373 lines
24 KiB
Markdown
373 lines
24 KiB
Markdown
|
|
# 06 | 聚类分析:如何用RFM给电商用户做价值分组画像?
|
|||
|
|
|
|||
|
|
你好,我是黄佳。欢迎来到零基础实战机器学习。
|
|||
|
|
|
|||
|
|
在上一讲中,我们从一份互联网电商“易速鲜花”的历史订单数据集中,求出了每一个用户的R、F、M值。你可能会问,从这些值中,我们又能看出什么有价值的信息呢?
|
|||
|
|
|
|||
|
|
别着急,在这一讲中,我们继续往前走,看看如何从这些枯燥且不容易观察的数据中,得到更为清晰的用户分组画像。通过这节课,我希望你能理解聚类算法的原理和最优化过程,这可以帮你建立起针对问题选择算法的直觉。
|
|||
|
|
|
|||
|
|
# 怎么给用户分组比较合适?
|
|||
|
|
|
|||
|
|
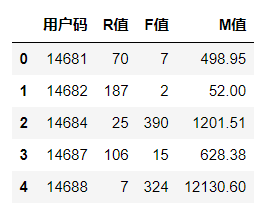
这是我们在上节课中得出的用户层级表,表中有每位用户的R、F、M值。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
这里,我们希望看看R值、F值和M值的分布情况,以便为用户分组作出指导。代码是接着上一讲的基础上继续构建,我就不全部贴上来了,完整的代码和数据集请你从[这里](https://github.com/huangjia2019/geektime/tree/main/%E8%8E%B7%E5%AE%A2%E5%85%B306)下载。
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user['R值'].plot(kind='hist', bins=20, title = '新进度分布直方图') #R值直方图
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user.query('F值 < 800')['F值'].plot(kind='hist', bins=50, title = '消费频率分布直方图') #F值直方图
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user.query('M值 < 20000')['M值'].plot(kind='hist', bins=50, title = '消费金额分布直方图') #M值直方图
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
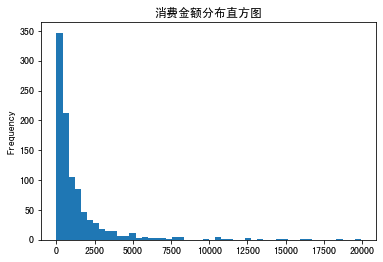
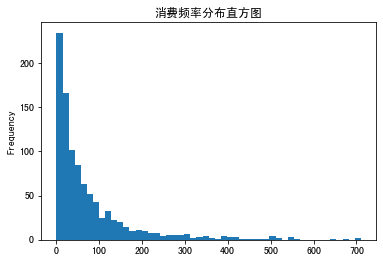
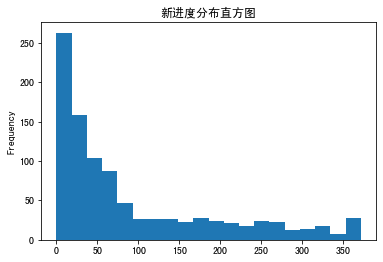
分别输出如下结果:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
可以看到,我们求出的R值、F值和M值的覆盖区间都很大。就拿R值来说,有的用户7天前购物,R值为7;有的用户70天前购物,R值为70;还有的用户187天前购物,R值为187。
|
|||
|
|
|
|||
|
|
那现在问题来了,如果说我们的目标是根据R值把用户分为几个不同的价值组,那么怎么分组比较合适呢?
|
|||
|
|
|
|||
|
|
其实,这个问题又可以拆分为两个子问题:
|
|||
|
|
|
|||
|
|
1. 分成多少个组比较好?
|
|||
|
|
2. 从哪个值到哪个值归为第一组(比如0-30天是一组),从哪个值到哪个值归为第二组(比如30天-70天是一组)?
