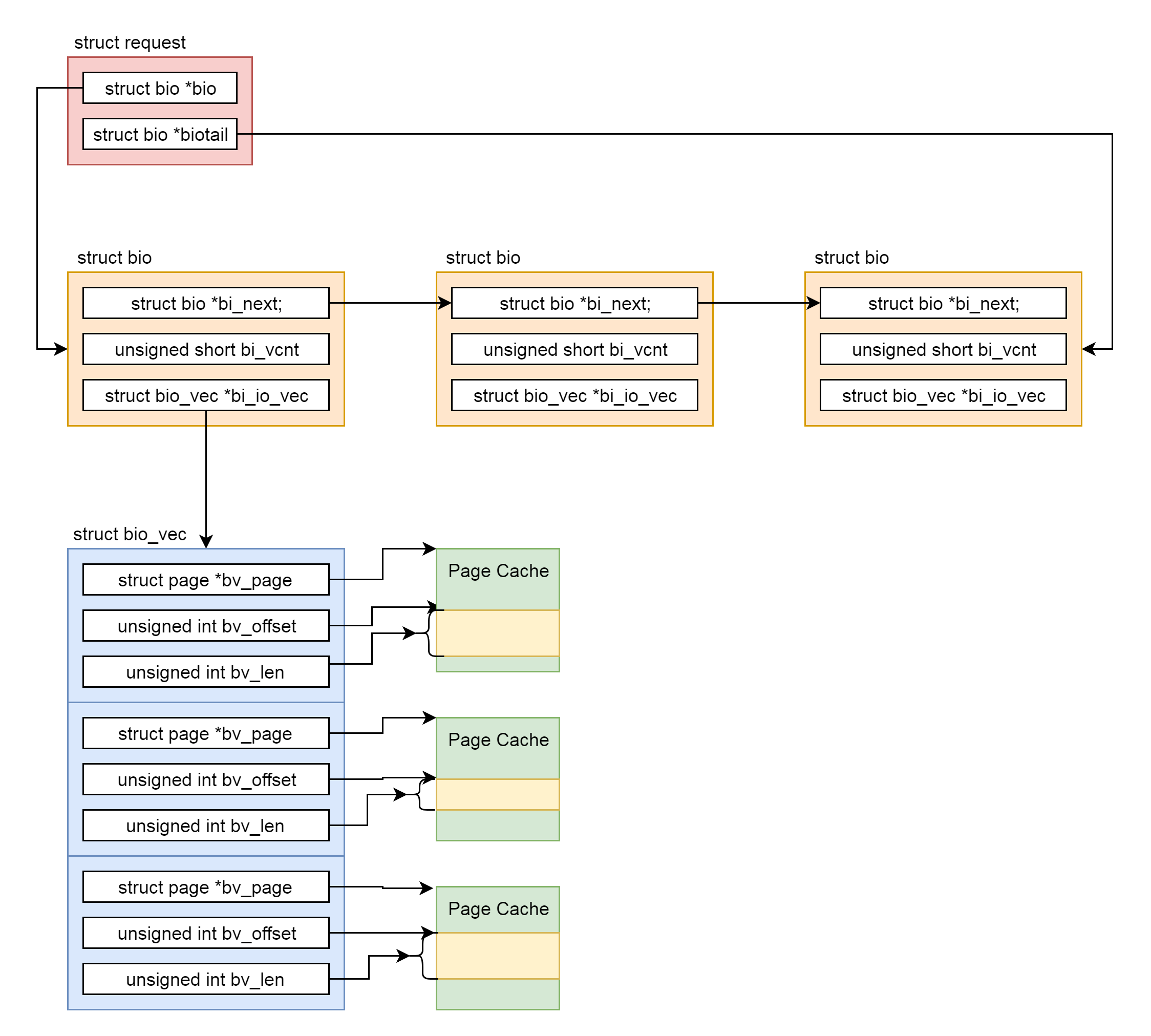
在请求队列request\_queue上,首先是有一个链表list\_head,保存请求request。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct request {
|
|
|
|
|
|
struct list_head queuelist;
|
|
|
|
|
|
......
