412 lines
25 KiB
Markdown
412 lines
25 KiB
Markdown
|
|
# 17 | Lazy Free会影响缓存替换吗?
|
|||
|
|
|
|||
|
|
你好,我是蒋德钧。
|
|||
|
|
|
|||
|
|
Redis缓存淘汰算法的目的,其实是为了在Redis server内存使用量超过上限值的时候,筛选一些冷数据出来,把它们从Redis server中删除,以保证server的内存使用量不超出上限。我们在前两节课,已经分别学习了Redis源码对LRU算法和LFU算法的实现,这两种算法在最后淘汰数据的时候,都会删除被淘汰的数据。
|
|||
|
|
|
|||
|
|
不过,无论是LRU算法还是LFU算法,它们在删除淘汰数据时,实际上都会根据Redis server的**lazyfree-lazy-eviction配置项**,来决定是否使用Lazy Free,也就是惰性删除。
|
|||
|
|
|
|||
|
|
惰性删除是Redis 4.0版本后提供的功能,它会使用后台线程来执行删除数据的任务,从而避免了删除操作对主线程的阻塞。但是,**后台线程异步删除数据能及时释放内存吗?它会影响到Redis缓存的正常使用吗?**
|
|||
|
|
|
|||
|
|
今天这节课,我就来给你介绍下惰性删除在缓存淘汰时的应用。了解这部分内容,你就可以掌握惰性删除启用后,会给Redis缓存淘汰和内存释放带来的可能影响。这样,当你在实际应用中,遇到Redis缓存内存容量的问题时,你就多了一条排查思路了。
|
|||
|
|
|
|||
|
|
好,那么接下来,我们就先来看下缓存淘汰时的数据删除的基本过程。不过在了解这个删除过程之前,我们需要先了解下Redis server启动惰性删除的配置。因为在Redis源码中,有不少地方都会根据server是否启动惰性删除,来执行不同的分支操作。
|
|||
|
|
|
|||
|
|
## 惰性删除的设置
|
|||
|
|
|
|||
|
|
首先,当Redis server希望启动惰性删除时,需要在redis.conf文件中设置和惰性删除相关的配置项。其中包括了四个配置项,分别对应了如下的四种场景。
|
|||
|
|
|
|||
|
|
* **lazyfree-lazy-eviction**:对应缓存淘汰时的数据删除场景。
|
|||
|
|
* **lazyfree-lazy-expire**:对应过期key的删除场景。
|
|||
|
|
* **lazyfree-lazy-server-del**:对应会隐式进行删除操作的server命令执行场景。
|
|||
|
|
* **replica-lazy-flush**:对应从节点完成全量同步后,删除原有旧数据的场景。
|
|||
|
|
|
|||
|
|
这四个配置项的默认值都是no。所以,如果要在缓存淘汰时启用,就需要将
|
|||
|
|
|
|||
|
|
lazyfree-lazy-eviction设置为yes。同时,Redis server在启动过程中进行配置参数初始化时,会根据redis.conf的配置信息,设置全局变量server的lazyfree\_lazy\_eviction成员变量。
|
|||
|
|
|
|||
|
|
这样一来,我们在Redis源码中,如果看到对server.lazyfree\_lazy\_eviction变量值进行条件判断,那其实就是Redis根据lazyfree-lazy-eviction配置项,来决定是否执行惰性删除。
|
|||
|
|
|
|||
|
|
好了,了解了如何在缓存淘汰场景中设置惰性删除之后,接下来,我们就来看下被淘汰数据的删除过程。
|
|||
|
|
|
|||
|
|
## 被淘汰数据的删除过程
|
|||
|
|
|
|||
|
|
其实通过前两节课程的学习,我们已经知道,Redis源码中的freeMemoryIfNeeded函数(在[evict.c](https://github.com/redis/redis/tree/5.0/src/evict.c)文件中)会负责执行数据淘汰的流程。而该函数在筛选出被淘汰的键值对后,就要开始删除被淘汰的数据,这个删除过程主要分成两步。
|
|||
|
|
|
|||
|
|
**第一步**,freeMemoryIfNeeded函数会为被淘汰的key创建一个SDS对象,然后调用propagateExpire函数,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int freeMemoryIfNeeded(void) {
|
|||
|
|
…
|
|||
|
|
if (bestkey) {
|
|||
|
|
db = server.db+bestdbid;
|
|||
|
|
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
|
|||
|
|
propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);
|
|||
|
|
…
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
propagateExpire函数是在[db.c](https://github.com/redis/redis/tree/5.0/src/db.c)文件中实现的。它会先创建一个redisObject结构体数组,该数组的第一个元素是删除操作对应的命令对象,而第二个元素是被删除的key对象。因为Redis server可能针对缓存淘汰场景启用了惰性删除,所以,**propagateExpire函数会根据全局变量server的lazyfree\_lazy\_eviction成员变量的值,来决定删除操作具体对应的是哪个命令。**
|
|||
|
|
|
|||
|
|
如果lazyfree\_lazy\_eviction被设置为1,也就是启用了缓存淘汰时的惰性删除,那么,删除操作对应的命令就是UNLINK;否则的话,命令就是DEL。因为这些命令会被经常使用,所以Redis源码中会为这些命令创建共享对象。这些共享对象的数据结构是sharedObjectsStruct结构体,并用一个全局变量shared来表示。在该结构体中包含了指向共享对象的指针,这其中就包括了unlink和del命令对象。
|
|||
|
|
|
|||
|
|
以下代码展示了shared全局变量的定义以及sharedObjectsStruct结构体的定义,其中,shared变量是在[server.c](https://github.com/redis/redis/tree/5.0/src/server.c)文件中定义的,而sharedObjectsStruct结构体是在[server.h](https://github.com/redis/redis/tree/5.0/src/server.h)中定义的。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
struct sharedObjectsStruct shared;
|
|||
|
|
|
|||
|
|
struct sharedObjectsStruct {
|
|||
|
|
...