|
|||
|
|
|
|||
|
|
对于这两个问题的答案,有人肯定会说,可以凭借经验来人为确定。比如说,把用户分为高、中、低三个组,比如R值为0到50的分为一个组,50到150的分为一组,150天以上的归为一组。
|
|||
|
|
|
|||
|
|
这样的人为分组似乎也可以,但它存在一些弊端:首先,分组的准确性完全取决于人的经验,如果分得不准,效果就不好。其次,人为分组是静态的,如果用户情况变化了,我们还是用同样的区间来分组,就不是很合适。
|
|||
|
|
|
|||
|
|
那怎么办呢?我想你已经猜到了,其实该怎么分组,我们说了不算,要数据说了算。所以,要解决这个问题,还是要通过机器学习算法,根据数据的实际情况来动态地确定分组。因为只有这样的模型才是动态的,才能长期投入使用。
|
|||
|
|
|
|||
|
|
坚定了这一点后,我们考虑一下选什么算法来建立模型。
|
|||
|
|
|
|||
|
|
# 聚类算法中的K-Means算法
|
|||
|
|
|
|||
|
|
首先,我们要搞清楚,给用户做分组画像属于监督学习问题,还是无监督学习问题?我们要通过历史订单数据来给用户分组,这是没有任何已知标签可以做参照的,数据集中并没有一个字段指明用户的价值是“高”还是“低”,所以这显然是一个无监督学习问题。
|
|||
|
|
|
|||
|
|
在无监督学习中,聚类和降维是两种最常见的算法,不过它们应用场景很不一样。聚类我们说过了,主要可以用来做分组;而降维,则是通过数学变换,将原始高维属性空间转变为一个低维“子空间”,它本质上是通过最主要的几个特征维度实现对数据的描述。很显然,我们的问题适合用聚类算法来解决。
|
|||
|
|
|
|||
|
|
聚类算法可以让机器把数据集中的样本按照特征的性质分组,不过它只是帮我们把数据特征彼此邻近的用户聚成一组(这里的组称为聚类的簇)。而这里说的“特征彼此邻近”,指的这些用户的数据特征在坐标系中有更短的向量空间距离。也就是说,**聚类算法是把空间位置相近的特征数据归为同一组。**
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
不过,请你注意,聚类算法本身并不知道哪一组用户是高价值,哪一组用户是低价值。分完组之后,我们还要根据机器聚类的结果,人为地给这些用户组贴标签,看看哪一组价值高,哪一组价值低。我这里把这种人为贴标签的过程称为“**聚类后概念化**”。等你学完这节课,就能更清楚我为什么要做“聚类后概念化”了。
|
|||
|
|
|
|||
|
|
搞清楚问题适合用聚类算法解决还不够,因为聚类的算法可不止一种,我们还要进一步确定采用哪一个算法。这里我直接选用K-Means(K-均值)算法了,因为这个算法不仅简洁,而且效率也高,是我们最常用的聚类算法。像文档归类、欺诈行为检测、用户分组等等这些场景,我们往往都能用到。
|
|||
|
|
|
|||
|
|
说到这里,你也许很疑惑:在监督学习中,模型都是要依赖于标签才能创建出来,这无监督学习怎么就这么聪明,能在没有标签的情况下自动给数据点分组?下面我就带你探寻其中的奥秘。
|
|||
|
|
|
|||
|
|
在K-Means算法中,“K”是一个关键。K代表聚类的簇(也就是组)的个数。比如说,我们想把M值作为特征,将用户分成3个簇(即高、中、低三个用户组),那这里的K值就是3,并且需要我们人工指定。
|
|||
|
|
|
|||
|
|
指定K的数值后,K-Means算法会在数据中随机挑选出K个数据点,作为簇的质心(centroid),这些质心就是未来每一个簇的中心点,算法会根据其它数据点和它的距离来进行聚类。
|
|||
|
|
|
|||
|
|
挑选出质心后,K-Means算法会遍历每一个数据点,计算它们与每一个质心的距离(比如欧式距离)。数据点离哪个质心近,就跟哪个质心属于一类。
|
|||
|
|
|
|||
|
|
遍历结束后,每一个质心周围就都聚集了很多数据点,这时候啊,算法会在数据簇中选择更靠近中心的质心,如果原来随机选择的质心不合适,就会让它下岗。
|
|||
|
|
|
|||
|
|
在整个聚类过程中,为了选择出更好的质心,“挑选质心”和“遍历数据点与质心的距离”会不断重复,直到质心的移动变化很小了,或者说固定不变了,那K-Means算法就可以停止了。
|
|||
|
|
|
|||
|
|
我用下面的图来帮助你理解质心在聚类过程中逐渐移动到最佳位置,以及簇的形成过程:
|
|||
|
|
|
|||
|
|
的移动和簇形成的过程")
|
|||
|
|
|
|||
|
|
理解了聚类算法的原理,我们继续来思考一个问题:我们前面说K值需要人工指定,那怎么在算法的辅助下确定K值呢?
