721 lines
32 KiB
Markdown
721 lines
32 KiB
Markdown
|
|
# 14|自动化注入神器(一):sqlmap的设计思路解析
|
|||
|
|
|
|||
|
|
你好,我是王昊天。
|
|||
|
|
|
|||
|
|
从古至今,人们为了方便自己的生活,发明出各种各样的工具。就拿扫地来说,这是我小时候最讨厌的家务活动,因为扫地时扬起的灰尘会让我十分难受,而且有的死角很难被打扫干净。扫地机器人的出现给我们带来了极大的便利,我们只要拥有它,就不需要再亲自扫地了。
|
|||
|
|
|
|||
|
|
在前几节课中,我们学习了SQL注入的原理和方法,相信你已经小试牛刀了。不知道你在做注入测试的时候是否会觉得困难呢?反正我学的时候是遇到了不少困难,比如,绕过技巧多种多样,我们几乎不可能全部记住它们,就算记住了我们一一去尝试也需要很多的时间,费时又伤神。
|
|||
|
|
|
|||
|
|
就像我们刚才说过的,当问题出现时,我们常常会创造出一种工具,来解决对应的问题。那么有没有一款工具,能帮我们自动去进行注入测试呢?答案是肯定的,这个工具就是sqlmap。
|
|||
|
|
|
|||
|
|
这节课呢,我们正式开启sqlmap学习之旅,深入探究这款自动化注入神器的实现原理。**首先我们要对一些知识有所了解,包括如何获取软件的代码,如何搭建软件的运行环境,以及软件文件功能等。接下来,我们会对sqlmap的工作流程做一个整体的介绍,这会为我们后续学习sqlmap打好基础。**
|
|||
|
|
|
|||
|
|
## sqlmap
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
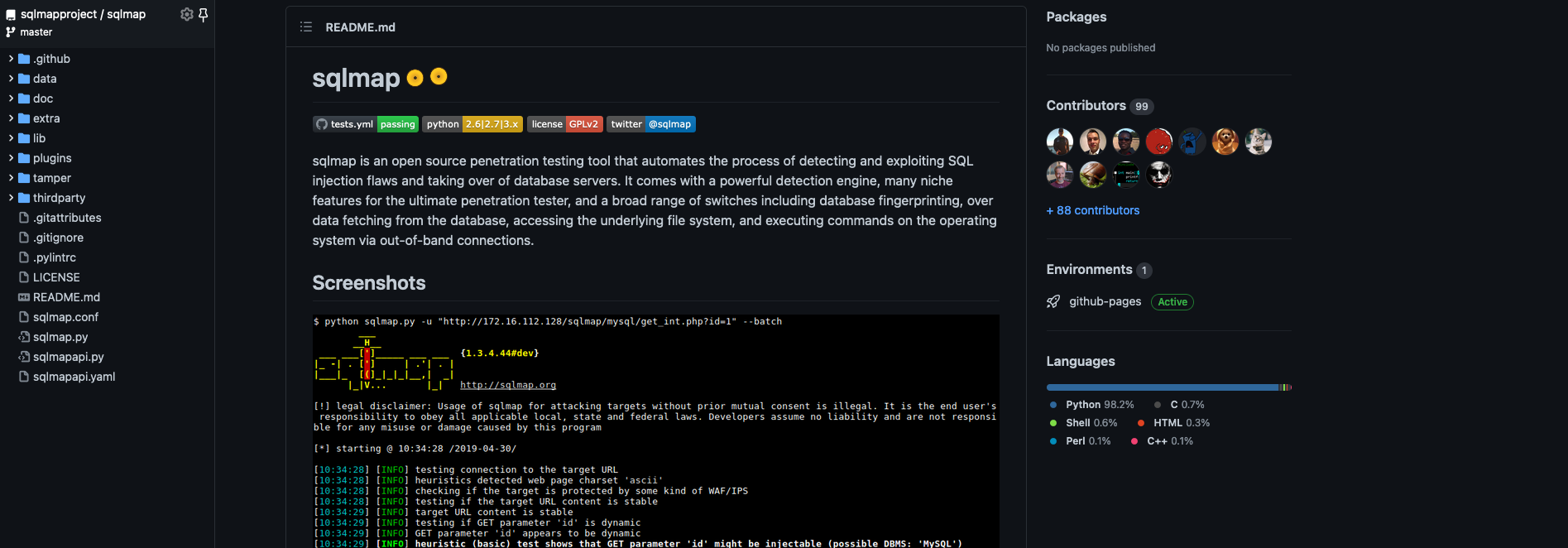
我们先来看看到底什么是sqlmap。
|
|||
|
|
|
|||
|
|
sqlmap是一个帮助我们自动检测sql注入是否存在的测试工具,它会使用不同注入方法进行测试,并将测试结果展示给我们,供我们利用。这些方法都是我们之前学过的内容,包括联合注入、时延注入、布尔盲注、报错注入和堆查询注入。如果你感兴趣,可以去上节课寻找更加详细的介绍。
|
|||
|
|
|
|||
|
|
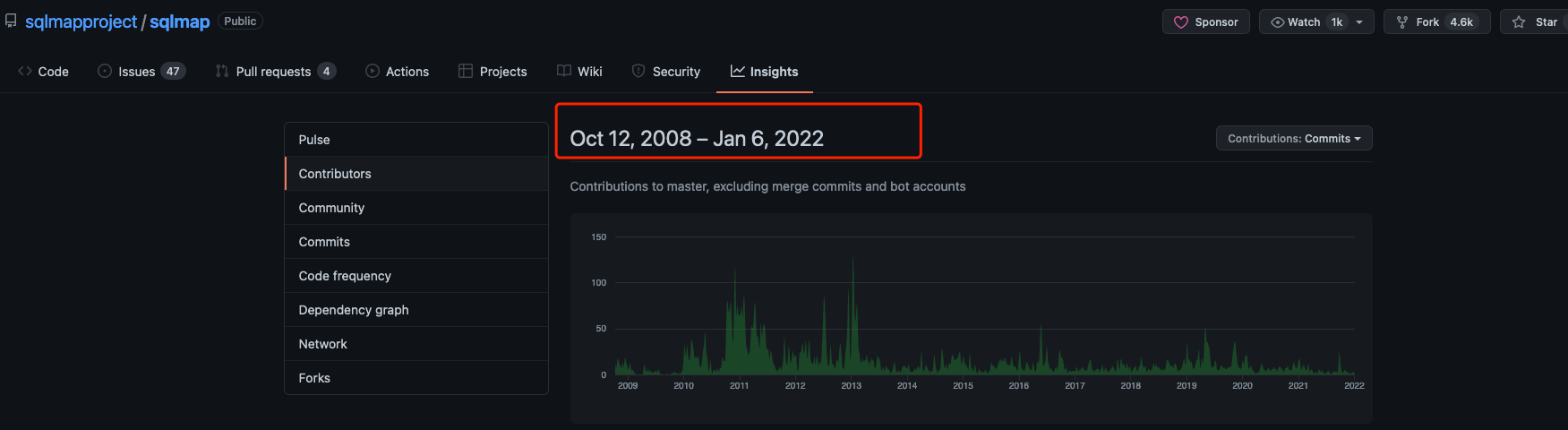
因为它的持续更新和维护,所以大家普遍认为它既方便又好用,从图片中我们可以看到超过4k的fork数量,以及高频的源码更新。就像一枚硬币的两面,这种优势也会伴随一些问题,比如给我们阅读源代码增加了难度,而我们要想真正去理解、掌握这款工具,就必须要迎难而上,对它的源代码进行剖析。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**代码获取**
|
|||
|
|
|
|||
|
|
我们用如下命令将sqlmap的源代码克隆下来。
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
git clone https://github.com/sqlmapproject/sqlmap
|
|||
|
|
cd sqlmap
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
因为该过程需要访问外网,所以克隆的速度会较为缓慢,当然我们可以借助一些代理工具来加速这个过程。
|
|||
|
|
|
|||
|
|
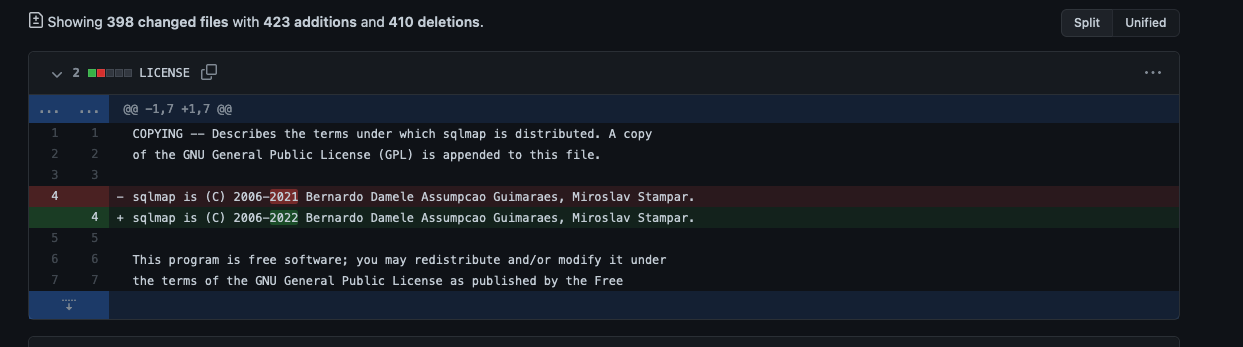
这里我们分析的sqlmap版本是最新的版本1.6,它于2022年初发布,相比于上一代1.5.12版本,只是修复了几个编码异常,并且替换版本信息,并没有什么重大的改动。因此学习两个大版本的代码都是可以的。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
在获取到源代码之后,我们还需要配置软件的运行环境,这样sqlmap才能顺利的运行。下面让我们进入到环境搭建这一步骤。
|
|||
|
|
|
|||
|
|
**环境搭建**
|
|||
|
|
|
|||
|
|
这节课,我们采用的分析环境是python3.10.1,可以利用下面的命令新建一个虚拟的解释环境,这样做有利于运行环境的隔离,防止其他环境因素干扰sqlmap的执行过程。
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
python3 -m venv venv
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**配置文件**
|
|||
|
|
|
|||
|
|
在做完环境搭建之后,sqlmap已经具有运行能力了。但是我们还需要知道哪个文件才是它的配置文件,即哪个文件会对它的运行产生影响。所以呢,接下来我们就来看看,sqlmap中有哪些重要的文件,它们又有哪些功能。
|
|||
|
|
|
|||
|
|
首先我们一起看下sqlmap的配置文件`sqlmap.conf`:
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# At least one of these options has to be specified to set the source to
|
|||
|
|
# get target URLs from.
|
|||
|
|
[Target]
|
|||
|
|
|
|||
|
|
# Target URL.
|
|||
|
|