|
|||
|
|
robj *del, *unlink,
|
|||
|
|
...
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
然后,propagateExpire函数在为删除操作创建命令对象时,就使用了shared变量中的unlink或del对象,这部分代码如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
void propagateExpire(redisDb *db, robj *key, int lazy) {
|
|||
|
|
robj *argv[2];
|
|||
|
|
|
|||
|
|
argv[0] = lazy ? shared.unlink : shared.del; //如果server启用了lazyfree-lazy-evict,那么argv[0]的值为unlink对象,否则为del对象
|
|||
|
|
argv[1] = key; //被淘汰的key对象
|
|||
|
|
...
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
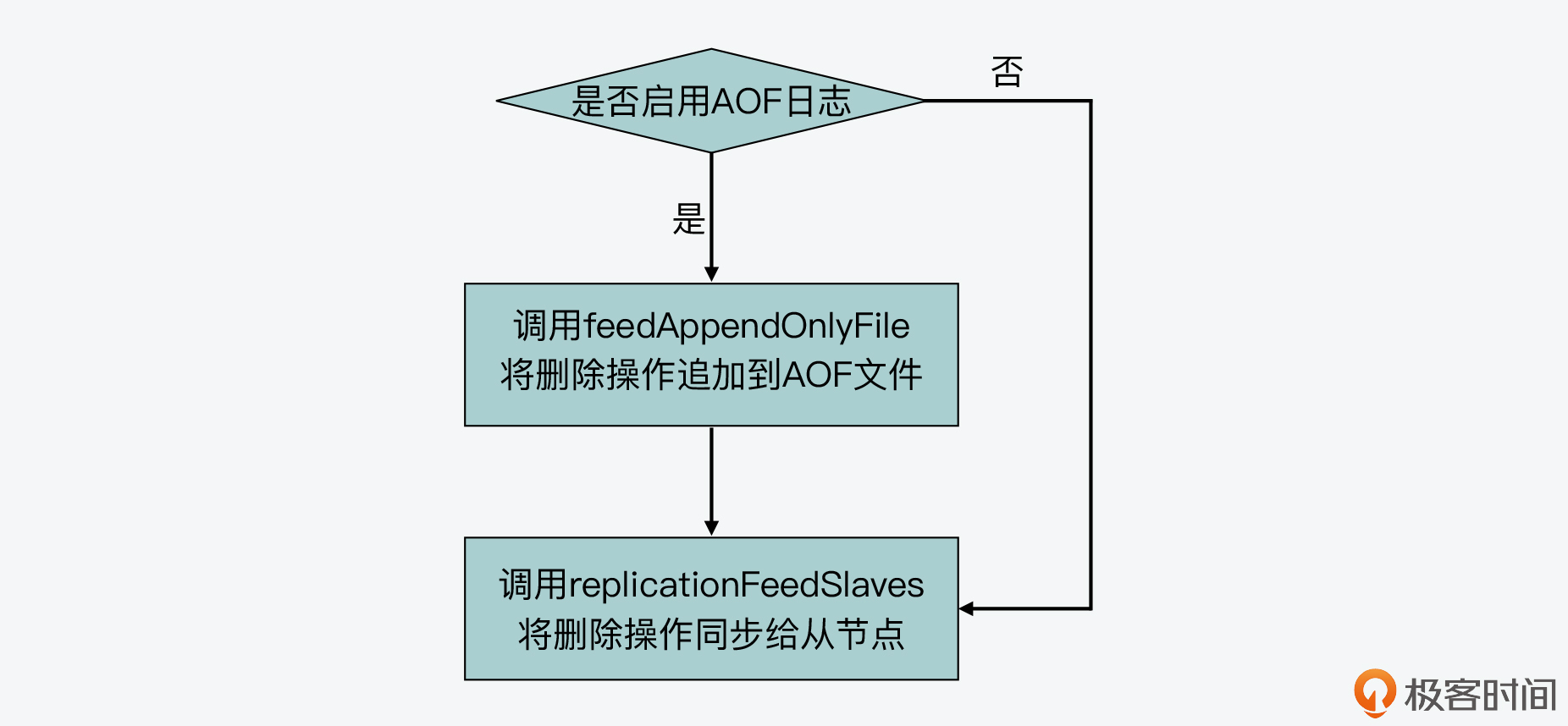
紧接着,propagateExpire函数会判断Redis server是否启用了AOF日志。如果启用了,那么propagateExpire函数会先把被淘汰key的删除操作记录到AOF文件中,以保证后续使用AOF文件进行Redis数据库恢复时,可以和恢复前保持一致。这一步是通过调用feedAppendOnlyFile函数(在[aof.c](https://github.com/redis/redis/tree/5.0/src/aof.c)文件中)来实现的。
|
|||
|
|
|
|||
|
|
然后,propagateExpire函数会调用replicationFeedSlaves函数(在[replication.c](https://github.com/redis/redis/tree/5.0/src/replication.c)文件中),把删除操作同步给从节点,以保证主从节点的数据一致。
|
|||
|
|
|
|||
|
|
下面代码展示了propagateExpire函数的基本流程,你可以看下。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
…
|
|||
|
|
//如果启用了AOF日志,则将删除操作写入AOF文件
|
|||
|
|
if (server.aof_state != AOF_OFF)
|
|||
|
|
feedAppendOnlyFile(server.delCommand,db->id,argv,2);
|
|||
|
|
//将删除操作同步给从节点
|
|||
|
|
replicationFeedSlaves(server.slaves,db->id,argv,2);
|
|||
|
|
…
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
为了便于你更直观地理解这个流程,我也画了一张图,你可以参考下。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
这样接下来,freeMemoryIfNeeded函数就会开始执行删除操作。
|
|||
|
|
|
|||
|
|
**第二步**,freeMemoryIfNeeded函数会根据server是否启用了惰性删除,分别执行两个分支。
|
|||
|
|
|
|||
|
|
* 分支一:如果server启用了惰性删除,freeMemoryIfNeeded函数会调用dbAsyncDelete函数进行异步删除。
|
|||
|
|
* 分支二:如果server未启用惰性删除,freeMemoryIfNeeded函数会调用dbSyncDelete函数进行同步删除。
|
|||
|
|
|
|||
|
|
而无论是执行异步删除还是同步删除,freeMemoryIfNeeded函数都会在调用删除函数前,调用**zmalloc\_used\_memory函数**(在[zmalloc.c](http://github.com/redis/redis/tree/5.0/src/zmalloc.c)文件中)计算当前使用的内存量。然后,它在调用删除函数后,会再次调用zmalloc\_used\_memory函数计算此时的内存使用量,并计算删除操作导致的内存使用量差值,这个差值就是通过删除操作而被释放的内存量。
|
|||
|
|
|
|||
|
|
所以,freeMemoryIfNeeded函数最后会把这部分释放的内存量和已释放的内存量相加,得到最新的内存释放量。这部分的执行逻辑如以下代码所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
delta = (long long) zmalloc_used_memory(); //获取当前内存使用量