|
|
|
|
|
|
struct request_queue *q;
|
|
|
|
|
|
......
|
|
|
|
|
|
struct bio *bio;
|
|
|
|
|
|
struct bio *biotail;
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
每个request包括一个链表的struct bio,有指针指向一头一尾。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct bio {
|
|
|
|
|
|
struct bio *bi_next; /* request queue link */
|
|
|
|
|
|
struct block_device *bi_bdev;
|
|
|
|
|
|
blk_status_t bi_status;
|
|
|
|
|
|
......
|
|
|
|
|
|
struct bvec_iter bi_iter;
|
|
|
|
|
|
unsigned short bi_vcnt; /* how many bio_vec's */
|
|
|
|
|
|
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
|
|
|
|
|
|
atomic_t __bi_cnt; /* pin count */
|
|
|
|
|
|
struct bio_vec *bi_io_vec; /* the actual vec list */
|
|
|
|
|
|
......
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
struct bio_vec {
|
|
|
|
|
|
struct page *bv_page;
|
|
|
|
|
|
unsigned int bv_len;
|
|
|
|
|
|
unsigned int bv_offset;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在bio中,bi\_next是链表中的下一项,struct bio\_vec指向一组页面。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在请求队列request\_queue上,还有两个重要的函数,一个是make\_request\_fn函数,用于生成request;另一个是request\_fn函数,用于处理request。
|
|
|
|
|
|
|
|
|
|
|
|
### 块设备的初始化
|
|
|
|
|
|
|
|
|
|
|
|
我们还是以scsi驱动为例。在初始化设备驱动的时候,我们会调用scsi\_alloc\_queue,把request\_fn设置为scsi\_request\_fn。我们还会调用blk\_init\_allocated\_queue->blk\_queue\_make\_request,把make\_request\_fn设置为blk\_queue\_bio。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/**
|
|
|
|
|
|
* scsi_alloc_sdev - allocate and setup a scsi_Device
|
|
|
|
|
|
* @starget: which target to allocate a &scsi_device for
|
|
|
|
|
|
* @lun: which lun
|
|
|
|
|
|
* @hostdata: usually NULL and set by ->slave_alloc instead
|
|
|
|
|
|
*
|
|
|
|
|
|
* Description:
|
|
|
|
|
|
* Allocate, initialize for io, and return a pointer to a scsi_Device.
|
|
|
|
|
|
* Stores the @shost, @channel, @id, and @lun in the scsi_Device, and
|
|
|
|
|
|
* adds scsi_Device to the appropriate list.
|
|
|
|
|
|
*
|
|
|
|
|
|
* Return value:
|
|
|
|
|
|
* scsi_Device pointer, or NULL on failure.
|
|
|
|
|
|
**/
|
|
|
|
|
|
static struct scsi_device *scsi_alloc_sdev(struct scsi_target *starget,
|
|
|
|
|
|
u64 lun, void *hostdata)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct scsi_device *sdev;
|
|
|
|
|
|
sdev = kzalloc(sizeof(*sdev) + shost->transportt->device_size,
|
|
|
|
|
|
GFP_ATOMIC);
|
|
|
|
|
|
......