# Example: http://192.168.1.121/sqlmap/mysql/get_int.php?id=1&cat=2
|
|||
|
|
url =
|
|||
|
|
|
|||
|
|
# Direct connection to the database.
|
|||
|
|
# Examples:
|
|||
|
|
# mysql://USER:PASSWORD@DBMS_IP:DBMS_PORT/DATABASE_NAME
|
|||
|
|
# oracle://USER:PASSWORD@DBMS_IP:DBMS_PORT/DATABASE_SID
|
|||
|
|
direct =
|
|||
|
|
|
|||
|
|
# Parse targets from Burp or WebScarab logs
|
|||
|
|
# Valid: Burp proxy (http://portswigger.net/suite/) requests log file path
|
|||
|
|
# or WebScarab proxy (http://www.owasp.org/index.php/Category:OWASP_WebScarab_Project)
|
|||
|
|
# 'conversations/' folder path
|
|||
|
|
logFile =
|
|||
|
|
|
|||
|
|
# Scan multiple targets enlisted in a given textual file
|
|||
|
|
bulkFile =
|
|||
|
|
|
|||
|
|
# Load HTTP request from a file
|
|||
|
|
# Example (file content): POST /login.jsp HTTP/1.1\nHost: example.com\nUser-Agent: Mozilla/4.0\n\nuserid=joe&password=guessme
|
|||
|
|
requestFile =
|
|||
|
|
|
|||
|
|
# At least one of these options has to be specified to set the source to
|
|||
|
|
# get target URLs from.
|
|||
|
|
[Target]
|
|||
|
|
|
|||
|
|
# Target URL.
|
|||
|
|
# Example: http://192.168.1.121/sqlmap/mysql/get_int.php?id=1&cat=2
|
|||
|
|
url =
|
|||
|
|
|
|||
|
|
# Direct connection to the database.
|
|||
|
|
# Examples:
|
|||
|
|
# mysql://USER:PASSWORD@DBMS_IP:DBMS_PORT/DATABASE_NAME
|
|||
|
|
# oracle://USER:PASSWORD@DBMS_IP:DBMS_PORT/DATABASE_SID
|
|||
|
|
direct =
|
|||
|
|
|
|||
|
|
# Parse targets from Burp or WebScarab logs
|
|||
|
|
# Valid: Burp proxy (http://portswigger.net/suite/) requests log file path
|
|||
|
|
# or WebScarab proxy (http://www.owasp.org/index.php/Category:OWASP_WebScarab_Project)
|
|||
|
|
# 'conversations/' folder path
|
|||
|
|
logFile =
|
|||
|
|
|
|||
|
|
# Scan multiple targets enlisted in a given textual file
|
|||
|
|
bulkFile =
|
|||
|
|
|
|||
|
|
# Load HTTP request from a file
|
|||
|
|
# Example (file content): POST /login.jsp HTTP/1.1\nHost: example.com\nUser-Agent: Mozilla/4.0\n\nuserid=joe&password=guessme
|
|||
|
|
requestFile =
|
|||
|
|
......
|
|||
|
|
# Force back-end DBMS operating system to provided value. If this option is
|
|||
|
|
|
|||
|
|
# set, the back-end DBMS identification process will be minimized as
|
|||
|
|
|
|||
|
|
# needed.
|
|||
|
|
|
|||
|
|
# If not set, sqlmap will detect back-end DBMS operating system
|
|||
|
|
|
|||
|
|
# automatically by default.
|
|||
|
|
|
|||
|
|
# Valid: linux, windows
|
|||
|
|
|
|||
|
|
os =
|
|||
|
|
......
