|
|
|
|
|
# 08 | 事件驱动:C10M是如何实现的?
|
|
|
|
|
|
|
|
|
|
|
|
你好,我是陶辉。
|
|
|
|
|
|
|
|
|
|
|
|
上一讲介绍了广播与组播这种一对多通讯方式,从这一讲开始,我们回到主流的一对一通讯方式。
|
|
|
|
|
|
|
|
|
|
|
|
早些年我们谈到高并发,总是会提到C10K,这是指服务器同时处理1万个TCP连接。随着服务器性能的提升,近来我们更希望单台服务器的并发能力可以达到C10M,也就是同时可以处理1千万个TCP连接。从C10K到C10M,实现技术并没有本质变化,都是用事件驱动和异步开发实现的。[\[第5讲\]](https://time.geekbang.org/column/article/233629) 介绍过的协程,也是依赖这二者实现高并发的。
|
|
|
|
|
|
|
|
|
|
|
|
做过异步开发的同学都知道,处理基于TCP的应用层协议时,一个请求的处理代码必须被拆分到多个回调函数中,由异步框架在相应的事件生成时调用它们。这就是事件驱动方式,它通过减少上下文切换次数,实现了C10M级别的高并发。
|
|
|
|
|
|
|
|
|
|
|
|
不过,做应用开发的同学往往不清楚什么叫做“事件”,不了解处理HTTP请求的回调函数与事件间的关系。这样,在高并发下,当多个HTTP请求争抢执行时,涉及资源分配、释放等重要工作的回调函数,就可能在错误的时间被调用,进而引发一系列问题。比如,不同的回调函数对应不同的事件,如果某个函数执行时间过长,就会影响其他请求,可能导致大量请求出现超时而处理失败。
|
|
|
|
|
|
|
|
|
|
|
|
这一讲我们就来介绍一下,事件是怎样产生的?它是如何驱动请求执行的?多路复用技术是怎样协助实现异步开发的?理解了这些,你也就明白了这种事件驱动的解决方案,知道了怎么样实现C10M。
|
|
|
|
|
|
|
|
|
|
|
|
## 事件是怎么产生的?
|
|
|
|
|
|
|
|
|
|
|
|
要了解“事件驱动”的运作机制,首先就要搞清楚到底什么是事件。这就需要你对网络原理有深入的理解了。
|
|
|
|
|
|
|
|
|
|
|
|
简单来说,从网络中接收到一个报文,就可能产生一个事件。如上一讲介绍过的UDP请求就是最简单的例子,一个UDP请求通常仅由一个网络报文组成,所以,当收到一个UDP报文,就意味着收到一个请求,它会生成一个事件,进而触发回调函数执行。