|
|
|
|
|
|
sdev->request_queue = scsi_alloc_queue(sdev);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
struct request_queue *scsi_alloc_queue(struct scsi_device *sdev)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct Scsi_Host *shost = sdev->host;
|
|
|
|
|
|
struct request_queue *q;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
q = blk_alloc_queue_node(GFP_KERNEL, NUMA_NO_NODE);
|
|
|
|
|
|
if (!q)
|
|
|
|
|
|
return NULL;
|
|
|
|
|
|
q->cmd_size = sizeof(struct scsi_cmnd) + shost->hostt->cmd_size;
|
|
|
|
|
|
q->rq_alloc_data = shost;
|
|
|
|
|
|
q->request_fn = scsi_request_fn;
|
|
|
|
|
|
q->init_rq_fn = scsi_init_rq;
|
|
|
|
|
|
q->exit_rq_fn = scsi_exit_rq;
|
|
|
|
|
|
q->initialize_rq_fn = scsi_initialize_rq;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
//调用blk_queue_make_request(q, blk_queue_bio);
|
|
|
|
|
|
if (blk_init_allocated_queue(q) < 0) {
|
|
|
|
|
|
blk_cleanup_queue(q);
|
|
|
|
|
|
return NULL;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
__scsi_init_queue(shost, q);
|
|
|
|
|
|
......
|
|
|
|
|
|
return q
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在blk\_init\_allocated\_queue中,除了初始化make\_request\_fn函数,我们还要做一件很重要的事情,就是初始化I/O的电梯算法。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
int blk_init_allocated_queue(struct request_queue *q)
|
|
|
|
|
|
{
|
|
|
|
|
|
q->fq = blk_alloc_flush_queue(q, NUMA_NO_NODE, q->cmd_size);
|
|
|
|
|
|
......
|
|
|
|
|
|
blk_queue_make_request(q, blk_queue_bio);
|
|
|
|
|
|
......
|
|
|
|
|
|
/* init elevator */
|
|
|
|
|
|
if (elevator_init(q, NULL)) {
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
电梯算法有很多种类型,定义为elevator\_type。下面我来逐一说一下。
|
|
|
|
|
|
|
|
|
|
|
|
* **struct elevator\_type elevator\_noop**
|
|
|
|
|
|
|
|
|
|
|
|
Noop调度算法是最简单的IO调度算法,它将IO请求放入到一个FIFO队列中,然后逐个执行这些IO请求。
|
|
|
|
|
|
|
|
|
|
|
|
* **struct elevator\_type iosched\_deadline**
|
|
|
|
|
|
|
|
|
|
|
|
Deadline算法要保证每个IO请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。为了完成这个目标,算法中引入了两类队列,一类队列用来对请求按起始扇区序号进行排序,通过红黑树来组织,我们称为sort\_list,按照此队列传输性能会比较高;另一类队列对请求按它们的生成时间进行排序,由链表来组织,称为fifo\_list,并且每一个请求都有一个期限值。
|
|
|
|
|
|
|
|
|
|
|
|
* **struct elevator\_type iosched\_cfq**
|
|
|
|
|
|
|
|
|
|
|
|
又看到了熟悉的CFQ完全公平调度算法。所有的请求会在多个队列中排序。同一个进程的请求,总是在同一队列中处理。时间片会分配到每个队列,通过轮询算法,我们保证了I/O带宽,以公平的方式,在不同队列之间进行共享。
|
|
|
|
|
|
|
|
|
|
|
|
elevator\_init中会根据名称来指定电梯算法,如果没有选择,那就默认使用iosched\_cfq。
|
|
|
|
|
|
|
|
|
|
|
|
### 请求提交与调度
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们回到generic\_make\_request函数中。调用队列的make\_request\_fn函数,其实就是调用blk\_queue\_bio。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static blk_qc_t blk_queue_bio(struct request_queue *q, struct bio *bio)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct request *req, *free;
|
|
|
|
|
|
unsigned int request_count = 0;
|
|
|
|
|
|
......
