|
|
|
|
|
# 14 | BigTable的开源实现:HBase
|
|
|
|
|
|
|
|
|
|
|
|
我们知道,Google发表GFS、MapReduce、BigTable三篇论文,号称“三驾马车”,开启了大数据的时代。那和这“三驾马车”对应的有哪些开源产品呢?我们前面已经讲过了GFS对应的Hadoop分布式文件系统HDFS,以及MapReduce对应的Hadoop分布式计算框架MapReduce,今天我们就来领略一下BigTable对应的NoSQL系统HBase,看看它是如何大规模处理海量数据的。
|
|
|
|
|
|
|
|
|
|
|
|
在计算机数据存储领域,一直是关系数据库(RDBMS)的天下,以至于在传统企业的应用领域,许多应用系统设计都是面向数据库设计,也就是**先设计数据库然后设计程序**,从而导致**关系模型绑架对象模型**,并由此引申出旷日持久的业务对象贫血模型与充血模型之争。
|
|
|
|
|
|
|
|
|
|
|
|
业界为了解决关系数据库的不足,提出了诸多方案,比较有名的是对象数据库,但是这些数据库的出现似乎只是进一步证明关系数据库的优越而已。直到人们遇到了关系数据库难以克服的缺陷——糟糕的海量数据处理能力及僵硬的设计约束,局面才有所改善。从Google的BigTable开始,一系列的可以进行海量数据存储与访问的数据库被设计出来,更进一步说,NoSQL这一概念被提了出来。
|
|
|
|
|
|
|
|
|
|
|
|
NoSQL,主要指非关系的、分布式的、支持海量数据存储的数据库设计模式。也有许多专家将 NoSQL解读为Not Only SQL,表示NoSQL只是关系数据库的补充,而不是替代方案。其中,HBase是这一类NoSQL系统的杰出代表。
|
|
|
|
|
|
|
|
|
|
|
|
HBase之所以能够具有海量数据处理能力,其根本在于和传统关系型数据库设计的不同思路。传统关系型数据库对存储在其上的数据有很多约束,学习关系数据库都要学习数据库设计范式,事实上,是在数据存储中包含了一部分业务逻辑。而NoSQL数据库则简单暴力地认为,数据库就是存储数据的,业务逻辑应该由应用程序去处理,有时候不得不说,简单暴力也是一种美。
|
|
|
|
|
|
|
|
|
|
|
|
## HBase可伸缩架构
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看看HBase的架构设计。HBase为可伸缩海量数据储存而设计,实现面向在线业务的实时数据访问延迟。HBase的伸缩性主要依赖其可分裂的HRegion及可伸缩的分布式文件系统HDFS实现。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