|
|||
|
|
if (server.lazyfree_lazy_eviction)
|
|||
|
|
dbAsyncDelete(db,keyobj); //如果启用了惰性删除,则进行异步删除
|
|||
|
|
else
|
|||
|
|
dbSyncDelete(db,keyobj); //否则,进行同步删除
|
|||
|
|
delta -= (long long) zmalloc_used_memory(); //根据当前内存使用量计算数据删除前后释放的内存量
|
|||
|
|
mem_freed += delta; //更新已释放的内存量
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
所以到这里,我们就知道了freeMemoryIfNeeded函数在选定被删除的键值对后,可以通过异步或同步操作来完成数据的实际删除。那么,**数据异步删除和同步删除具体又是如何执行的呢?**
|
|||
|
|
|
|||
|
|
下面,我们就来具体了解下。
|
|||
|
|
|
|||
|
|
## 数据删除操作
|
|||
|
|
|
|||
|
|
在学习数据异步或同步删除之前,你首先需要知道,删除操作实际上是包括了两步子操作。
|
|||
|
|
|
|||
|
|
* 子操作一:将被淘汰的键值对从哈希表中去除,这里的哈希表既可能是设置了过期key的哈希表,也可能是全局哈希表。
|
|||
|
|
* 子操作二:释放被淘汰键值对所占用的内存空间。
|
|||
|
|
|
|||
|
|
也就是说,如果这两个子操作一起做,那么就是**同步删除**;如果只做了子操作一,而子操作二由后台线程来执行,那么就是**异步删除**。
|
|||
|
|
|
|||
|
|
那么对于Redis源码来说,它是使用了**dictGenericDelete函数**,来实现前面介绍的这两个子操作。dictGenericDelete函数是在dict.c文件中实现的,下面我们就来了解下它的具体执行过程。
|
|||
|
|
|
|||
|
|
**首先,dictGenericDelete函数会先在哈希表中查找要删除的key。**它会计算被删除key的哈希值,然后根据哈希值找到key所在的哈希桶。
|
|||
|
|
|
|||
|
|
因为不同key的哈希值可能相同,而Redis的哈希表是采用了链式哈希(你可以回顾下[第3讲](https://time.geekbang.org/column/article/400379)中介绍的链式哈希),所以即使我们根据一个key的哈希值,定位到了它所在的哈希桶,我们也仍然需要在这个哈希桶中去比对查找,这个key是否真的存在。
|
|||
|
|
|
|||
|
|
也正是由于这个原因,dictGenericDelete函数紧接着就会在哈希桶中,进一步比对查找要删除的key。如果找到了,它就先把这个key从哈希表中去除,也就是把这个key从哈希桶的链表中去除。
|
|||
|
|
|
|||
|
|
**然后,dictGenericDelete函数会根据传入参数nofree的值,决定是否实际释放key和value的内存空间。**dictGenericDelete函数中的这部分执行逻辑如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
h = dictHashKey(d, key); //计算key的哈希值
|
|||
|
|
for (table = 0; table <= 1; table++) {
|
|||
|
|
idx = h & d->ht[table].sizemask; //根据key的哈希值获取它所在的哈希桶编号
|
|||
|
|
he = d->ht[table].table[idx]; //获取key所在哈希桶的第一个哈希项
|
|||
|
|
prevHe = NULL;
|
|||
|
|
while(he) { //在哈希桶中逐一查找被删除的key是否存在
|
|||
|
|
if (key==he->key || dictCompareKeys(d, key, he->key)) {
|
|||
|
|
//如果找见被删除key了,那么将它从哈希桶的链表中去除
|
|||
|
|
if (prevHe)
|
|||
|
|
prevHe->next = he->next;
|
|||
|
|
else
|
|||
|
|
d->ht[table].table[idx] = he->next;
|
|||
|
|
if (!nofree) { //如果要同步删除,那么就释放key和value的内存空间
|
|||
|
|
dictFreeKey(d, he); //调用dictFreeKey释放
|
|||
|
|
dictFreeVal(d, he);
|
|||
|
|
zfree(he);
|
|||
|
|
}
|
|||
|
|
d->ht[table].used--;
|