|
|
|
|
|
|
switch (elv_merge(q, &req, bio)) {
|
|
|
|
|
|
case ELEVATOR_BACK_MERGE:
|
|
|
|
|
|
if (!bio_attempt_back_merge(q, req, bio))
|
|
|
|
|
|
break;
|
|
|
|
|
|
elv_bio_merged(q, req, bio);
|
|
|
|
|
|
free = attempt_back_merge(q, req);
|
|
|
|
|
|
if (free)
|
|
|
|
|
|
__blk_put_request(q, free);
|
|
|
|
|
|
else
|
|
|
|
|
|
elv_merged_request(q, req, ELEVATOR_BACK_MERGE);
|
|
|
|
|
|
goto out_unlock;
|
|
|
|
|
|
case ELEVATOR_FRONT_MERGE:
|
|
|
|
|
|
if (!bio_attempt_front_merge(q, req, bio))
|
|
|
|
|
|
break;
|
|
|
|
|
|
elv_bio_merged(q, req, bio);
|
|
|
|
|
|
free = attempt_front_merge(q, req);
|
|
|
|
|
|
if (free)
|
|
|
|
|
|
__blk_put_request(q, free);
|
|
|
|
|
|
else
|
|
|
|
|
|
elv_merged_request(q, req, ELEVATOR_FRONT_MERGE);
|
|
|
|
|
|
goto out_unlock;
|
|
|
|
|
|
default:
|
|
|
|
|
|
break;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
get_rq:
|
|
|
|
|
|
req = get_request(q, bio->bi_opf, bio, GFP_NOIO);
|
|
|
|
|
|
......
|
|
|
|
|
|
blk_init_request_from_bio(req, bio);
|
|
|
|
|
|
......
|
|
|
|
|
|
add_acct_request(q, req, where);
|
|
|
|
|
|
__blk_run_queue(q);
|
|
|
|
|
|
out_unlock:
|
|
|
|
|
|
......
|
|
|
|
|
|
return BLK_QC_T_NONE;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
blk\_queue\_bio首先做的一件事情是调用elv\_merge来判断,当前这个bio请求是否能够和目前已有的request合并起来,成为同一批I/O操作,从而提高读取和写入的性能。
|
|
|
|
|
|
|
|
|
|
|
|
判断标准和struct bio的成员struct bvec\_iter有关,它里面有两个变量,一个是起始磁盘簇bi\_sector,另一个是大小bi\_size。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
enum elv_merge elv_merge(struct request_queue *q, struct request **req,
|
|
|
|
|
|
struct bio *bio)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct elevator_queue *e = q->elevator;
|
|
|
|
|
|
struct request *__rq;
|
|
|
|
|
|
......
|
|
|
|
|
|
if (q->last_merge && elv_bio_merge_ok(q->last_merge, bio)) {
|
|
|
|
|
|
enum elv_merge ret = blk_try_merge(q->last_merge, bio);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (ret != ELEVATOR_NO_MERGE) {
|
|
|
|
|
|
*req = q->last_merge;
|
|
|
|
|
|
return ret;
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
__rq = elv_rqhash_find(q, bio->bi_iter.bi_sector);
|
|
|
|
|
|
if (__rq && elv_bio_merge_ok(__rq, bio)) {
|
|
|
|
|
|
*req = __rq;
|
|
|
|
|
|
return ELEVATOR_BACK_MERGE;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if (e->uses_mq && e->type->ops.mq.request_merge)
|
|
|
|
|
|
return e->type->ops.mq.request_merge(q, req, bio);
|
|
|
|
|
|
else if (!e->uses_mq && e->type->ops.sq.elevator_merge_fn)
|
|
|
|
|
|
return e->type->ops.sq.elevator_merge_fn(q, req, bio);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
return ELEVATOR_NO_MERGE;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
elv\_merge尝试了三次合并。
|
|
|
|
|
|
|
|
|
|
|
|