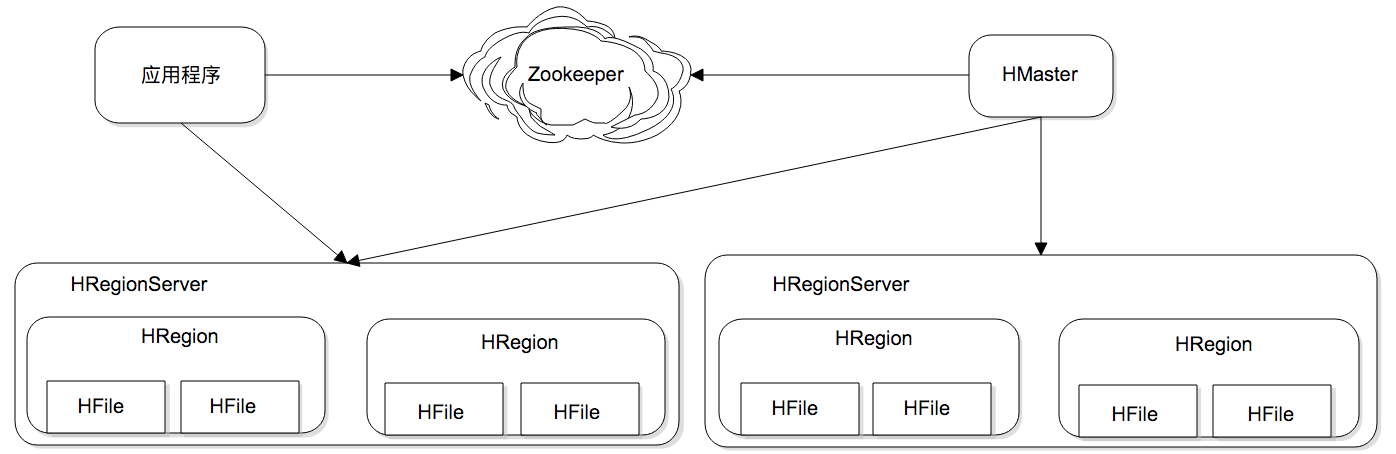
HRegion是HBase负责数据存储的主要进程,应用程序对数据的读写操作都是通过和HRegion通信完成。上面是HBase架构图,我们可以看到在HBase中,数据以HRegion为单位进行管理,也就是说应用程序如果想要访问一个数据,必须先找到HRegion,然后将数据读写操作提交给HRegion,由 HRegion完成存储层面的数据操作。
|
|
|
|
|
|
|
|
|
|
|
|
HRegionServer是物理服务器,每个HRegionServer上可以启动多个HRegion实例。当一个 HRegion中写入的数据太多,达到配置的阈值时,一个HRegion会分裂成两个HRegion,并将HRegion在整个集群中进行迁移,以使HRegionServer的负载均衡。
|
|
|
|
|
|
|
|
|
|
|
|
每个HRegion中存储一段Key值区间\[key1, key2)的数据,所有HRegion的信息,包括存储的Key值区间、所在HRegionServer地址、访问端口号等,都记录在HMaster服务器上。为了保证HMaster的高可用,HBase会启动多个HMaster,并通过ZooKeeper选举出一个主服务器。
|
|
|
|
|
|
|
|
|
|
|
|
下面是一张调用时序图,应用程序通过ZooKeeper获得主HMaster的地址,输入Key值获得这个Key所在的HRegionServer地址,然后请求HRegionServer上的HRegion,获得所需要的数据。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
数据写入过程也是一样,需要先得到HRegion才能继续操作。HRegion会把数据存储在若干个HFile格式的文件中,这些文件使用HDFS分布式文件系统存储,在整个集群内分布并高可用。当一个HRegion中数据量太多时,这个HRegion连同HFile会分裂成两个HRegion,并根据集群中服务器负载进行迁移。如果集群中有新加入的服务器,也就是说有了新的HRegionServer,由于其负载较低,也会把HRegion迁移过去并记录到HMaster,从而实现HBase的线性伸缩。
|
|
|
|
|
|
|
|
|
|
|
|
先小结一下上面的内容,HBase的核心设计目标是解决海量数据的分布式存储,和Memcached这类分布式缓存的路由算法不同,HBase的做法是按Key的区域进行分片,这个分片也就是HRegion。应用程序通过HMaster查找分片,得到HRegion所在的服务器HRegionServer,然后和该服务器通信,就得到了需要访问的数据。