|||
|
|
return he;
|
|||
|
|
}
|
|||
|
|
prevHe = he;
|
|||
|
|
he = he->next; //当前key不是要查找的key,再找下一个
|
|||
|
|
}
|
|||
|
|
...
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
那么,从dictGenericDelete函数的实现中,你可以发现,dictGenericDelete函数实际上会根据nofree参数,来决定执行的是同步删除还是异步删除。而Redis源码在dictGenericDelete函数的基础上,还封装了**两个函数dictDelete和dictUnlink**。
|
|||
|
|
|
|||
|
|
这两个函数的区别就在于,它们给dictGenericDelete函数传递的nofree参数值是0,还是1。如果其中nofree的值为0,表示的就是同步删除,而nofree值为1,表示的则是异步删除。
|
|||
|
|
|
|||
|
|
下面的代码展示了dictGenericDelete函数原型,以及dictDelete和dictUnlink两个函数的实现,你可以看下。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
//dictGenericDelete函数原型,参数是待查找的哈希表,待查找的key,以及同步/异步删除标记
|
|||
|
|
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree)
|
|||
|
|
|
|||
|
|
//同步删除函数,传给dictGenericDelete函数的nofree值为0
|
|||
|
|
int dictDelete(dict *ht, const void *key) {
|
|||
|
|
return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
//异步删除函数,传给dictGenericDelete函数的nofree值为1
|
|||
|
|
dictEntry *dictUnlink(dict *ht, const void *key) {
|
|||
|
|
return dictGenericDelete(ht,key,1);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
好了,到这里,我们就了解了同步删除和异步删除的基本代码实现。下面我们就再来看下,在刚才介绍的freeMemoryIfNeeded函数中,它在删除键值对时,所调用的dbAsyncDelete和dbSyncDelete这两个函数,是如何使用dictDelete和dictUnlink来实际删除被淘汰数据的。
|
|||
|
|
|
|||
|
|
### 基于异步删除的数据淘汰
|
|||
|
|
|
|||
|
|
我们先来看下基于异步删除的数据淘汰过程。这个过程是由**dbAsyncDelete函数**执行的,它是在[lazyfree.c](http://github.com/redis/redis/tree/5.0/src/lazyfree.c)文件中实现的。而这个函数的执行逻辑其实并不复杂,主要可以分成三步。
|
|||
|
|
|
|||
|
|
**第一步**,dbAsyncDelete函数会调用dictDelete函数,在过期key的哈希表中同步删除被淘汰的键值对,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**第二步**,dbAsyncDelete函数会调用dictUnlink函数,在全局哈希表中异步删除被淘汰的键值对,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
dictEntry *de = dictUnlink(db->dict,key->ptr);
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
而到这里,被淘汰的键值对只是在全局哈希表中被移除了,它占用的内存空间还没有实际释放。所以此时,dbAsyncDelete函数会**调用lazyfreeGetFreeEffort函数,来计算释放被淘汰键值对内存空间的开销**。如果开销较小,dbAsyncDelete函数就直接在主IO线程中进行同步删除了。否则的话,dbAsyncDelete函数会创建惰性删除任务,并交给后台线程来完成。
|
|||
|
|
|
|||
|
|
这里,你需要注意的是,虽然dbAsyncDelete函数说是执行惰性删除,但其实,它在实际执行的过程中,会使用前面提到的这个lazyfreeGetFreeEffort函数来评估删除开销。
|
|||
|
|
|
|||
|
|