|
|||
|
|
|
|||
|
|
# 手肘法选取K值
|
|||
|
|
|
|||
|
|
其实,在事先并不是很确定分成多少组比较合适的情况下,“手肘法”(elbow method)可以帮我们决定,在某一批数据点中,数据分为多少组比较合适。这里我要特别说明一下,尽管我们前面说要把用户分为高、中、低三个价值组,但是R、F、M的值却可以分成很多组,并不一定都是3组。
|
|||
|
|
|
|||
|
|
手肘法是通过聚类算法的损失值曲线来直观确定簇的数量。损失值曲线,就是以图像的方法绘出,取每一个K值时,各个数据点距离质心的平均距离。如下图所示,当K取值很小的时候,整体损失很大,也就是说各个数据点距离质心的距离特别大。而随着K的增大,损失函数的值会在逐渐收敛之前出现一个拐点。此时的K值就是一个比较好的值。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
你看图中,损失随着簇的个数而收敛的曲线大概像个手臂,最佳K值的点像是一个手肘,这就是为什么我们会叫它“手肘法”的原因。
|
|||
|
|
|
|||
|
|
下面我们就用代码找出R值的手肘点。请你注意,这里我会先定义一个找手肘点的函数,因为后面在对R值、F值和M值聚类的过程中,我们都要用到这个函数。
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
from sklearn.cluster import KMeans #导入KMeans模块
|
|||
|
|
def show_elbow(df): #定义手肘函数
|
|||
|
|
distance_list = [] #聚质心的距离(损失)
|
|||
|
|
K = range(1,9) #K值范围
|
|||
|
|
for k in K:
|
|||
|
|
kmeans = KMeans(n_clusters=k, max_iter=100) #创建KMeans模型
|
|||
|
|
kmeans = kmeans.fit(df) #拟合模型
|
|||
|
|
distance_list.append(kmeans.inertia_) #创建每个K值的损失
|
|||
|
|
plt.plot(K, distance_list, 'bx-') #绘图
|
|||
|
|
plt.xlabel('k') #X轴
|
|||
|
|
plt.ylabel('距离均方误差') #Y轴
|
|||
|
|
plt.title('k值手肘图') #标题
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在这段代码中,核心部分是拟合kmeans模型之后,通过 kmeans.inertia\_计算损失值。损失会随着K值的增大而逐渐减小,而那个拐点就是手肘。
|
|||
|
|
|
|||
|
|
然后我们调用下面这个函数,显示R值、F值和M值聚类的K值手肘图:
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
show_elbow(df_user[['R值']]) #显示R值聚类K值手肘图
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
show_elbow(df_user[['F值']]) #显示F值聚类K值手肘图
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
show_elbow(df_user[['M值']]) #显示M值聚类K值手肘图
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
输出如下:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
可以看到,R、F、M值的拐点大概都在2到4之间附近,这就意味着我们把用户分成2、3、4个组都行。这里我选择3作为R值的簇的个数,选择4作为F值的簇的个数,选择3作为M值的簇的个数。
|
|||
|
|
|
|||
|
|
那到这里为止呢,我们已经选定好了算法,并确定了R、F、M每个特征下簇的个数,也就是K值。接下来我们就可以开始创建聚类模型了。
|
|||
|
|
|
|||
|
|
# 创建和训练模型
|
|||
|
|
|
|||
|
|
前面说了,我们在手肘附近选择3作为R的K值,所以我们创建模型是把n\_clusters参数,也就是簇的个数指定为3。这样,聚类算法会把用户的R值分为三个层次。对于F、M,我们也根据对应的K值做类似的操作:
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
from sklearn.cluster import KMeans #导入KMeans模块
|
|||
|
|
kmeans_R = KMeans(n_clusters=3) #设定K=3