|
|
|
|
|
|
|
|
|
|
|
|
不过,常见的HTTP等协议都是基于TCP实现的。由于TCP是一种面向字节流的协议,HTTP请求的大小并不受限制,当一个HTTP请求的大小超过TCP报文的最大长度时,请求会被拆分到多个报文中运输,在接收端的缓冲区中重组、排序。因此,并不是每个到达的TCP报文都能生成事件的。
|
|
|
|
|
|
|
|
|
|
|
|
如果不理解事件和TCP报文的关系,就没法准确地掌握处理HTTP请求的函数何时被调用。当然,作为应用开发工程师,我们无须在意实现细节,只要了解TCP连接建立、关闭,以及消息的发送和接收这四个场景中,报文与事件间的关系就可以了。
|
|
|
|
|
|
|
|
|
|
|
|
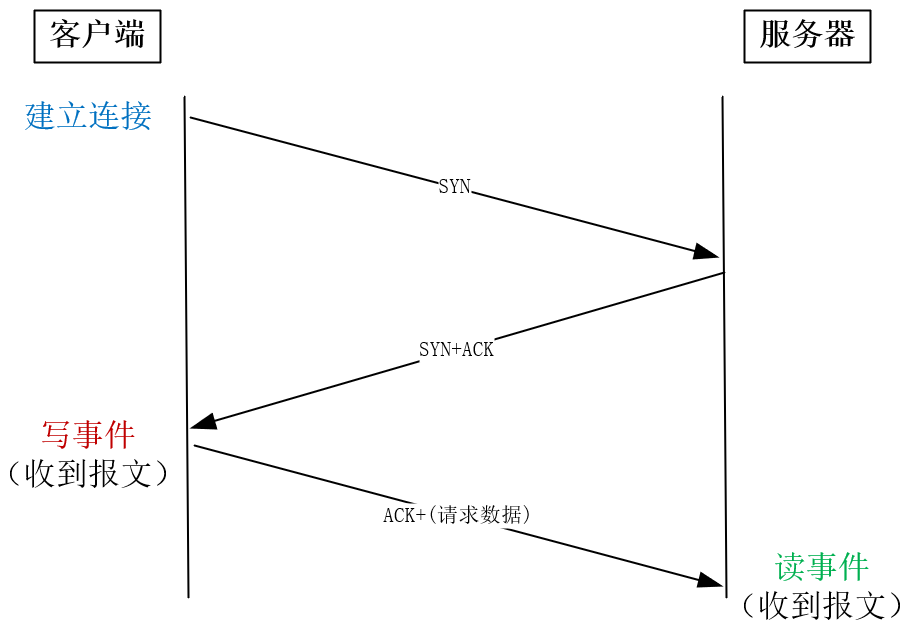
事件并没有你想象中那么复杂,它只有两种类型:读事件与写事件,其中,读事件表示有到达的消息需要处理,而写事件表示可以发送消息(TCP连接的写缓冲区中有可用空间)。我们先从三次握手建立连接说起,这一过程会产生一读、一写两个事件。
|
|
|
|
|
|
|
|
|
|
|
|
由于TCP允许双向传输,所以**建立连接时,会依次在连接的两个方向上建立通道。**主动发起连接的一方叫做客户端,被动监听端口等待连接的一方叫做服务器。
|
|
|
|
|
|
|
|
|
|
|
|
客户端首先发送SYN报文给服务器,而服务器收到后回复ACK和SYN(这里我们只需要知道产生事件的过程即可,下一讲会详细介绍这两个报文的含义),**当它们到达客户端时,双向连接中由客户端到服务器的通道就建立好了,此时客户端就已经可以发送请求了,因此客户端会产生写事件。**接着,**客户端发送ACK报文,到达服务器后,服务器上会产生读事件**,因为进程原本在监听80等端口,此时有新连接建立成功,应当调用accept函数读取这个连接,所以这是一个读事件。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
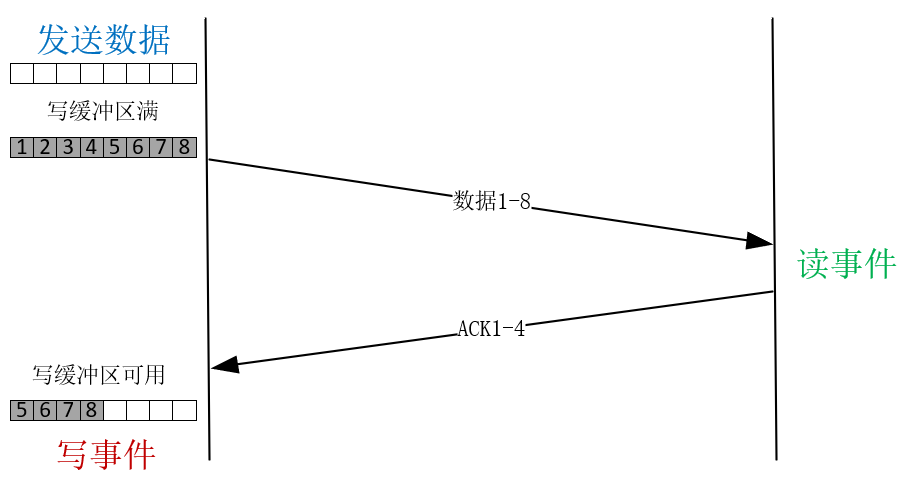
在建立好的TCP连接上收发消息时,读事件对应着接收到对方的消息,这很好理解。写事件则稍微复杂些,我们举个例子加以说明。假设要发送一个2MB的请求,**当调用write函数发送时,会先把内存中的数据拷贝到写缓冲区中后,再发送到网卡上。**
|