lazyfreeGetFreeEffort函数是在lazyfree.c文件中实现的,它对删除开销的评估逻辑很简单,就是根据**要删除的键值对的类型**,来计算删除开销。当键值对类型属于List、Hash、Set和Sorted Set这四种集合类型中的一种,并且没有使用紧凑型内存结构来保存的话,那么,这个键值对的删除开销就等于集合中的元素个数。否则的话,删除开销就等于1。
|
|||
|
|
|
|||
|
|
我举个简单的例子,以下代码就展示了lazyfreeGetFreeEffort函数,计算List和Set类型键值对的删除开销。可以看到,当键值对是Set类型,同时它是使用哈希表结构而不是整数集合来保存数据的话,那么它的删除开销就是Set中的元素个数。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
size_t lazyfreeGetFreeEffort(robj *obj) {
|
|||
|
|
if (obj->type == OBJ_LIST) { //如果是List类型键值对,就返回List的长度,也就其中元素个数
|
|||
|
|
quicklist *ql = obj->ptr;
|
|||
|
|
return ql->len;
|
|||
|
|
} else if (obj->type == OBJ_SET && obj->encoding == OBJ_ENCODING_HT) {
|
|||
|
|
dict *ht = obj->ptr;
|
|||
|
|
return dictSize(ht); //如果是Set类型键值对,就返回Set中的元素个数
|
|||
|
|
}
|
|||
|
|
...
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
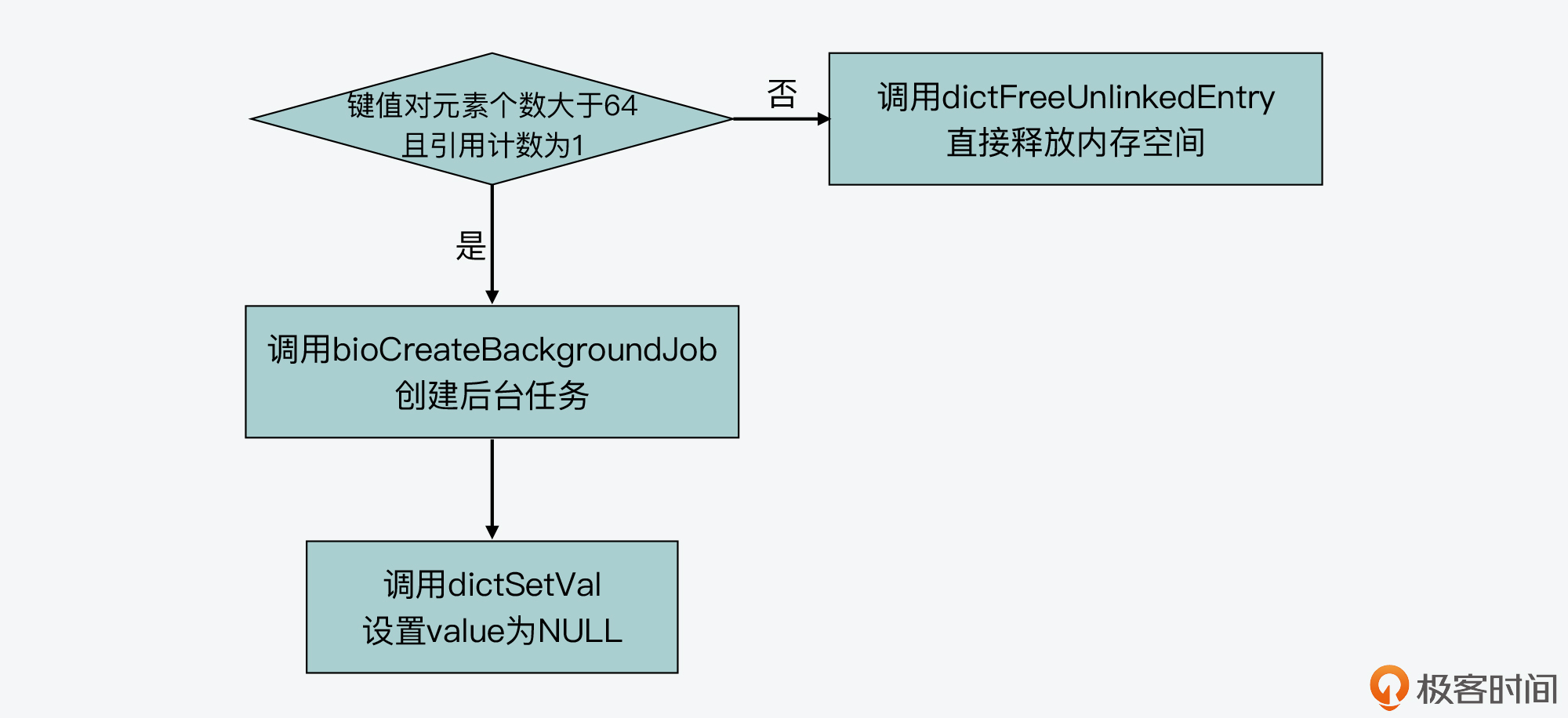
这样,当dbAsyncDelete函数通过lazyfreeGetFreeEffort函数,计算得到被淘汰键值对的删除开销之后,接下来的**第三步**,它就会把删除开销和宏定义LAZYFREE\_THRESHOLD(在lazyfree.c文件中)进行比较,这个宏定义的默认值是64。
|
|||
|
|
|
|||
|
|
所以,当被淘汰键值对是包含超过64个元素的集合类型时,dbAsyncDelete函数才会调用bioCreateBackgroundJob函数,来实际创建后台任务执行惰性删除。关于bioCreateBackgroundJob函数的作用和工作机制,我在[第12讲](https://time.geekbang.org/column/article/409927)中已经给你介绍过了,你可以再去回顾下。
|
|||
|
|
|
|||
|
|
不过,如果被淘汰键值对不是集合类型,或者是集合类型但包含的元素个数小于等于64个,那么dbAsyncDelete函数就直接调用**dictFreeUnlinkedEntry函数**(在dict.c文件中),来释放键值对所占的内存空间了。
|
|||
|
|
|
|||
|
|
以下代码就展示了dbAsyncDelete函数,使用后台任务或主IO线程释放内存空间的逻辑,你可以看下。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
//如果要淘汰的键值对包含超过64个元素
|
|||
|
|
if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) {
|
|||
|
|
atomicIncr(lazyfree_objects,1);
|
|||
|
|
bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL); //创建惰性删除的后台任务,交给后台线程执行
|
|||
|
|
dictSetVal(db->dict,de,NULL); //将被淘汰键值对的value设置为NULL
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
if (de) {
|
|||
|
|
dictFreeUnlinkedEntry(db->dict,de);
|
|||
|
|
...
|
|||
|
|
return 1;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
另外,你也可以根据下图来整体回顾下这个执行过程。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
好,那么现在,我们也就了解了基于异步删除的数据淘汰过程,实际上会根据要删除的键值对包含的元素个数,来决定是实际使用后台线程还是主线程来进行删除操作。
|
|||
|
|
|
|||
|
|
不过,如果是使用了后台线程来释放内存,那么随之带来的一个问题就是:**主线程如何知道后台线程释放的内存空间,已经满足待释放空间的大小呢?**
|
|||
|
|
|
|||
|
|