|
|||
|
|
kmeans_F = KMeans(n_clusters=4) #设定K=4
|
|||
|
|
kmeans_M = KMeans(n_clusters=4) #设定K=4
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这样,我们就在程序中创建了一个K-Means聚类模型。
|
|||
|
|
创建好模型后,我们借助fit方法,用R值的数据,训练模型。
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
kmeans_R.fit(df_user[['R值']]) #拟合模型
|
|||
|
|
kmeans_F.fit(df_user[['F值']]) #拟合模型
|
|||
|
|
kmeans_M.fit(df_user[['M值']]) #拟合模型
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们不是第一次见到fit这个方法了,fit,翻译成中文就叫做拟合模型。基本上所有的机器学习模型都是用fit语句来进行模型训练的。
|
|||
|
|
|
|||
|
|
# 使用模型进行聚类,并给用户分组
|
|||
|
|
|
|||
|
|
模型训练好了,现在我们就用它给R、F、M值聚类。
|
|||
|
|
|
|||
|
|
1. **给R、F、M值聚类**
|
|||
|
|
|
|||
|
|
我们先用kmeans模型中的predict方法给R值聚类。“predict”翻译成中文是“预测”,不过作为无监督学习方法,它其实就是使用模型进行聚类,而且,也不需要进一步的评估过程。这也是监督学习和无监督学习不一样的地方。
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
df_user['R值层级'] = kmeans_R.predict(df_user[['R值']]) #通过聚类模型求出R值的层级
|
|||
|
|
df_user.head() #显示头几行数据
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
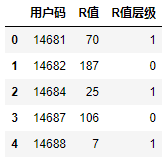
这段代码的输出如下:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
输出显示,这个聚类结果被附加到了用户层级表中,也就是说在用户层级表中的“用户码”、“R值”字段后面出现了“R值层级”这个字段,也就是将R值聚类后各个簇的号码。
|
|||
|
|
|
|||
|
|
下面我们用groupby语句来看看0、1、2这几个簇的用户基本统计数据:
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
df_user.groupby('R值层级')['R值'].describe() #R值层级分组统计信息
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
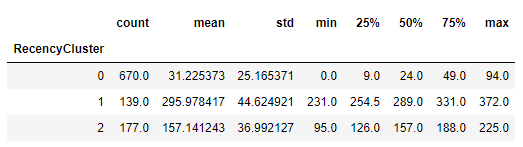
这段代码的输出如下:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
这里有一个奇怪的现象,不知道你有没有观察到?
|
|||
|
|
|
|||
|
|
如果你注意看0、1和2这三个簇,也就是三个组,就会发现形成的簇没有顺序。你看,0群的用户最多670个人,均值显示他们平均购物间隔是31天,上次购物距今是0天到94天,这是相对频繁的购物用户群。
|
|||
|
|
|
|||
|
|
1群的用户平均购物间隔为295天,上次购物距现在是231天到372天,这是在休眠中的用户;而2群的用户平均购货间隔则变成了157天,介于两者之间,他们上次购物距今是从95天到225天。你会发现这个从0到2的顺序既不是升序,也不是降序。
|
|||
|
|
|
|||
|
|
这其实是聚类这种算法本身的问题。聚类,作为一种无监督学习算法,是不知道顺序的重要性的,它只是盲目地把用户分群(按照其空间距离的临近性),而不管每个群的具体意义,因此也就没有排序的功能。这也就是我前面说的“聚类后概念化”的具体意思。聚类并不知道那组人的价值高低,所以也就无法确定顺序,需要我们人为来排序。
|
|||
|
|
|
|||
|
|
2. **为聚类的层级做排序**
|
|||
|
|
|
|||
|
|
那么,下面我们就用一段代码,把聚类的结果做一个排序,让0、1、2这三个组体现出价值的高低。这段代码稍微有点长,不过我给出了详细的注释,你可以看一下:
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
#定义一个order_cluster函数为聚类排序
|
|||