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
由于配置文件很长,所以这里没有全部展示出来。我们需要知道的是,**配置文件的参数配置可以对sqlmap程序运行的流程产生影响**。举个例子,在配置文件中可以设置OS配置项,sqlmap就无需探测操作系统的类型了,这样就可以帮助我们在一些特定情况下优化sqlmap的执行速度。
|
|||
|
|
|
|||
|
|
看完配置文件之后,我们回忆一下之前学过的内容,在做SQL注入时,都需要经历哪些步骤呢?
|
|||
|
|
|
|||
|
|
我们知道,一般来说SQL注入攻击可以分为三步,首先是寻找注入点,之后要选择闭合参数的位置,最后要根据需求选择合适的payload,来实现我们的注入攻击操作。
|
|||
|
|
|
|||
|
|
sqlmap和手动SQL注入的思想是相似的,程序可以直接从请求的参数中获取到注入点位置的信息,而闭合参数的位置和payload的选择则会因为它们的多样性变得略微复杂,下面就让我们一起来看看与之相关的两个配置文件。
|
|||
|
|
|
|||
|
|
我们先来看sqlmap中闭合参数的配置内容,这里举个例子帮助你来理解什么是闭合参数。以一个典型的SQL注入语句为例:
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
SELECT id FROM users WHERE name = '$name';
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
想要对其进行注入,就需要将name参数闭合,这在前两节课中有过较深入的探讨。
|
|||
|
|
|
|||
|
|
对于sqlmap而言,data.xml.boundaries.xml就是用于闭合参数的配置文件,通过该文件我们可以确定闭合元素的字符和位置等等信息,了解该文件有助于我们理解sqlmap真正发送的测试payload的格式,关于payload格式这部分的内容我们会在下一讲具体的讲解。
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
<?xml version="1.0" encoding="UTF-8"?>
|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
Tag: <boundary>
|
|||
|
|
How to prepend and append to the test ' <payload><comment> ' string.
|
|||
|
|
|
|||
|
|
Sub-tag: <level>
|
|||
|
|
From which level check for this test.
|
|||
|
|
|
|||
|
|
Valid values:
|
|||
|
|
1: Always (<100 requests)
|
|||
|
|
2: Try a bit harder (100-200 requests)
|
|||
|
|
3: Good number of requests (200-500 requests)
|
|||
|
|
4: Extensive test (500-1000 requests)
|
|||
|
|
5: You have plenty of time (>1000 requests)
|
|||
|
|
|
|||
|
|
Sub-tag: <clause>
|
|||
|
|
In which clause the payload can work.
|
|||
|
|
|
|||
|
|
NOTE: for instance, there are some payload that do not have to be
|
|||
|
|
tested as soon as it has been identified whether or not the
|
|||
|
|
injection is within a WHERE clause condition.
|
|||
|
|
......
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
而关于payload这一部分,就让我们看一看sqlmap中payload的配置文件夹,`data.xml.payloads/`。这个文件夹储存有不同注入攻击类型的payload信息。
|
|||
|
|
|
|||
|
|
该文件夹下的每一个文件都与程序中一个重要的结构test息息相关,它是一个payload的基本信息单元,每个test里面包含了一个完整的payload需要的信息, sqlmap发送的攻击载荷就是在此基础上进行加工得出的,如下代码就是这个文件夹下的`boolean_blind.xml`文件的部分内容,这里我们选取了完整的test结构方便你了解。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
<test>
|
|||
|
|
|
|||
|
|
<title>AND boolean-based blind - WHERE or HAVING clause (MySQL comment)</title>
|
|||
|
|
|
|||
|
|
<stype>1</stype>
|
|||
|
|
|
|||
|
|
<level>3</level>
|
|||
|
|
|
|||
|
|
<risk>1</risk>
|
|||
|
|
|
|||
|
|
<clause>1</clause>
|
|||
|
|
|
|||
|
|
<where>1</where>
|
|||
|
|
|
|||
|
|
<vector>AND [INFERENCE]</vector>
|
|||
|
|
|
|||
|
|
<request>
|
|||
|
|
|
|||
|
|
<payload>AND [RANDNUM]=[RANDNUM]</payload>
|
|||
|
|
|
|||
|
|
<comment>#</comment>
|
|||
|
|
|
|||
|
|
</request>
|
|||
|
|
|
|||
|
|
<respons e>
|
|||
|
|
|
|||
|
|
<comparison>AND [RANDNUM]=[RANDNUM1]</comparison>
|
|||
|
|
|
|||
|
|
</response>
|
|||
|
|
|
|||
|
|
<details>
|
|||
|
|
|
|||
|
|
<dbms>MySQL</dbms>
|
|||
|
|
|
|||
|
|
</details>
|
|||
|
|
|
|||
|
|
</test>
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
可以看到它的结构内部定义攻击类型、方式、生效位置、关联数据库等等信息。
|
|||
|
|
至此,我们大致了解了sqlmap工作的底层依赖。下一步只需要分析和掌握sqlmap的运行过程,日后在使用中我们就可以更加得心应手。
|
|||
|
|
|
|||
|
|
sqlmap作为一个规模较大的工具,在启动过程中首先会执行一些初始化操作,下面就让我们一起学习sqlmap的初始化过程,通过这部分内容你可以明白sqlmap在启动之初做了哪些事情。
|
|||
|
|
|
|||
|
|
## 初始化过程
|
|||
|
|
|
|||
|
|
sqlmap的初始化过程包含四个步骤:环境初始化、命令行参数的解析、全局变量的赋值,以及运行环境的检查。我们将结合代码和图片注释,顺着sqlmap代码运行的顺序,详细讲述每一个步骤。下面让我们从环境初始化开始吧。
|
|||
|
|
|
|||
|
|
**环境初始化**
|
|||
|
|
|
|||
|
|
首先我们会发现,sqlmap的入口文件是sqlmap.py,这个文件的main如下所示:
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
if __name__ == "__main__":
|
|||
|
|
try:
|
|||
|
|
main()
|
|||
|
|
except KeyboardInterrupt:
|
|||
|
|
pass
|
|||
|
|
except SystemExit:
|
|||
|
|
raise
|
|||
|
|
except:
|
|||
|
|
traceback.print_exc()
|
|||
|
|
finally:
|
|||
|
|
if threading.active_count() > 1:
|
|||
|
|
os._exit(getattr(os, "_exitcode", 0))
|
|||
|
|
else:
|
|||
|
|
sys.exit(getattr(os, "_exitcode", 0))
|
|||
|
|
else:
|
|||
|
|
__import__("lib.controller.controller")
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
根据main函数的名字,我们可以知道,程序的核心逻辑一定被封装在了mian函数里面。因此,我们可以进入到mian函数里查看。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def main():
|
|||
|
|
try:
|
|||
|
|
dirtyPatches()
|
|||
|
|
resolveCrossReferences()
|
|||
|
|
checkEnvironment()
|
|||
|
|
setPaths(modulePath())