|
|
|
|
|
|
|
|
|
|
|
|
## HBase可扩展数据模型
|
|
|
|
|
|
|
|
|
|
|
|
传统的关系数据库为了保证关系运算(通过SQL语句)的正确性,在设计数据库表结构的时候,需要指定表的schema也就是字段名称、数据类型等,并要遵循特定的设计范式。这些规范带来了一个问题,就是僵硬的数据结构难以面对需求变更带来的挑战,有些应用系统设计者通过预先设计一些冗余字段来应对,但显然这种设计也很糟糕。
|
|
|
|
|
|
|
|
|
|
|
|
那有没有办法能够做到可扩展的数据结构设计呢?不用修改表结构就可以新增字段呢?当然有的,许多NoSQL数据库使用的列族(ColumnFamily)设计就是其中一个解决方案。列族最早在Google的BigTable中使用,这是一种面向列族的稀疏矩阵存储格式,如下图所示。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
这是一个学生的基本信息表,表中不同学生的联系方式各不相同,选修的课程也不同,而且将来还会有更多联系方式和课程加入到这张表里,如果按照传统的关系数据库设计,无论提前预设多少冗余字段都会捉襟见肘、疲于应付。
|
|
|
|
|
|
|
|
|
|
|
|
而使用支持列族结构的NoSQL数据库,在创建表的时候,只需要指定列族的名字,无需指定字段(Column)。那什么时候指定字段呢?可以在数据写入时再指定。通过这种方式,数据表可以包含数百万的字段,这样就可以随意扩展应用程序的数据结构了。并且这种数据库在查询时也很方便,可以通过指定任意字段名称和值进行查询。
|
|
|
|
|
|
|
|
|
|
|
|
HBase这种列族的数据结构设计,实际上是把字段的名称和字段的值,以Key-Value的方式一起存储在HBase中。实际写入的时候,可以随意指定字段名称,即使有几百万个字段也能轻松应对。
|
|
|
|
|
|
|
|
|
|
|
|
## HBase的高性能存储
|
|
|
|
|
|
|
|
|
|
|
|
还记得专栏第5期讲RAID时我留给你的思考题吗?当时很多同学答得都很棒。传统的机械式磁盘的访问特性是**连续读写很快,随机读写很慢**。这是因为机械磁盘靠电机驱动访问磁盘上的数据,电机要将磁头落到数据所在的磁道上,这个过程需要较长的寻址时间。如果数据不连续存储,磁头就要不停地移动,浪费了大量的时间。
|
|
|
|
|
|
|
|
|
|
|
|
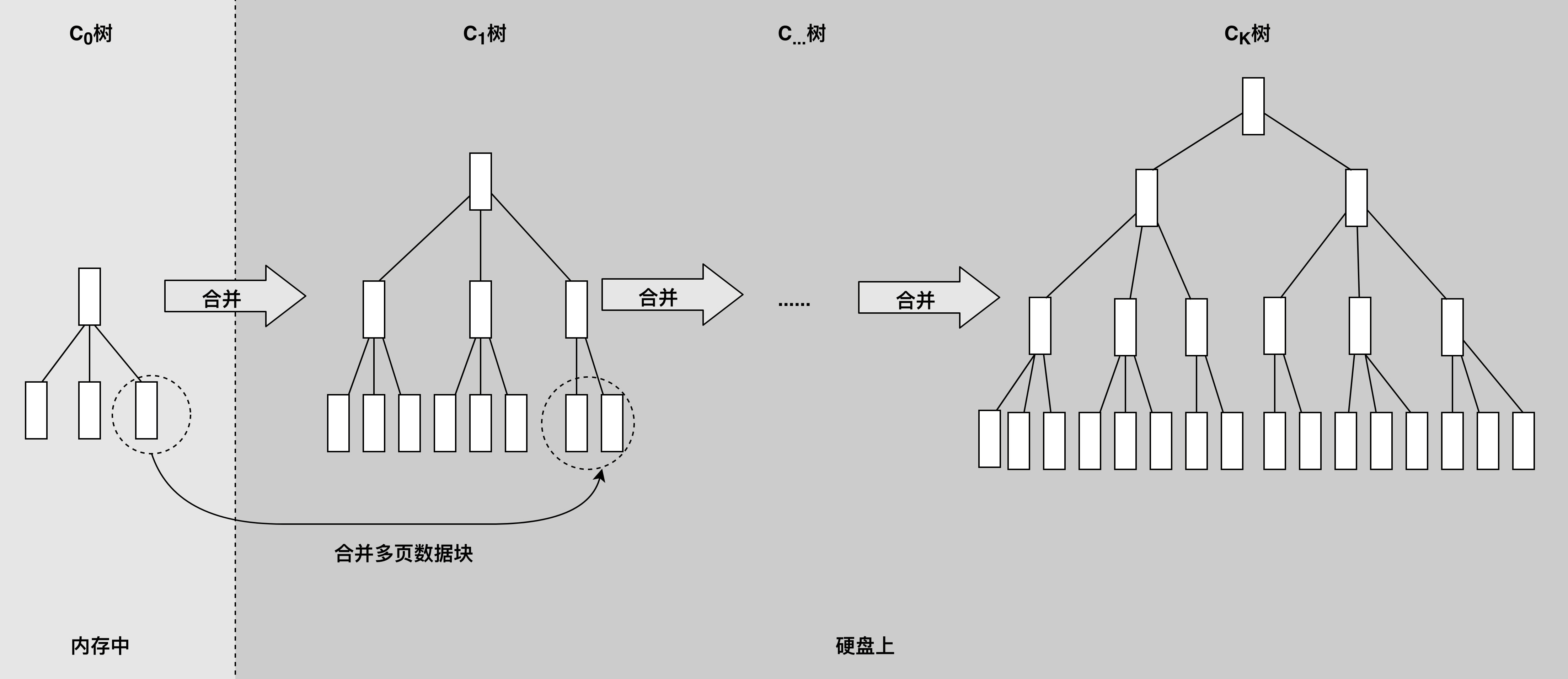