|
|
def order_cluster(cluster_name, target_name,df,ascending=False):
|
|||
|
|
new_cluster_name = 'new_' + cluster_name #新的聚类名称
|
|||
|
|
df_new = df.groupby(cluster_name)[target_name].mean().reset_index() #按聚类结果分组,创建df_new对象
|
|||
|
|
df_new = df_new.sort_values(by=target_name,ascending=ascending).reset_index(drop=True) #排序
|
|||
|
|
df_new['index'] = df_new.index #创建索引字段
|
|||
|
|
df_new = pd.merge(df,df_new[[cluster_name,'index']], on=cluster_name) #基于聚类名称把df_new还原为df对象,并添加索引字段
|
|||
|
|
df_new = df_new.drop([cluster_name],axis=1) #删除聚类名称
|
|||
|
|
df_new = df_new.rename(columns={"index":cluster_name}) #将索引字段重命名为聚类名称字段
|
|||
|
|
return df_new #返回排序后的df_new对象
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在上述代码中,为聚类做排序的是order\_cluster函数。那么接下来,我们再调用这个order\_cluster函数,把用户表重新排序。我们知道,消费天数间隔的均值越小,用户的价值就越高,所以我们在这里采用降序,也就是把ascending参数设为False:
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user = order_cluster('R值层级', 'R值', df_user, False) #调用簇排序函数
|
|||
|
|
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
|
|||
|
|
df_user.head() #显示头几行数据
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
此时,各用户的层级值就发生了变化,比如用户14688的簇编号从1变成了2,因为这个用户7天前曾经购物,其R值相对偏低,放在高分的2层级是合适的。其实,上面的代码中,我们并没有改变用户的分组,而只是改变了每一个簇的编号,这样层级关系就能体现出来了。
|
|||
|
|
|
|||
|
|
下面我们重新显示各个层级的信息:
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user.groupby('R值层级')['R值'].describe() #R值层级分组统计信息
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
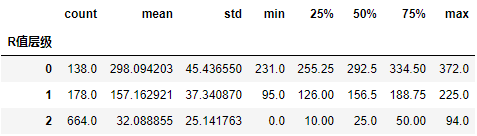
输出如下:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
你会看到,此时各个簇已经形成了次序。0层级的用户,平均新近度是298天,1层级的用户,平均新近度是157天,而R值最高的用户组(2层级),平均新近度仅有32天。这说明用户上一次消费距今的天数越少,其R值的价值越高。
|
|||
|
|
|
|||
|
|
R值聚类做好后,我们按照同样的方法可以根据用户购买频率给F值做聚类,并用刚才定义的order\_cluster函数为聚类之后的簇进行排序,确定层级。因为消费次数越多,价值越高,所以我们把order\_cluster 函数的ascending参数设定为True,也就是升序:
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user['F值层级'] = kmeans_F.predict(df_user[['F值']]) #通过聚类模型求出F值的层级
|
|||
|
|
df_user = order_cluster('F值层级', 'F值',df_user,True) #调用簇排序函数
|
|||
|
|
df_user.groupby('F值层级')['F值'].describe() #F值层级分组统计信息
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
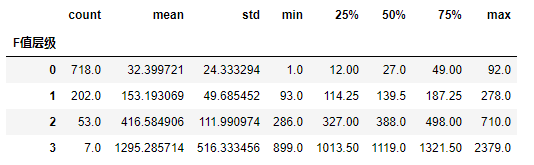