|
|||
|
|
banner()
|
|||
|
|
args = cmdLineParser()
|
|||
|
|
cmdLineOptions.update(args.__dict__ if hasattr(args, "__dict__") else args)
|
|||
|
|
initOptions(cmdLineOptions)
|
|||
|
|
if checkPipedInput():
|
|||
|
|
conf.batch = True
|
|||
|
|
if conf.get("api"):
|
|||
|
|
from lib.utils.api import StdDbOut
|
|||
|
|
from lib.utils.api import setRestAPILog
|
|||
|
|
sys.stdout = StdDbOut(conf.taskid, messagetype="stdout")
|
|||
|
|
sys.stderr = StdDbOut(conf.taskid, messagetype="stderr")
|
|||
|
|
setRestAPILog()
|
|||
|
|
conf.showTime = True
|
|||
|
|
dataToStdout("[!] legal disclaimer: %s\n\n" % LEGAL_DISCLAIMER, forceOutput=True)
|
|||
|
|
dataToStdout("[*] starting @ %s\n\n" % time.strftime("%X /%Y-%m-%d/"), forceOutput=True)
|
|||
|
|
init()
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
进入到mian函数之后我们就会发现,环境初始化初始化过程的代码就在这里,该过程引入了两个重要数据容器的映射conf和kb。他们都是全局的环境变量,是存储程序运行中间数据和信息数据的容器,其中sqlmap的结果信息、注入信息、控制信息都是通过它们进行读写来完成程序的执行的。这部分内容我们会在下节课展开。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
from lib.core.data import conf
|
|||
|
|
from lib.core.data import kb
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在这里,为了你更好地理解它们,我们先来看看这两个数据结构是什么,这里我们可以找到lib.core.data.py文件进行观察。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
# object to share within function and classes command
|
|||
|
|
|
|||
|
|
# line options and settings
|
|||
|
|
|
|||
|
|
conf = AttribDict()
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
# object to share within function and classes results
|
|||
|
|
|
|||
|
|
kb = AttribDict()
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
可以发现,这两个数据结构是作者自己封装的函数,封装的主要目的是实现深拷贝(`__deepcopy__` )这个魔法函数。通过这种方式,Python内容数据的拷贝操作会被大大优化。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
class AttribDict(dict):
|
|||
|
|
......
|
|||
|
|
def __deepcopy__(self, memo):
|
|||
|
|
|
|||
|
|
retVal = self.__class__()
|
|||
|
|
|
|||
|
|
memo[id(self)] = retVal
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
for attr in dir(self):
|
|||
|
|
|
|||
|
|
if not attr.startswith('_'):
|
|||
|
|
|
|||
|
|
value = getattr(self, attr)
|
|||
|
|
|
|||
|
|
if not isinstance(value, (types.BuiltinFunctionType, types.FunctionType, types.MethodType)):
|
|||
|
|
|
|||
|
|
setattr(retVal, attr, copy.deepcopy(value, memo))
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
for key, value in self.items():
|
|||
|
|
|
|||
|
|
retVal.__setitem__(key, copy.deepcopy(value, memo))
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
return retVal
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
接下来我们继续观察main函数。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
dirtyPatches() # 补丁函数
|
|||
|
|
resolveCrossReferences() # 消除交叉引用
|
|||
|
|
checkEnvironment() # 检查环境
|
|||
|
|
setPaths(modulePath()) # 如果使用py2exe 作为file获取程序路径的替代 设置绝对路径
|
|||
|
|
banner()
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们可以看到,程序在进入到try语句之后,首先会执行几个函数。
|
|||
|
|
|
|||
|
|
第一个函数是dirtyPatches() ,它是一个补丁函数。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def dirtyPatches():
|
|||
|
|
"""
|
|||
|
|
Place for "dirty" Python related patches
|
|||
|
|
"""
|
|||
|
|
# accept overly long result lines (e.g. SQLi results in HTTP header responses)
|
|||
|
|
_http_client._MAXLINE = 1 * 1024 * 1024
|
|||
|
|
# prevent double chunked encoding in case of sqlmap chunking (Note: Python3 does it automatically if 'Content-length' is missing)
|
|||
|
|
if six.PY3:
|
|||
|
|
if not hasattr(_http_client.HTTPConnection, "__send_output"):
|
|||
|
|
_http_client.HTTPConnection.__send_output = _http_client.HTTPConnection._send_output
|
|||
|
|
def _send_output(self, *args, **kwargs):
|
|||
|
|
if conf.get("chunked") and "encode_chunked" in kwargs:
|
|||
|
|
kwargs["encode_chunked"] = False
|
|||
|
|
self.__send_output(*args, **kwargs)
|
|||
|
|
_http_client.HTTPConnection._send_output = _send_output
|
|||
|
|
# add support for inet_pton() on Windows OS
|
|||
|
|
if IS_WIN:
|
|||
|
|
from thirdparty.wininetpton import win_inet_pton
|
|||
|
|
# Reference: https://github.com/nodejs/node/issues/12786#issuecomment-298652440
|
|||
|
|
codecs.register(lambda name: codecs.lookup("utf-8") if name == "cp65001" else None)
|
|||
|
|
# Reference: http://bugs.python.org/issue17849
|
|||
|
|
if hasattr(_http_client, "LineAndFileWrapper"):
|
|||
|
|
def _(self, *args):
|
|||
|
|
return self._readline()