第一次,它先判断和上一次合并的request能不能再次合并,看看能不能赶上马上要走的这部电梯。在blk\_try\_merge主要做了这样的判断:如果blk\_rq\_pos(rq) + blk\_rq\_sectors(rq) == bio->bi\_iter.bi\_sector,也就是说这个request的起始地址加上它的大小(其实是这个request的结束地址),如果和bio的起始地址能接得上,那就把bio放在request的最后,我们称为ELEVATOR\_BACK\_MERGE。
|
|
|
|
|
|
|
|
|
|
|
|
如果blk\_rq\_pos(rq) - bio\_sectors(bio) == bio->bi\_iter.bi\_sector,也就是说,这个request的起始地址减去bio的大小等于bio的起始地址,这说明bio放在request的最前面能够接得上,那就把bio放在request的最前面,我们称为ELEVATOR\_FRONT\_MERGE。否则,那就不合并,我们称为ELEVATOR\_NO\_MERGE。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
enum elv_merge blk_try_merge(struct request *rq, struct bio *bio)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
if (blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector)
|
|
|
|
|
|
return ELEVATOR_BACK_MERGE;
|
|
|
|
|
|
else if (blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector)
|
|
|
|
|
|
return ELEVATOR_FRONT_MERGE;
|
|
|
|
|
|
return ELEVATOR_NO_MERGE;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
第二次,如果和上一个合并过的request无法合并,那我们就调用elv\_rqhash\_find。然后按照bio的起始地址查找request,看有没有能够合并的。如果有的话,因为是按照起始地址找的,应该接在人家的后面,所以是ELEVATOR\_BACK\_MERGE。
|
|
|
|
|
|
|
|
|
|
|
|
第三次,调用elevator\_merge\_fn试图合并。对于iosched\_cfq,调用的是cfq\_merge。在这里面,cfq\_find\_rq\_fmerge会调用elv\_rb\_find函数,里面的参数是bio的结束地址。我们还是要看,能不能找到可以合并的。如果有的话,因为是按照结束地址找的,应该接在人家前面,所以是ELEVATOR\_FRONT\_MERGE。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static enum elv_merge cfq_merge(struct request_queue *q, struct request **req,
|
|
|
|
|
|
struct bio *bio)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct cfq_data *cfqd = q->elevator->elevator_data;
|
|
|
|
|
|
struct request *__rq;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
__rq = cfq_find_rq_fmerge(cfqd, bio);
|
|
|
|
|
|
if (__rq && elv_bio_merge_ok(__rq, bio)) {
|
|
|
|
|
|
*req = __rq;
|
|
|
|
|
|
return ELEVATOR_FRONT_MERGE;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
return ELEVATOR_NO_MERGE;
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
static struct request *
|
|
|
|
|
|
cfq_find_rq_fmerge(struct cfq_data *cfqd, struct bio *bio)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct task_struct *tsk = current;
|
|
|
|
|
|
struct cfq_io_cq *cic;
|
|
|
|
|
|
struct cfq_queue *cfqq;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
cic = cfq_cic_lookup(cfqd, tsk->io_context);
|
|
|
|
|
|
if (!cic)
|
|
|
|
|
|
return NULL;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
cfqq = cic_to_cfqq(cic, op_is_sync(bio->bi_opf));
|
|
|
|
|
|
if (cfqq)
|
|
|
|
|
|
return elv_rb_find(&cfqq->sort_list, bio_end_sector(bio));
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
return NUL
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