|
|
|
|
|
|
|
|
|
|
|
为何要多此一举呢?这是因为在对方没有明确表示收到前,TCP会通过定时器重发写缓冲区中的数据,保证消息能够到达对方。写缓冲区是有大小限制的,我在\[第10讲\]中会详细介绍。这里假设写缓冲区只有1MB,所以调用write发送2MB数据时,write函数的返回值只有1MB,表示写缓冲区已用尽。当收到对方发来的ACK报文后,缓冲区中的数据才能释放,就会产生写事件通知进程发送剩余的那1MB数据。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
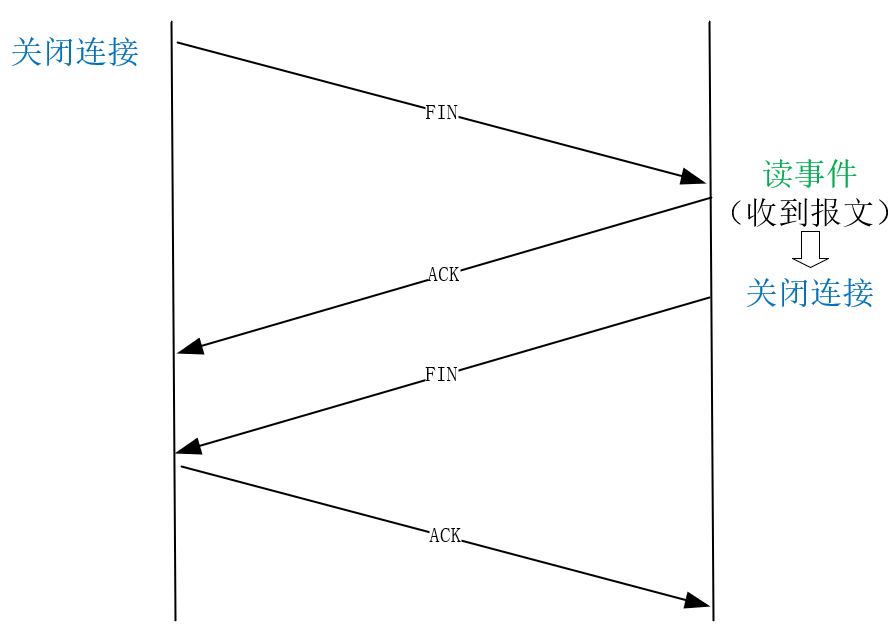
如同建立连接需要双向建立一样,关闭连接也需要双方各自关闭每个方向的通道。主动关闭的一方发送FIN报文,到达被动方后,内核自动回复ACK报文,这表示从主动方到被动方的通道已经关闭。**但被动方到主动方的通道也需要关闭,所以此时被动方会产生读事件,提醒被动方调用close函数关闭连接。**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这样,我们就清楚了TCP报文如何产生事件,也明白回调函数何时执行了。然而,同步代码拆分成多个异步函数成本并不低,咱们手里拿着事件驱动这个锤子,可不能看到什么都像是钉子。
|
|
|
|
|
|
|
|
|
|
|
|
什么样的代码值得基于事件来做拆分呢?还得回到高性能这个最终目标上来。我们知道,做性能优化一定要找出性能瓶颈,针对瓶颈做优化性价比才最高。对于服务器来说,对最慢的操作做异步化改造,才能值回开发效率的损失。而服务里对资源的操作速度由快到慢,依次是CPU、内存、磁盘和网络。CPU和内存的执行速度都是纳秒级的,无须考虑事件驱动,而磁盘和网络都可以采用事件驱动的异步方式处理。
|
|
|
|
|
|
|
|
|
|
|
|
相对而言,网络不只速度慢,而且波动很大,既受制于连接对端的性能,也受制于网络传输路径。把操作网络的同步API改为事件驱动的异步API收益最大。而磁盘(特别是机械硬盘)访问速度虽然不快,但它最慢时也不过几十毫秒,是可控的。而且目前磁盘异步IO技术(参见[\[第4讲\]](https://time.geekbang.org/column/article/232676))还不成熟,它绕过了PageCache性能损失很大。所以当下的事件驱动,主要就是指网络事件。