|
|||
|
|
_http_client.LineAndFileWrapper._readline = _http_client.LineAndFileWrapper.readline
|
|||
|
|
_http_client.LineAndFileWrapper.readline = _
|
|||
|
|
# to prevent too much "guessing" in case of binary data retrieval
|
|||
|
|
thirdparty.chardet.universaldetector.MINIMUM_THRESHOLD = 0.90
|
|||
|
|
match = re.search(r" --method[= ](\w+)", " ".join(sys.argv))
|
|||
|
|
if match and match.group(1).upper() != PLACE.POST:
|
|||
|
|
PLACE.CUSTOM_POST = PLACE.CUSTOM_POST.replace("POST", "%s (body)" % match.group(1))
|
|||
|
|
# https://github.com/sqlmapproject/sqlmap/issues/4314
|
|||
|
|
try:
|
|||
|
|
os.urandom(1)
|
|||
|
|
except NotImplementedError:
|
|||
|
|
if six.PY3:
|
|||
|
|
os.urandom = lambda size: bytes(random.randint(0, 255) for _ in range(size))
|
|||
|
|
else:
|
|||
|
|
os.urandom = lambda size: "".join(chr(random.randint(0, 255)) for _ in xrange(size))
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
之所称它为补丁函数呢,是因为这个函数功能,主要用来处理sqlmap的一些历史信息。例如支持Python2升级Python3、支持Windows平台的inet\_pton()函数、限制httplib的最大行长度等等。这些操作对sqlmap的实际功能影响并不是特别大,属于保证用户体验和系统设置的正常选项,我们不需要过多关心。
|
|||
|
|
|
|||
|
|
接下来是resolveCrossReferences函数,它的作用是消除交叉引用。我们通过下面这个示例理解下什么是交叉引用。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
```python
|
|||
|
|
a.py
|
|||
|
|
from b import b_var
|
|||
|
|
a_var = 1
|
|||
|
|
b.py
|
|||
|
|
from a import a_var
|
|||
|
|
b_var = 2
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
这就是一个交叉引用的示例,文件`a.py`和`b.py`互相引用导致了运行的python解释器报错。为了避免交叉引用引起这样的问题,这里我们选择通过`resolveCrossReferences()`函数来消除交叉引用。
|
|||
|
|
```python
|
|||
|
|
def resolveCrossReferences():
|
|||
|
|
“””
|
|||
|
|
Place for cross-reference resolution
|
|||
|
|
“””
|
|||
|
|
lib.core.threads.isDigit = isDigit
|
|||
|
|
lib.core.threads.readInput = readInput
|
|||
|
|
lib.core.common.getPageTemplate = getPageTemplate
|
|||
|
|
lib.core.convert.filterNone = filterNone
|
|||
|
|
lib.core.convert.isListLike = isListLike
|
|||
|
|
lib.core.convert.shellExec = shellExec
|
|||
|
|
lib.core.convert.singleTimeWarnMessage = singleTimeWarnMessage
|
|||
|
|
lib.core.option._pympTempLeakPatch = pympTempLeakPatch
|
|||
|
|
lib.request.connect.setHTTPHandlers = _setHTTPHandlers
|
|||
|
|
lib.utils.search.setHTTPHandlers = _setHTTPHandlers
|
|||
|
|
lib.controller.checks.setVerbosity = setVerbosity
|
|||
|
|
lib.utils.sqlalchemy.getSafeExString = getSafeExString
|
|||
|
|
thirdparty.ansistrm.ansistrm.stdoutEncode = stdoutEncode
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
sqlmap在消除交叉引用之后,程序会开始运行检查环境的函数checkEnvironment()。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def checkEnvironment():
|
|||
|
|
try:
|
|||
|
|
os.path.isdir(modulePath())
|
|||
|
|
except UnicodeEncodeError:
|
|||
|
|
errMsg = “your system does not properly handle non-ASCII paths. “
|
|||
|
|
errMsg += “Please move the sqlmap’s directory to the other location”
|
|||
|
|
logger.critical(errMsg)
|
|||
|
|
raise SystemExit
|
|||
|
|
if LooseVersion(VERSION) < LooseVersion(“1.0”):
|
|||
|
|
errMsg = “your runtime environment (e.g. PYTHONPATH) is “
|
|||
|
|
errMsg += “broken. Please make sure that you are not running “
|
|||
|
|
errMsg += “newer versions of sqlmap with runtime scripts for older “
|
|||
|
|
errMsg += “versions”
|
|||
|
|
logger.critical(errMsg)
|
|||
|
|
raise SystemExit
|
|||
|
|
# Patch for pip (import) environment
|
|||
|
|
if “sqlmap.sqlmap” in sys.modules:
|
|||
|
|
for _ in (“cmdLineOptions”, “conf”, “kb”):
|
|||
|
|
globals()[_] = getattr(sys.modules[“lib.core.data”], _)
|
|||
|
|
for _ in (“SqlmapBaseException”, “SqlmapShellQuitException”, “SqlmapSilentQuitException”, “SqlmapUserQuitException”):
|
|||
|
|
globals()[_] = getattr(sys.modules[“lib.core.exception”], _)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
checkEnvironment函数会对当前的环境进行初步检查,检查的内容包括,存放sqlmap的路径是否包含非ASCII字符,以及sqlmap的版本是否小于1.0。
|
|||
|
|
|
|||
|
|
下一个函数`setPaths(modulePath())`是用来给项目中的文件夹和文件设置绝对路径的。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def setPaths(rootPath):
|
|||
|
|
"""
|
|||
|
|
Sets absolute paths for project directories and files
|
|||
|
|
"""
|
|||
|
|
paths.SQLMAP_ROOT_PATH = rootPath
|
|||
|
|
# sqlmap paths
|
|||
|
|
paths.SQLMAP_DATA_PATH = os.path.join(paths.SQLMAP_ROOT_PATH, "data")
|
|||
|
|
paths.SQLMAP_EXTRAS_PATH = os.path.join(paths.SQLMAP_ROOT_PATH, "extra")
|
|||
|
|