等从elv\_merge返回blk\_queue\_bio的时候,我们就知道,应该做哪种类型的合并,接着就要进行真的合并。如果没有办法合并,那就调用get\_request,创建一个新的request,调用blk\_init\_request\_from\_bio,将bio放到新的request里面,然后调用add\_acct\_request,把新的request加到request\_queue队列中。
|
|
|
|
|
|
|
|
|
|
|
|
至此,我们解析完了generic\_make\_request中最重要的两大逻辑:获取一个请求队列request\_queue和调用这个队列的make\_request\_fn函数。
|
|
|
|
|
|
|
|
|
|
|
|
其实,generic\_make\_request其他部分也很令人困惑。感觉里面有特别多的struct bio\_list,倒腾过来,倒腾过去的。这是因为,很多块设备是有层次的。
|
|
|
|
|
|
|
|
|
|
|
|
比如,我们用两块硬盘组成RAID,两个RAID盘组成LVM,然后我们就可以在LVM上创建一个块设备给用户用,我们称接近用户的块设备为**高层次的块设备**,接近底层的块设备为**低层次**(lower)**的块设备**。这样,generic\_make\_request把I/O请求发送给高层次的块设备的时候,会调用高层块设备的make\_request\_fn,高层块设备又要调用generic\_make\_request,将请求发送给低层次的块设备。虽然块设备的层次不会太多,但是对于代码generic\_make\_request来讲,这可是递归的调用,一不小心,就会递归过深,无法正常退出,而且内核栈的大小又非常有限,所以要比较小心。
|
|
|
|
|
|
|
|
|
|
|
|
这里你是否理解了struct bio\_list bio\_list\_on\_stack\[2\]的名字为什么叫stack呢?其实,将栈的操作变成对于队列的操作,队列不在栈里面,会大很多。每次generic\_make\_request被当前任务调用的时候,将current->bio\_list设置为bio\_list\_on\_stack,并在generic\_make\_request的一开始就判断current->bio\_list是否为空。如果不为空,说明已经在generic\_make\_request的调用里面了,就不必调用make\_request\_fn进行递归了,直接把请求加入到bio\_list里面就可以了,这就实现了递归的及时退出。
|
|
|
|
|
|
|
|
|
|
|
|
如果current->bio\_list为空,那我们就将current->bio\_list设置为bio\_list\_on\_stack后,进入do-while循环,做咱们分析过的generic\_make\_request的两大逻辑。但是,当前的队列调用make\_request\_fn的时候,在make\_request\_fn的具体实现中,会生成新的bio。调用更底层的块设备,也会生成新的bio,都会放在bio\_list\_on\_stack的队列中,是一个边处理还边创建的过程。
|
|
|
|
|
|
|
|
|
|
|
|
bio\_list\_on\_stack\[1\] = bio\_list\_on\_stack\[0\]这一句在make\_request\_fn之前,将之前队列里面遗留没有处理的保存下来,接着bio\_list\_init将bio\_list\_on\_stack\[0\]设置为空,然后调用make\_request\_fn,在make\_request\_fn里面如果有新的bio生成,都会加到bio\_list\_on\_stack\[0\]这个队列里面来。
|
|
|
|
|
|
|
|
|
|
|
|
make\_request\_fn执行完毕后,可以想象bio\_list\_on\_stack\[0\]可能又多了一些bio了,接下来的循环中调用bio\_list\_pop将bio\_list\_on\_stack\[0\]积攒的bio拿出来,分别放在两个队列lower和same中,顾名思义,lower就是更低层次的块设备的bio,same是同层次的块设备的bio。
|
|
|
|
|
|
|
|
|
|
|
|
接下来我们能将lower、same以及bio\_list\_on\_stack\[1\] 都取出来,放在bio\_list\_on\_stack\[0\]统一进行处理。当然应该lower优先了,因为只有底层的块设备的I/O做完了,上层的块设备的I/O才能做完。
|
|
|
|
|
|
|
|
|
|
|
|
到这里,generic\_make\_request的逻辑才算解析完毕。对于写入的数据来讲,其实仅仅是将bio请求放在请求队列上,设备驱动程序还没往设备里面写呢。
|
|
|
|
|
|
|
|
|
|
|
|
### 请求的处理
|
|
|
|
|
|
|
|
|
|
|
|
设备驱动程序往设备里面写,调用的是请求队列request\_queue的另外一个函数request\_fn。对于scsi设备来讲,调用的是scsi\_request\_fn。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static void scsi_request_fn(struct request_queue *q)
|
|
|
|
|
|
__releases(q->queue_lock)
|
|
|
|
|
|
__acquires(q->queue_lock)
|
|
|
|
|
|
{
|
|
|
|
|
|
struct scsi_device *sdev = q->queuedata;
|
|
|
|
|
|
struct Scsi_Host *shost;
|
|
|
|
|
|
struct scsi_cmnd *cmd;
|
|
|
|
|
|
struct request *req;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/*
|
|
|
|
|
|
* To start with, we keep looping until the queue is empty, or until
|
|
|
|
|
|
* the host is no longer able to accept any more requests.