为了提高数据写入速度,HBase使用了一种叫作**LSM树**的数据结构进行数据存储。LSM树的全名是Log Structed Merge Tree,翻译过来就是Log结构合并树。数据写入的时候以Log方式连续写入,然后异步对磁盘上的多个LSM树进行合并。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
LSM树可以看作是一个N阶合并树。数据写操作(包括插入、修改、删除)都在内存中进行,并且都会创建一个新记录(修改会记录新的数据值,而删除会记录一个删除标志)。这些数据在内存中仍然还是一棵排序树,当数据量超过设定的内存阈值后,会将这棵排序树和磁盘上最新的排序树合并。当这棵排序树的数据量也超过设定阈值后,会和磁盘上下一级的排序树合并。合并过程中,会用最新更新的数据覆盖旧的数据(或者记录为不同版本)。
|
|
|
|
|
|
|
|
|
|
|
|
在需要进行读操作时,总是从内存中的排序树开始搜索,如果没有找到,就从磁盘 上的排序树顺序查找。
|
|
|
|
|
|
|
|
|
|
|
|
在LSM树上进行一次数据更新不需要磁盘访问,在内存即可完成。当数据访问以写操作为主,而读操作则集中在最近写入的数据上时,使用LSM树可以极大程度地减少磁盘的访问次数,加快访问速度。
|
|
|
|
|
|
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
|
|
|
|
|
|
最后,总结一下我们今天讲的内容。HBase作为Google BigTable的开源实现,完整地继承了BigTable的优良设计。架构上通过数据分片的设计配合HDFS,实现了数据的分布式海量存储;数据结构上通过列族的设计,实现了数据表结构可以在运行期自定义;存储上通过LSM树的方式,使数据可以通过连续写磁盘的方式保存数据,极大地提高了数据写入性能。
|
|
|
|
|
|
|
|
|
|
|
|
这些优良的设计结合Apache开源社区的高质量开发,使得HBase在NoSQL众多竞争产品中保持领先优势,逐步成为NoSQL领域最具影响力的产品。
|
|
|
|
|
|
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
|
|
|
|
|
|
HBase的列族数据结构虽然有灵活的优势,但是也有缺点。请你思考一下,列族结构的缺点有哪些?如何在应用开发的时候克服这些缺点?哪些场景最好还是使用MySQL这类关系数据库呢?
|
|
|
|
|
|
|
|
|
|
|
|
欢迎你写下自己的思考或疑问,与我和其他同学一起讨论。如果你学完今天的内容有所收获的话,也欢迎你点击“请朋友读”,把今天的文章分享给你的朋友。
|
|
|
|
|
|
|