paths.SQLMAP_SETTINGS_PATH = os.path.join(paths.SQLMAP_ROOT_PATH, "lib", "core", "settings.py")
|
|||
|
|
paths.SQLMAP_TAMPER_PATH = os.path.join(paths.SQLMAP_ROOT_PATH, "tamper")
|
|||
|
|
paths.SQLMAP_PROCS_PATH = os.path.join(paths.SQLMAP_DATA_PATH, "procs")
|
|||
|
|
paths.SQLMAP_SHELL_PATH = os.path.join(paths.SQLMAP_DATA_PATH, "shell")
|
|||
|
|
paths.SQLMAP_TXT_PATH = os.path.join(paths.SQLMAP_DATA_PATH, "txt")
|
|||
|
|
paths.SQLMAP_UDF_PATH = os.path.join(paths.SQLMAP_DATA_PATH, "udf")
|
|||
|
|
paths.SQLMAP_XML_PATH = os.path.join(paths.SQLMAP_DATA_PATH, "xml")
|
|||
|
|
paths.SQLMAP_XML_BANNER_PATH = os.path.join(paths.SQLMAP_XML_PATH, "banner")
|
|||
|
|
paths.SQLMAP_XML_PAYLOADS_PATH = os.path.join(paths.SQLMAP_XML_PATH, "payloads")
|
|||
|
|
# sqlmap files
|
|||
|
|
paths.COMMON_COLUMNS = os.path.join(paths.SQLMAP_TXT_PATH, "common-columns.txt")
|
|||
|
|
paths.COMMON_FILES = os.path.join(paths.SQLMAP_TXT_PATH, "common-files.txt")
|
|||
|
|
paths.COMMON_TABLES = os.path.join(paths.SQLMAP_TXT_PATH, "common-tables.txt")
|
|||
|
|
paths.COMMON_OUTPUTS = os.path.join(paths.SQLMAP_TXT_PATH, 'common-outputs.txt')
|
|||
|
|
paths.SQL_KEYWORDS = os.path.join(paths.SQLMAP_TXT_PATH, "keywords.txt")
|
|||
|
|
paths.SMALL_DICT = os.path.join(paths.SQLMAP_TXT_PATH, "smalldict.txt")
|
|||
|
|
paths.USER_AGENTS = os.path.join(paths.SQLMAP_TXT_PATH, "user-agents.txt")
|
|||
|
|
paths.WORDLIST = os.path.join(paths.SQLMAP_TXT_PATH, "wordlist.tx_")
|
|||
|
|
paths.ERRORS_XML = os.path.join(paths.SQLMAP_XML_PATH, "errors.xml")
|
|||
|
|
paths.BOUNDARIES_XML = os.path.join(paths.SQLMAP_XML_PATH, "boundaries.xml")
|
|||
|
|
paths.QUERIES_XML = os.path.join(paths.SQLMAP_XML_PATH, "queries.xml")
|
|||
|
|
paths.GENERIC_XML = os.path.join(paths.SQLMAP_XML_BANNER_PATH, "generic.xml")
|
|||
|
|
paths.MSSQL_XML = os.path.join(paths.SQLMAP_XML_BANNER_PATH, "mssql.xml")
|
|||
|
|
paths.MYSQL_XML = os.path.join(paths.SQLMAP_XML_BANNER_PATH, "mysql.xml")
|
|||
|
|
paths.ORACLE_XML = os.path.join(paths.SQLMAP_XML_BANNER_PATH, "oracle.xml")
|
|||
|
|
paths.PGSQL_XML = os.path.join(paths.SQLMAP_XML_BANNER_PATH, "postgresql.xml")
|
|||
|
|
for path in paths.values():
|
|||
|
|
if any(path.endswith(_) for _ in (".txt", ".xml", ".tx_")):
|
|||
|
|
checkFile(path)
|
|||
|
|
if IS_WIN:
|
|||
|
|
# Reference: https://pureinfotech.com/list-environment-variables-windows-10/
|
|||
|
|
if os.getenv("LOCALAPPDATA"):
|
|||
|
|
paths.SQLMAP_HOME_PATH = os.path.expandvars("%LOCALAPPDATA%\\sqlmap")
|
|||
|
|
elif os.getenv("USERPROFILE"):
|
|||
|
|
paths.SQLMAP_HOME_PATH = os.path.expandvars("%USERPROFILE%\\Local Settings\\sqlmap")
|
|||
|
|
else:
|
|||
|
|
paths.SQLMAP_HOME_PATH = os.path.join(os.path.expandvars(os.path.expanduser("~")), "sqlmap")
|
|||
|
|
else:
|
|||
|
|
paths.SQLMAP_HOME_PATH = os.path.join(os.path.expandvars(os.path.expanduser("~")), ".sqlmap")
|
|||
|
|
if not os.path.isdir(paths.SQLMAP_HOME_PATH):
|
|||
|
|
if "XDG_DATA_HOME" in os.environ:
|
|||
|
|
paths.SQLMAP_HOME_PATH = os.path.join(os.environ["XDG_DATA_HOME"], "sqlmap")
|
|||
|
|
else:
|
|||
|
|
paths.SQLMAP_HOME_PATH = os.path.join(os.path.expandvars(os.path.expanduser("~")), ".local", "share", "sqlmap")
|
|||
|
|
paths.SQLMAP_OUTPUT_PATH = getUnicode(paths.get("SQLMAP_OUTPUT_PATH", os.path.join(paths.SQLMAP_HOME_PATH, "output")), encoding=sys.getfilesystemencoding() or UNICODE_ENCODING)
|
|||
|
|
paths.SQLMAP_DUMP_PATH = os.path.join(paths.SQLMAP_OUTPUT_PATH, "%s", "dump")
|
|||
|
|
paths.SQLMAP_FILES_PATH = os.path.join(paths.SQLMAP_OUTPUT_PATH, "%s", "files")
|
|||
|
|
# History files
|
|||
|
|
paths.SQLMAP_HISTORY_PATH = getUnicode(os.path.join(paths.SQLMAP_HOME_PATH, "history"), encoding=sys.getfilesystemencoding() or UNICODE_ENCODING)
|
|||
|
|
paths.API_SHELL_HISTORY = os.path.join(paths.SQLMAP_HISTORY_PATH, "api.hst")
|
|||
|
|
paths.OS_SHELL_HISTORY = os.path.join(paths.SQLMAP_HISTORY_PATH, "os.hst")
|
|||
|
|
paths.SQL_SHELL_HISTORY = os.path.join(paths.SQLMAP_HISTORY_PATH, "sql.hst")
|
|||
|
|
paths.SQLMAP_SHELL_HISTORY = os.path.join(paths.SQLMAP_HISTORY_PATH, "sqlmap.hst")
|
|||
|
|
paths.GITHUB_HISTORY = os.path.join(paths.SQLMAP_HISTORY_PATH, "github.hst")
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
设置完绝对路径后我们可以看到,sqlmap运行了一个banner函数,它对于sqlmap的运行没有实际的作用,但是作者可以通过banner函数绘制一幅字符画,是不是很酷!