|
|
|
|
|
|
|
|
|
|
|
|
## 该怎样处理网络事件?
|
|
|
|
|
|
|
|
|
|
|
|
有了网络事件的概念后,我们再来看用户态代码如何处理事件。
|
|
|
|
|
|
|
|
|
|
|
|
网络事件是由内核产生的,进程该怎样获取到它们呢?如epoll这样的多路复用技术可以帮我们做到。多路复用是通讯领域的词汇,有些抽象但原理确很简单。
|
|
|
|
|
|
|
|
|
|
|
|
比如,一条高速的光纤上,允许多个用户用较低的网速同时通讯,这就是多路复用。同样道理,一个进程虽然任一时刻只能处理一个请求,但处理每个请求产生的事件时,若耗时控制在1毫秒以内,这样1秒钟就可以处理数千个请求,从更长的时间维度上看,多个请求复用了一个进程,也叫做多路复用(或者叫做时分多路复用)。我们熟知的epoll,就是内核提供给用户态的多路复用接口,进程可以通过它从内核中获取事件。
|
|
|
|
|
|
|
|
|
|
|
|
epoll是如何获取网络事件的呢?最简单的方法,就是在获取事件时,把所有并发连接传给内核,再由内核返回产生了事件的连接,再处理这些连接对应的请求即可。epoll前的select等多路复用函数就是这么干的。
|
|
|
|
|
|
|
|
|
|
|
|
然而,C10M意味着有一千万个连接,若每个socket是4字节,那么1千万连接就是40M字节。这样,每收集一次事件,就需要从用户态复制40M字节到内核态。而且,高性能Server必须及时地处理网络事件,所以每隔几十毫秒就要收集一次事件,性能消耗巨大。
|
|
|
|
|
|
|
|
|
|
|
|
epoll为了降低性能消耗,把获取事件拆分成两步。
|
|
|
|
|
|
|
|
|
|
|
|
* 第一步把需要监控的socket传给内核(epoll\_ctl函数),它仅在连接建立等有限的时机调用;
|
|
|
|
|
|
* 第二步收集事件(epoll\_wait函数)便不用传递socket了,这样就把socket的重复传递改为了一次传递,降低了性能损耗。
|
|
|
|
|
|
|
|
|
|
|
|
由于网卡的处理能力有限,千兆网卡下,每秒只能接收100MB左右的数据,如果每个请求约10KB,那么每秒大概有1万个请求到达、10万个事件需要处理。这样,即使每隔100毫秒收集一次事件(调用epoll\_wait),每次也不过只有1万个事件(100000 Event/s \* 0.1s = 10000 Event/s)需要处理,只要保证处理一个事件的平均时间小于10微秒(多核处理器可以做到),100毫秒内就可以处理完这些事件(100ms = 10us \* 10000)。 因此,哪怕有1千万并发连接,也能保证1万RPS的处理能力,这就是epoll能在C10M下实现高吞吐量的原因。
|
|
|
|
|
|
|
|
|
|
|
|
进程获取到产生事件的socket后,又该如何处理它呢?这里的核心约束是,处理任何一个事件的耗时都应该是微秒级或者毫秒级,否则就会延误其他事件的处理,不只降低了用户的体验,而且会形成恶性循环。
|
|
|
|
|
|
|
|
|
|
|
|
我们知道,为了应对网络的不确定性,每个参与网络通讯的进程都会为请求设置超时时间。一旦某个socket上的事件迟迟不被处理,当客户端的超时定时器触发时,客户端往往会关闭连接并重发请求,这会让服务器雪上加霜。
|
|
|
|
|
|
|
|
|
|
|
|
怎样保证处理一个事件的时间不会太长呢? 我们把处理事件的代码分为三类来看。
|
|
|
|
|
|
|
|
|
|
|
|
第一类是计算任务,虽然内存、CPU的速度很快,然而循环执行也可能耗时达到秒级。所以,如果一定要引入需要密集计算才能完成的请求,为了不阻碍其他事件的处理,要么把这样的请求放在独立的线程中完成,要么把请求的处理过程拆分成多段,确保每段能够快速执行完,同时每段执行完都要均等地处理其他事件,这样通过放慢该请求的处理时间,就保障了其他请求的及时处理。