其实,freeMemoryIfNeeded函数本身在调用dbAsyncDelete或dbSyncDelete函数的前后,都会统计已经使用的内存量,并计算调用删除函数前后的差值,这样其实就可以获得已经释放的内存空间大小。
|
|||
|
|
|
|||
|
|
而除此之外,freeMemoryIfNeeded函数还会在调用dbAsyncDelete函数后,再次主动检测当前的内存使用量,是否已经满足最大内存容量要求。一旦满足了,freeMemoryIfNeeded函数就会停止淘汰数据的执行流程了。这步的执行逻辑,你可以参考以下给出的代码:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int freeMemoryIfNeeded(void) {
|
|||
|
|
...
|
|||
|
|
//执行循环流程,删除淘汰数据
|
|||
|
|
while (mem_freed < mem_tofree) {
|
|||
|
|
...
|
|||
|
|
//如果使用了惰性删除,并且每删除16个key后,统计下当前内存使用量
|
|||
|
|
if (server.lazyfree_lazy_eviction && !(keys_freed % 16)) {
|
|||
|
|
//计算当前内存使用量是否不超过最大内存容量
|
|||
|
|
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
|
|||
|
|
mem_freed = mem_tofree; //如果满足最大容量要求,让已释放内存量等于待释放量,以便结束循环
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
...
|
|||
|
|
}}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
到这里,我们就了解了基于异步删除的数据淘汰实现过程。接下来,我们再来看下基于同步删除的数据淘汰实现。
|
|||
|
|
|
|||
|
|
### 基于同步删除的数据淘汰
|
|||
|
|
|
|||
|
|
其实,和基于异步删除的数据淘汰过程相比,基于同步删除的数据淘汰过程就比较简单了。这个过程是由**dbSyncDelete函数**(在db.c文件中)实现的。
|
|||
|
|
|
|||
|
|
dbSyncDelete函数主要是实现了两步操作。首先,它会调用dictDelete函数,在过期key的哈希表中删除被淘汰的键值对。紧接着,它会再次调用dictDelete函数,在全局哈希表中删除被淘汰的键值对。这样一来,同步删除的基本操作就完成了。
|
|||
|
|
|
|||
|
|
不过,**这里你需要注意的是**,dictDelete函数通过调用dictGenericDelete函数,来同步释放键值对的内存空间时,最终是通过分别调用dictFreeKey、dictFreeVal和zfree三个函数来释放key、value和键值对对应哈希项这三者占用的内存空间的。
|
|||
|
|
|
|||
|
|
其中,zfree函数是在zmalloc.c文件中实现的。而dictFreeKey、dictFreeVal这两个函数是在dict.h文件中定义的两个宏定义。它们的具体实现是根据操作的哈希表类型,调用相应的valDestructor函数和keyDestructor函数来释放内存。你可以看看下面的代码,其中就展示了dictFreeKey和dictFreeVal的宏定义。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
#define dictFreeVal(d, entry) \
|
|||
|
|
if ((d)->type->valDestructor) \
|
|||
|
|
(d)->type->valDestructor((d)->privdata, (entry)->v.val)
|
|||
|
|
|
|||
|
|
#define dictFreeKey(d, entry) \
|
|||
|
|
if ((d)->type->keyDestructor) \
|
|||
|
|
(d)->type->keyDestructor((d)->privdata, (entry)->key)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
那么,为了方便你能找到最终进行内存释放操作的函数,下面我就**以全局哈希表为例**,来带你看下当操作全局哈希表时,键值对的dictFreeVal和dictFreeKey两个宏定义对应的函数。
|
|||
|
|
|
|||
|
|
首先,全局哈希表是在initServer函数中创建的。在创建时,全局哈希表的类型是dbDictType,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
void initServer(void) {
|
|||
|
|
...