|
|
|
|
|
|
*/
|
|
|
|
|
|
shost = sdev->host;
|
|
|
|
|
|
for (;;) {
|
|
|
|
|
|
int rtn;
|
|
|
|
|
|
/*
|
|
|
|
|
|
* get next queueable request. We do this early to make sure
|
|
|
|
|
|
* that the request is fully prepared even if we cannot
|
|
|
|
|
|
* accept it.
|
|
|
|
|
|
*/
|
|
|
|
|
|
req = blk_peek_request(q);
|
|
|
|
|
|
......
|
|
|
|
|
|
/*
|
|
|
|
|
|
* Remove the request from the request list.
|
|
|
|
|
|
*/
|
|
|
|
|
|
if (!(blk_queue_tagged(q) && !blk_queue_start_tag(q, req)))
|
|
|
|
|
|
blk_start_request(req);
|
|
|
|
|
|
.....
|
|
|
|
|
|
cmd = req->special;
|
|
|
|
|
|
......
|
|
|
|
|
|
/*
|
|
|
|
|
|
* Dispatch the command to the low-level driver.
|
|
|
|
|
|
*/
|
|
|
|
|
|
cmd->scsi_done = scsi_done;
|
|
|
|
|
|
rtn = scsi_dispatch_cmd(cmd);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
return;
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在这里面是一个for无限循环,从request\_queue中读取request,然后封装更加底层的指令,给设备控制器下指令,实施真正的I/O操作。
|
|
|
|
|
|
|
|
|
|
|
|
## 总结时刻
|
|
|
|
|
|
|
|
|
|
|
|
这一节我们讲了如何将块设备I/O请求送达到外部设备。
|
|
|
|
|
|
|
|
|
|
|
|
对于块设备的I/O操作分为两种,一种是直接I/O,另一种是缓存I/O。无论是哪种I/O,最终都会调用submit\_bio提交块设备I/O请求。
|
|
|
|
|
|
|
|
|
|
|
|
对于每一种块设备,都有一个gendisk表示这个设备,它有一个请求队列,这个队列是一系列的request对象。每个request对象里面包含多个BIO对象,指向page cache。所谓的写入块设备,I/O就是将page cache里面的数据写入硬盘。
|
|
|
|
|
|
|
|
|
|
|
|
对于请求队列来讲,还有两个函数,一个函数叫make\_request\_fn函数,用于将请求放入队列。submit\_bio会调用generic\_make\_request,然后调用这个函数。
|
|
|
|
|
|
|
|
|
|
|
|
另一个函数往往在设备驱动程序里实现,我们叫request\_fn函数,它用于从队列里面取出请求来,写入外部设备。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
至此,整个写入文件的过程才算完全结束。这真是个复杂的过程,涉及系统调用、内存管理、文件系统和输入输出。这足以说明,操作系统真的是一个非常复杂的体系,环环相扣,需要分层次层层展开来学习。
|
|
|
|
|
|
|
|
|
|
|
|
到这里,专栏已经过半了,你应该能发现,很多我之前说“后面会细讲”的东西,现在正在一点一点解释清楚,而文中越来越多出现“前面我们讲过”的字眼,你是否当时学习前面知识的时候,没有在意,导致学习后面的知识产生困惑了呢?没关系,及时倒回去复习,再回过头去看,当初学过的很多知识会变得清晰很多。
|
|
|
|
|
|
|
|
|
|
|
|
## 课堂练习
|
|
|
|
|
|
|
|
|
|
|
|
你知道如何查看磁盘调度算法、修改磁盘调度算法以及I/O队列的长度吗?
|
|
|
|
|
|
|
|
|
|
|
|
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|