输出如下:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
上图显示,经过了排序的层级中,0级用户的购买频率均值为32次,1级的用户消费频率均值为153次,2级用户消费频率均值达到416次,而2级用户的消费频率均值高达1295次,不过这个簇中只有7个用户。
|
|||
|
|
|
|||
|
|
还是一样,我们重新为用户层级表排序,并显示df\_user对象,也就是用户层级表的当前状态。
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
|
|||
|
|
df_user.head()
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
输出如下:
|
|||
|
|
|
|||
|
|
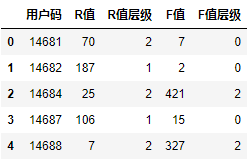
|
|||
|
|
|
|||
|
|
最后,我们依葫芦画瓢,给M值做聚类,并且对聚类的结果做排序,分出层级。因为代码和R值、F值聚类十分相似,我就直接给出所有代码,不再说明了。
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user['M值层级'] = kmeans_M.predict(df_user[['M值']]) #通过聚类模型求出M值的层级
|
|||
|
|
df_user = order_cluster('M值层级', 'M值',df_user,True) #调用簇排序函数
|
|||
|
|
df_user.groupby('M值层级')['M值'].describe() #M值层级分组统计信息
|
|||
|
|
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
|
|||
|
|
df_user.head() #显示头几行数据
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
最终结果:
|
|||
|
|
|
|||
|
|
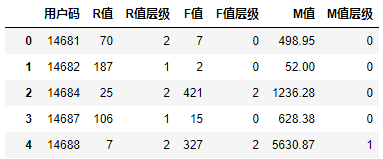
|
|||
|
|
|
|||
|
|
好,那到这里为止,R、F、M的聚类工作就全部完成了,并且我们还划分了层级!在当前的用户层级表中,已经包含了这三个维度的层级,最终的用户分层就可以以此为基础来确定了。
|
|||
|
|
|
|||
|
|
# 为用户整体分组画像
|
|||
|
|
|
|||
|
|
我们这里采用简单叠加的方法把R、F、M三个层级的值相加,用相加后得到的值,作为总体价值,来给用户进行最终的分层。当然了,如果你对其中某一个指标看得比较重,也可以加权之后再相加。
|
|||
|
|
|
|||
|
|
具体来讲,我们用下面的代码来创建相加之后的层级,即总分字段。
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
df_user['总分'] = df_user['R值层级'] + df_user['F值层级'] + df_user['M值层级'] #求出每个用户RFM总分
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
因为R值有3个层级(0,1,2),F值有4个层级(0,1,2,3),M值有4个层级(0,1,2,3),我们把三个维度的值相加,那每一个用户的得分有可能是0到8当中的某一个值,也就是说出现了9个层次。
|
|||
|
|
|
|||
|
|
我这里就按照下面的规则,来确定用户最终的价值分层。当然了,你也可以尝试用其它的阈值来确定你的价值分层。
|
|||
|
|
|
|||
|
|
* 0-2分,低价值用户
|
|||
|
|
* 3-4分,中价值用户
|
|||
|
|
* 5-8分,高价值用户
|
|||
|
|
|
|||
|
|
什么意思呢?举例来说,就是如果一个用户在R值拿到了2分,在新近度这个维度为高价值用户,但是在消费频率和消费金额这两个维度都只拿到0分,那么最后得分就为2,总体只能评为低价值用户。
|
|||
|
|
|
|||
|
|
下面这段代码便是根据总分,来确定出每一个用户的总体价值的。
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
#在df_user对象中添加总体价值这个字段
|
|||
|
|
df_user.loc[(df_user['总分']<=2) & (df_user['总分']>=0), '总体价值'] = '低价值'
|
|||
|
|
df_user.loc[(df_user['总分']<=4) & (df_user['总分']>=3), '总体价值'] = '中价值'
|
|||
|
|
df_user.loc[(df_user['总分']<=8) & (df_user['总分']>=5), '总体价值'] = '高价值'