|
|||
|
|
for (j = 0; j < server.dbnum; j++) {
|
|||
|
|
server.db[j].dict = dictCreate(&dbDictType,NULL);
|
|||
|
|
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
|
|||
|
|
...
|
|||
|
|
}
|
|||
|
|
...
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
其中,dbDictType是一个dictType类型的结构体,dictType类型是在dict.h文件中定义的。它的最后两个成员变量,就是keyDestructor函数指针和valDestructor函数指针,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
typedef struct dictType {
|
|||
|
|
...
|
|||
|
|
void (*keyDestructor)(void *privdata, void *key);
|
|||
|
|
void (*valDestructor)(void *privdata, void *obj);
|
|||
|
|
} dictType;
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
然后,对于dbDictType来说,它是在server.c文件中定义的。因为它作为全局哈希表,保存的是SDS类型的key,以及多种数据类型的value。所以,dbDictType类型哈希表的key和value释放函数,实际上分别是dictSdsDestructor函数和dictObjectDestructor函数,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
dictType dbDictType = {
|
|||
|
|
...
|
|||
|
|
dictSdsDestructor, //key的释放函数
|
|||
|
|
dictObjectDestructor //value的释放函数
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这两个函数都是在server.c文件中实现的。
|
|||
|
|
|
|||
|
|
其中,dictSdsDestructor函数主要是直接调用sdsfree函数(在sds.c文件中),释放SDS字符串占用的内存空间。而dictObjectDestructor函数会调用decrRefCount函数(在object.c文件中),来执行释放操作,如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
void dictObjectDestructor(void *privdata, void *val)
|
|||
|
|
{
|
|||
|
|
...
|
|||
|
|
decrRefCount(val);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
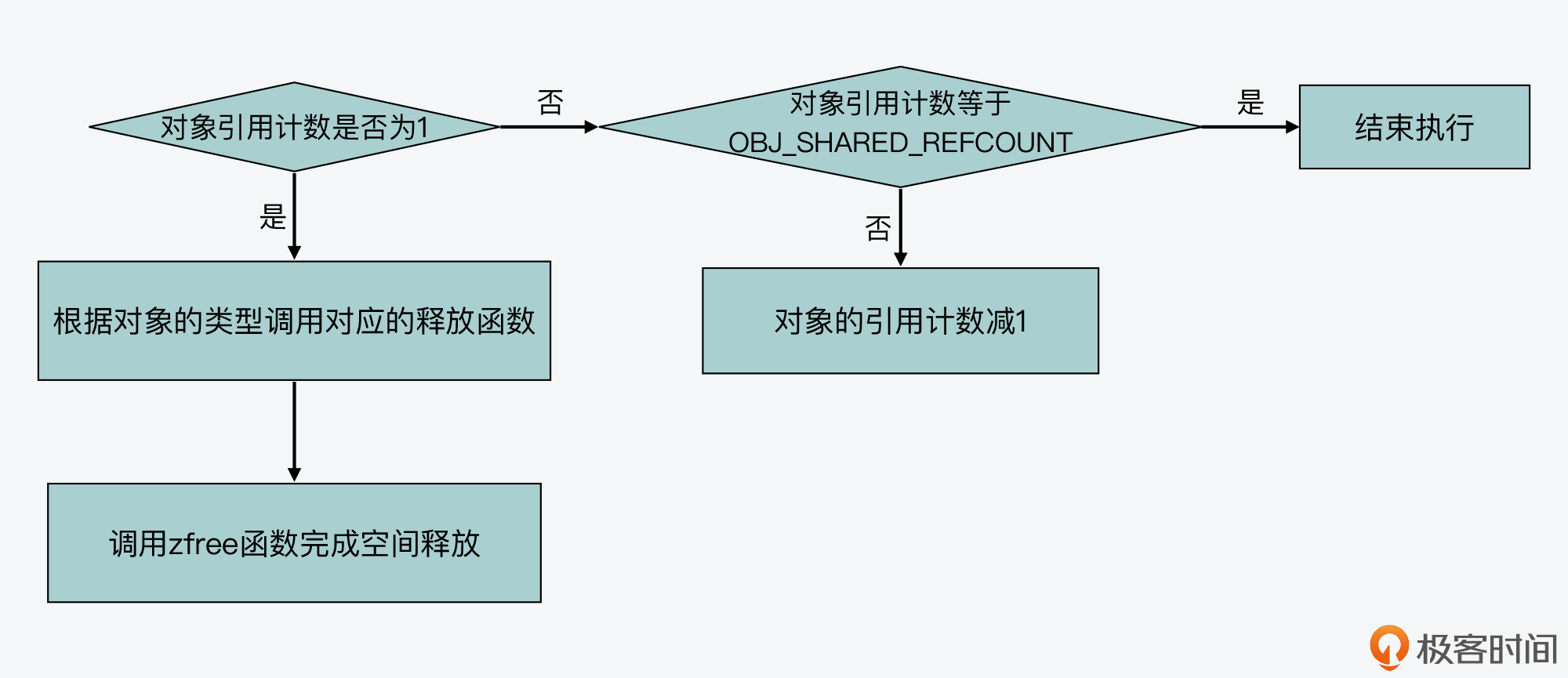
那么在这里,你要知道的是,**decrRefCount函数在执行时,会判断待释放对象的引用计数。**只有当引用计数为1了,它才会根据待释放对象的类型,调用具体类型的释放函数来释放内存空间。否则的话,decrRefCount函数就只是把待释放对象的引用计数减1。
|
|||
|
|
|
|||
|
|