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
下方是banner函数的代码,你在构建自己工具的时候也可以考虑引入这种有趣的小函数,为你的工具增添个性化色彩,让它看起来又酷又实用。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def banner():
|
|||
|
|
"""
|
|||
|
|
This function prints sqlmap banner with its version
|
|||
|
|
"""
|
|||
|
|
if not any(_ in sys.argv for _ in ("--version", "--api")) and not conf.get("disableBanner"):
|
|||
|
|
result = BANNER
|
|||
|
|
if not IS_TTY or any(_ in sys.argv for _ in ("--disable-coloring", "--disable-colouring")):
|
|||
|
|
result = clearColors(result)
|
|||
|
|
elif IS_WIN:
|
|||
|
|
coloramainit()
|
|||
|
|
dataToStdout(result, forceOutput=True)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**命令行参数解析**
|
|||
|
|
|
|||
|
|
经过上面的函数执行之后,基本环境已经配置好了,程序将开始处理用户的输入,包括有命令行参数以及配置的文件参数。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def main():
|
|||
|
|
"""
|
|||
|
|
Main function of sqlmap when running from command line.
|
|||
|
|
"""
|
|||
|
|
try:
|
|||
|
|
dirtyPatches()
|
|||
|
|
resolveCrossReferences()
|
|||
|
|
checkEnvironment()
|
|||
|
|
setPaths(modulePath())
|
|||
|
|
banner()
|
|||
|
|
# Store original command line options for possible later restoration
|
|||
|
|
args = cmdLineParser()
|
|||
|
|
cmdLineOptions.update(args.__dict__ if hasattr(args, "__dict__") else args)
|
|||
|
|
initOptions(cmdLineOptions)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**全局变量赋值与环境检查**
|
|||
|
|
|
|||
|
|
在接收用户的输入参数之后,程序开始进入init方法,这个方法是一个重要的前期配置方法,里面包含大量的配置操作,这些操作我们可以进入函数中观察。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
def init():
|
|||
|
|
_useWizardInterface() # 启动引导模式
|
|||
|
|
setVerbosity() # 设置默认的日志输出详细度
|
|||
|
|
_saveConfig() # 保存当前扫描的配置
|
|||
|
|
_setRequestFromFile() # 解析 request file 的文件内容
|
|||
|
|
_cleanupOptions() # 为 conf 中的参数赋初值
|
|||
|
|
_cleanupEnvironment()
|
|||
|
|
_purge() # 清空 sqlmap 相关信息
|
|||
|
|
_checkDependencies() # 检查是否缺失依赖
|
|||
|
|
_createHomeDirectories() # 创建 output、history 目录
|
|||
|
|
_createTemporaryDirectory() # 创建临时目录
|
|||
|
|
_basicOptionValidation() # 验证部分参数值是否符合预期
|
|||
|
|
_setProxyList() # 解析 proxy file 的文件内容
|
|||
|
|
_setTorProxySettings() # 设置 tor 代理
|
|||
|
|
_setDNSServer() # 创建 DNS 服务器
|
|||
|
|
_adjustLoggingFormatter() # 初始化日志格式化工具
|
|||
|
|
_setMultipleTargets() # 解析 burp log 的文件内容
|
|||
|
|
_listTamperingFunctions() # 输出 tamper 的详细信息
|
|||
|
|
_setTamperingFunctions() # 设置后续要调用的 tamper
|
|||
|
|
_setPreprocessFunctions() # 设置处理请求的函数
|
|||
|
|
_setPostprocessFunctions() # 设置处理响应的函数
|
|||
|
|
_setTrafficOutputFP() # 创建 trafficFile 并获取文件句柄
|
|||
|
|
_setupHTTPCollector() # 创建 HAR 文件
|
|||
|
|
_setHttpChunked() # 设置 chunked
|
|||
|
|
_checkWebSocket() # 检查 websocket 环境是否正常
|
|||
|
|
|
|||
|
|
parseTargetDirect() # 解析数据库链接
|
|||
|
|
|
|||
|
|
if any((conf.url, conf.logFile, conf.bulkFile, conf.requestFile, conf.googleDork, conf.stdinPipe)):
|
|||
|
|
_setHostname() # 设置 conf 中的 hostname
|
|||
|
|
_setHTTPTimeout() # 设置请求最大超时时间
|
|||
|
|
_setHTTPExtraHeaders() # 设置请求的 headers
|
|||
|
|
_setHTTPCookies() # 设置请求的 cookies
|
|||
|
|
_setHTTPReferer() # 设置请求的 referer
|
|||
|
|
_setHTTPHost() # 设置请求的 host
|
|||
|
|
_setHTTPUserAgent() # 设置请求的 UA
|
|||
|
|
_setHTTPAuthentication() # 设置请求的认证信息
|
|||
|
|
_setHTTPHandlers() # 设置对应的请求处理类
|
|||
|
|
_setDNSCache() # 设置 dns 缓存
|
|||
|
|
_setSocketPreConnect()
|
|||
|
|
_setSafeVisit()
|
|||
|
|