|
|
|
|
|
|
|
|
|
|
|
|
第二类会读写磁盘,由于磁盘的写入操作使用了PageCache的延迟写特性,当write函数返回时只是复制到了内存中,所以写入操作很快。磁盘的读取操作就比较慢了,这时,通常要把大文件的读取,拆分成许多份,每份仅有几十KB,降低单次操作的耗时。
|
|
|
|
|
|
|
|
|
|
|
|
第三类是通过网络访问上游服务。与处理客户端请求相似,我们必须使用非阻塞socket,用事件驱动方式处理请求。需要注意的是,许多网络服务提供的SDK,都是基于阻塞socket实现的,使用前必须先做完非阻塞改造。比如Memcached的官方SDK是用阻塞socket实现的,Nginx如果直接使用该SDK访问它,性能就会一落千丈。正确的访问方式,是使用第三方提供的ngx\_http\_memcached\_module模块,它用非阻塞socket重新封装了SDK。
|
|
|
|
|
|
|
|
|
|
|
|
总之,网络报文到达后,内核就产生了读、写事件,而epoll函数使得进程可以高效地收集到这些事件。接下来,要确保在进程中处理每个事件的时间足够短,才能及时地处理所有请求,这个过程中既要避免阻塞socket的使用,也要把耗时过长的操作拆成多份执行。最终,通过快速、及时、均等地执行所有事件,异步Server实现了高并发。
|
|
|
|
|
|
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
|
|
|
|
|
|
最后我们对这一讲做个小结。异步服务改为从事件层面处理请求,在epoll这样的多路复用机制协助下,最终实现了C10M级别的高并发服务。
|
|
|
|
|
|
|
|
|
|
|
|
事件有很多种,网络消息的传输既慢又不可控,所以用网络事件驱动请求的性价比最高。这样,就需要你了解TCP报文是如何产生事件的。
|
|
|
|
|
|
|
|
|
|
|
|
TCP连接建立时,会在客户端产生写事件,在服务器端产生读事件。连接关闭时,则会在被动关闭端产生读事件。在连接上收发消息时,也会产生事件,其中发送消息前的写事件与内核分配的缓冲区有关。
|
|
|
|
|
|
|
|
|
|
|
|
清楚了事件与TCP报文的关系后,可以用多路复用技术获取事件,其中epoll是佼佼者,它取消了收集事件时重复传递的大量socket参数,给C10M的实现提供了基础。
|
|
|
|
|
|
|
|
|
|
|
|
你需要注意的是,处理epoll收集到的事件时,必须保证处理一个事件的平均时间在毫秒级以内。传统的阻塞socket是做不到的,所以必须用非阻塞socket替换阻塞socket。如果事件的回调函数耗时过长,也得拆分为多个耗时短的函数,用多次事件(比如定时器事件)的触发来替代。
|
|
|
|
|
|
|
|
|
|
|
|
虽然我们有了上述的事件驱动方案,但实现C10M还需要更谨慎地使用不过数百GB的服务器内存。关于如何降低内存的消耗,可以关注[\[第2讲\]](https://time.geekbang.org/column/article/230221) 提到的内存池,\[第11讲\] 还会介绍如何减少连接缓冲区的空间占用。
|
|
|
|
|
|
|
|
|
|
|
|
这一讲我们介绍了事件驱动的总体方案,但C10M需要高效的用心几乎所有服务器资源,所以,我们还得通过Linux更精细地控制TCP的行为,接下来的3讲我们将深入Linux,讨论如何优化TCP的性能。
|
|
|
|
|
|
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
|
|
|
|
|
|
最后,留给你一个思考题,需要CPU做密集计算的请求,该如何拆分到事件驱动框架中呢?欢迎你在留言区留言,与大家一起探讨。
|
|
|
|
|
|
|
|
|
|
|
|
感谢阅读,如果你觉得这节课对你有一些启发,也欢迎把它分享给你的朋友。
|
|
|
|
|
|
|