现在,我们来举个例子。如果待释放对象的引用计数为1,并且是String类型的话,那么decrRefCount函数就会调用freeStringObject函数,来执行最终的内存释放操作。而如果对象是List类型,那么decrRefCount函数则会调用freeListObject函数,来最终释放内存。这部分代码如下所示:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
void decrRefCount(robj *o) {
|
|||
|
|
if (o->refcount == 1) {
|
|||
|
|
switch(o->type) {
|
|||
|
|
case OBJ_STRING: freeStringObject(o); break;
|
|||
|
|
case OBJ_LIST: freeListObject(o); break;
|
|||
|
|
...
|
|||
|
|
}
|
|||
|
|
zfree(o);
|
|||
|
|
} else {
|
|||
|
|
...
|
|||
|
|
if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我也画了一张图,来展示decrRefCount函数的基本执行逻辑,你可以看下。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
所以说,基于同步删除的数据淘汰过程,其实就是通过dictDelete函数,将被淘汰键值对从全局哈希表移除,并通过dictFreeKey、dictFreeVal和zfree三个函数来释放内存空间。而通过以上内容的学习,你就已经知道释放value空间的函数是decrRefCount函数,它会根据value的引用计数和类型,最终调用不同数据类型的释放函数来完成内存空间的释放。
|
|||
|
|
|
|||
|
|
而在这里,你也要注意的是,基于异步删除的数据淘汰,它通过后台线程执行的函数是**lazyfreeFreeObjectFromBioThread函数**(在lazyfree.c文件),而这个函数实际上也是调用了decrRefCount函数,来释放内存空间的。
|
|||
|
|
|
|||
|
|
## 小结
|
|||
|
|
|
|||
|
|
今天这节课,我给你介绍了Redis缓存在淘汰数据时,执行的数据删除流程。因为在Redis 4.0版本之后提供了惰性删除的功能,所以Redis缓存淘汰数据的时候,就会根据是否启用惰性删除,来决定是执行同步删除还是异步的惰性删除。
|
|||
|
|
|
|||
|
|
而你要知道,无论是同步删除还是异步的惰性删除,它们都会先把被淘汰的键值对从哈希表中移除。然后,同步删除就会紧接着调用dictFreeKey、dictFreeVal和zfree三个函数来分别释放key、value和键值对哈希项的内存空间。而异步的惰性删除,则是把空间释放任务交给了后台线程来完成。
|
|||
|
|
|
|||
|
|
注意,虽然惰性删除是由后台线程异步完成的,但是后台线程启动后会监听惰性删除的任务队列,一旦有了惰性删除任务,后台线程就会执行并释放内存空间。所以,从淘汰数据释放内存空间的角度来说,**惰性删除并不会影响缓存淘汰时的空间释放要求**。
|
|||
|
|
|
|||
|
|
不过在最后,我也想提醒你一下,就是后台线程需要**通过同步机制获取任务**,这个过程会引入一些额外的时间开销,会导致内存释放不像同步删除那样非常及时。实际上,这也是Redis在被淘汰数据是小集合(元素不超过64个)时,仍然使用主线程进行内存释放的设计考虑因素。
|
|||
|
|
|
|||
|
|
## 每课一问
|
|||
|
|
|
|||
|
|
请你思考一下,freeMemoryIfNeeded函数在使用后台线程,删除被淘汰数据的过程中,主线程是否仍然可以处理外部请求呢?
|
|||
|
|
|
|||
|
|
欢迎在留言区写下你的答案和思考。如果觉得有收获,也欢迎你把今天的内容分享给更多的朋友。
|
|||
|
|
|