_doSearch() # 处理 Google Dork 解析
|
|||
|
|
_setStdinPipeTargets() # 从 pipeline 中获取 targets
|
|||
|
|
_setBulkMultipleTargets() # 从文本中获取 targets
|
|||
|
|
_checkTor() # 检查 tor 代理
|
|||
|
|
_setCrawler() # 设置爬虫信息
|
|||
|
|
_findPageForms() # 寻找页面中的表单
|
|||
|
|
_setDBMS() # 设置 DBMS
|
|||
|
|
_setTechnique() # 设置检测类型
|
|||
|
|
|
|||
|
|
_setThreads() # 设置线程数
|
|||
|
|
_setOS() # 设置操作系统类型
|
|||
|
|
_setWriteFile() # 设置文件写入信息
|
|||
|
|
_setMetasploit() # 设置 MSF 信息
|
|||
|
|
_setDBMSAuthentication() # 设置 DBMS 的认证信息
|
|||
|
|
loadBoundaries() # 加载 Boundaries
|
|||
|
|
loadPayloads() # 加载 Payloads
|
|||
|
|
_setPrefixSuffix() # 设置新的 prefix 和sufix
|
|||
|
|
update() # 更新 sqlmap
|
|||
|
|
_loadQueries() # 加载 queries
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
其实我们只需要根据后面的注释,了解每个函数大概实现的功能就可以了,它们有些与初始化配置文件相关,有些与实际攻击过程相关。实际上,这里只是会初步解析命令行传入的参数,并不涉及到大部分函数的调用过程,在这里我们不需要理解的很细致,我们的核心关注点应该在注入逻辑上。
|
|||
|
|
|
|||
|
|
```python
|
|||
|
|
init()
|
|||
|
|
if not conf.updateAll:
|
|||
|
|
# Postponed imports (faster start)
|
|||
|
|
if conf.smokeTest:
|
|||
|
|
from lib.core.testing import smokeTest
|
|||
|
|
os._exitcode = 1 - (smokeTest() or 0)
|
|||
|
|
elif conf.vulnTest:
|
|||
|
|
from lib.core.testing import vulnTest
|
|||
|
|
os._exitcode = 1 - (vulnTest() or 0)
|
|||
|
|
else:
|
|||
|
|
from lib.controller.controller import start
|
|||
|
|
if conf.profile:
|
|||
|
|
from lib.core.profiling import profile
|
|||
|
|
globals()["start"] = start
|
|||
|
|
profile()
|
|||
|
|
else:
|
|||
|
|
try:
|
|||
|
|
if conf.crawlDepth and conf.bulkFile:
|
|||
|
|
targets = getFileItems(conf.bulkFile)
|
|||
|
|
for i in xrange(len(targets)):
|
|||
|
|
target = None
|
|||
|
|
try:
|
|||
|
|
kb.targets = OrderedSet()
|
|||
|
|
target = targets[i]
|
|||
|
|
if not re.search(r"(?i)\Ahttp[s]*://", target)
|
|||
|
|
target = "http://%s" % target
|
|||
|
|
infoMsg = "starting crawler for target URL '%s' (%d/%d)" % (target, i + 1, len(targets))
|
|||
|
|
logger.info(infoMsg)
|
|||
|
|
crawl(target)
|
|||
|
|
except Exception as ex:
|
|||
|
|
if target and not isinstance(ex, SqlmapUserQuitException):
|
|||
|
|
errMsg = "problem occurred while crawling '%s' ('%s')" % (target, getSafeExString(ex))
|
|||
|
|
logger.error(errMsg)
|
|||
|
|
else:
|
|||
|
|
raise
|
|||
|
|
else:
|
|||
|
|
if kb.targets:
|
|||
|
|
start()
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
学习完毕init方法之后,我们就完成了整个初始化过程。
|
|||
|
|
|
|||
|
|
## 总结
|
|||
|
|
|
|||
|
|
这节课,我们学习了自动化SQL注入测试工具–sqlmap的设计思路。
|
|||
|
|
|
|||
|
|
作为业内知名且常用的SQL自动化注入工具,sqlmap已经持续维护了超过10年的时间。作为有梦想的工程师,我们不仅需要掌握如何使用sqlmap,更要学习它的设计思想和工作原理,站在巨人的肩膀上才能帮助我们看的更远。
|
|||
|
|
|
|||
|
|
sqlmap的代码量十分庞大,因为掌握其核心设计思想和工作原理就十分重要,这会成为我们深入代码逻辑探索的风向标。因此,在了解如何获取sqlmap代码以及如何搭建sqlmap的运行环境后,我们进一步学习了sqlmap设计原理的相关知识,比如sqlmap的配置文件介绍等。
|
|||
|
|
|
|||
|
|
接下来,与大部分开源软件的设计思路类似,sqlmap在真正开始工作前需要做大量的初始化工作,因此我们对sqlmap的初始化流程进行了梳理。经过分析,总结出它主要包含有全局变量初始化、命令行参数解析、全局变量赋值以及环境检查这四个通用的初始化步骤,然后我们又具体学习了这四个流程是如何实现的。
|
|||
|
|
|
|||
|
|
在学习完sqlmap的初始化后,很快我们就会进入sqlmap的工作流程学习,这时我们需要重新审视sqlmap的设计架构,了解我们所处的位置。
|
|||
|
|
|
|||
|
|
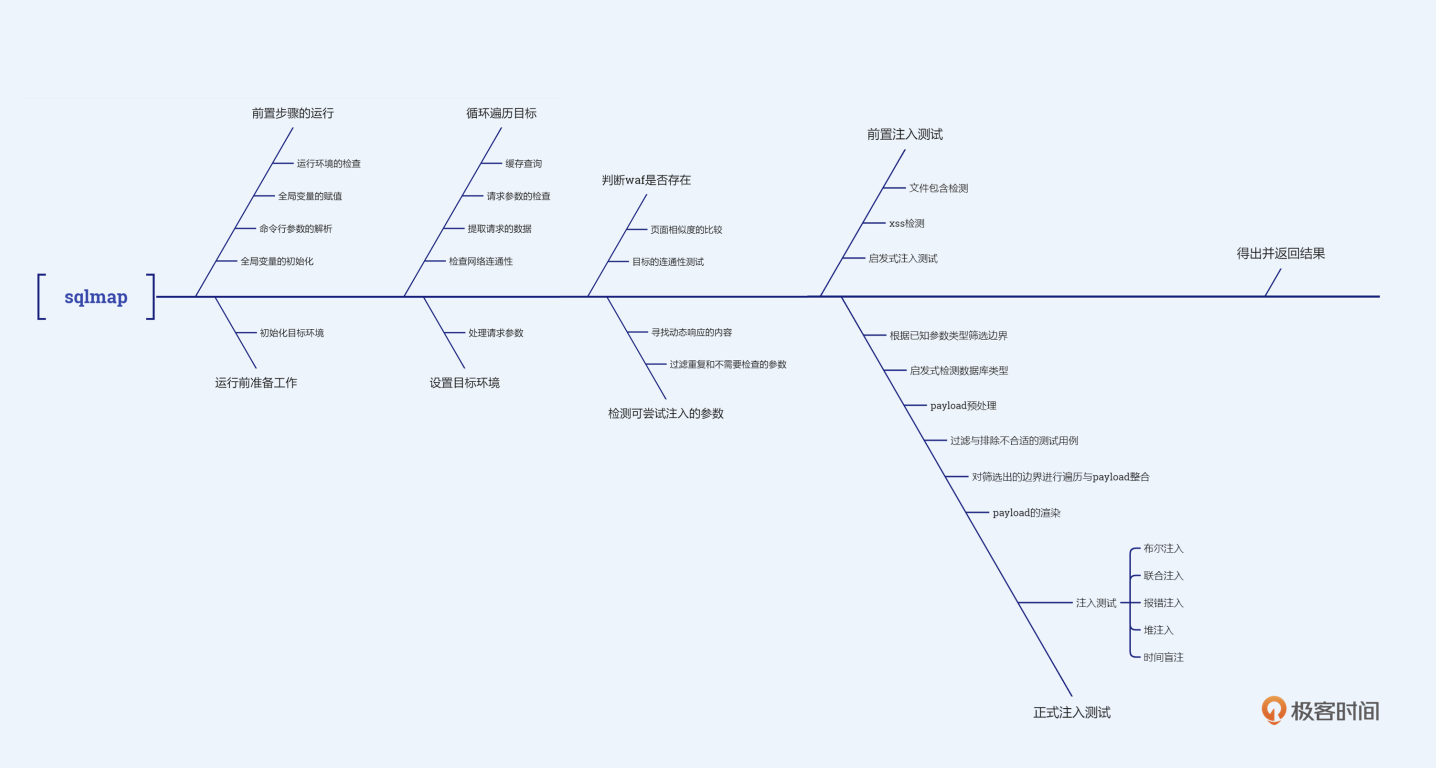
|
|||
|
|
|
|||
|
|
这是我整理的一幅sqlmap工作原理图,在本节课我们学习了sqlmap工作前的初始化流程,这些内容可以帮助你认识到sqlmap设计时的底层逻辑。下节课我们将正式开始学习sqlmap的自动化注入功能,它的起点是预注入,也是我们在前几节课程中所讲的起手式阶段。
|
|||
|
|
|
|||
|
|
## 思考
|
|||
|
|
|
|||
|
|
sqlmap的初始化流程有什么值得改进的地方吗?
|
|||
|
|
|
|||
|
|
欢迎在评论区留下你的思考,我们下节课再见。
|
|||
|
|
|