|
|||
|
|
df_user #显示df_user
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们再次输出df\_user对象,看一看最终的用户层级表:
|
|||
|
|
|
|||
|
|
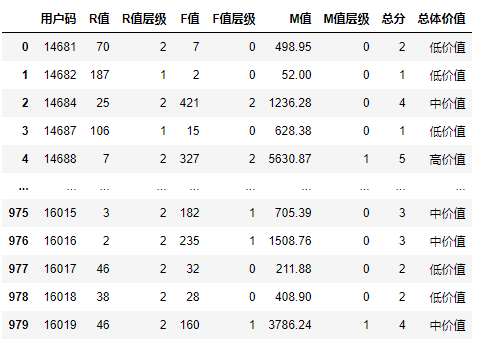
|
|||
|
|
|
|||
|
|
此时,980个用户的R、F、M层级,还有总体价值的层级都非常清楚了。对于每一个用户,我们都可以迅速定位到他的价值。那到这里,我们就成功地完成了为“易速鲜花”公司做用户价值分组的工作。
|
|||
|
|
|
|||
|
|
现在,有了用户的价值分组标签,我们就可以做很多进一步的分析,比如说选取R、F、M中任意两个维度,并把高、中、低价值用户的散点图进行呈现:
|
|||
|
|
|
|||
|
|
```typescript
|
|||
|
|
#显示高、中、低价值组分布散点图(F值与M值)
|
|||
|
|
plt.scatter(df_user.query("总体价值 == '高价值'")['F值'],
|
|||
|
|
df_user.query("总体价值 == '高价值'")['M值'],c='g',marker='*')
|
|||
|
|
plt.scatter(df_user.query("总体价值 == '中价值'")['F值'],
|
|||
|
|
df_user.query("总体价值 == '中价值'")['M值'],marker=8)
|
|||
|
|
plt.scatter(df_user.query("总体价值 == '低价值'")['F值'],
|
|||
|
|
df_user.query("总体价值 == '低价值'")['M值'],c='r')
|
|||
|
|
各价值组的用户分布散点图如下图所示:
|
|||
|
|
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
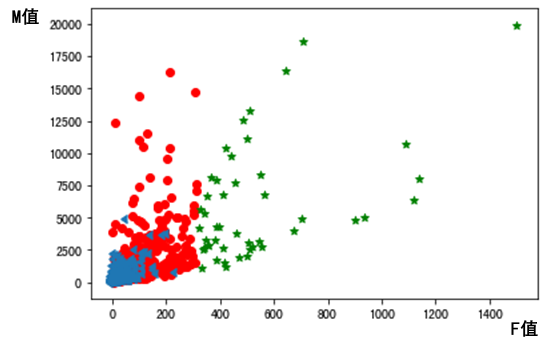
|
|||
|
|
|
|||
|
|
借此,我们可以发现,高价值用户(绿色五星)覆盖在消费频率较高的区域,和F值相关度高。而在总消费金额大于5000元的用户中,中高价值的用户(绿色五星和红色圆点)都有。
|
|||
|
|
|
|||
|
|
当然,作为运营部门的一员,你还可以通过对新老用户的价值分组,制定出更有针对性的获客、营销、推广等运营方案。
|
|||
|
|
|
|||
|
|
# 总结一下
|
|||
|
|
|
|||
|
|
好啦,到这里,我们就成功闯过了“获客”这个关卡。现在来回顾一下这一讲中的重点内容。
|
|||
|
|
|
|||
|
|
在这一讲中, 我们理解了聚类算法的原理,学会了如何用手肘法选择K值,以及如何用K-均值算法来给R值、F值和M值做聚类。
|
|||
|
|
|
|||
|
|
我要再次强调的是,聚类只是负责把空间距离相近的数据点分成不同的簇,它并不知道每一个簇代表的具体含义。比如说,我们用K-Means算法给R值分成三个簇,这并不表示0比1价值低,1比2价值低。此时的0、1、2都是聚类随机分配的编号,具体分组排序的工作我们还要单独去完成。
|
|||
|
|
|
|||
|
|
在K值的选择方面呢,手肘法可以帮我们直观地显示出聚类过程中整体损失的“拐点”,我们可以在拐点或者拐点附近选择K值,确定把数据分成多少个“簇”(也就是多少个组)。
|
|||
|
|
|
|||
|
|
最后,我们还讲到用K-均值算法来给R值做聚类,这也非常简单,就是创建模型、拟合模型、用模型进行聚类,这些过程加一块也就是几行代码的事儿,你不用有负担。
|
|||
|
|
|
|||
|
|
掌握了上述这些内容,你就可以用K-Means算法这种无监督学习算法给任何数据集做聚类,来解决其它类似的问题了,比如根据学生的考试成绩,为学生分组聚类等等。
|
|||
|
|
|
|||
|
|
# 思考题
|
|||
|
|
|
|||
|
|
这节课就到这里了,我给你留两个思考题:
|
|||
|
|
|
|||
|
|
1. 对于K-Means算法,X特征数据集的输入,可以不止一个维度。为了给R、F、M分别分层,在这节课中我给这三者单独做了聚类。你能不能试着把R、F、M三个特征同时输入K-Means算法,为用户整体做聚类呢?此外,你还能不能想到些其它的为用户分组画像的方法呢?
|
|||
|
|
2. 聚类算法的应用场景其实很广,包括给图像的颜色簇量化分组、给文本分组等等,在你的工作和生活中,你还能够想到,或者曾用过哪些可以通过聚类解决的问题?请你分享一下。
|
|||
|
|
|
|||
|
|
欢迎你在留言区和我分享你的观点,如果你认为这节课的内容有收获,也欢迎把它分享给你的朋友,我们下一讲再见!
|
|||
|
|
|
|||
|
|

|
|||
|
|
|