|
|
|
|
|
# 28 | 硬盘文件系统:如何最合理地组织档案库的文档?
|
|
|
|
|
|
|
|
|
|
|
|
上一节,我们按照图书馆的模式,规划了档案库,也即文件系统应该有的样子。这一节,我们将这个模式搬到硬盘上来看一看。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
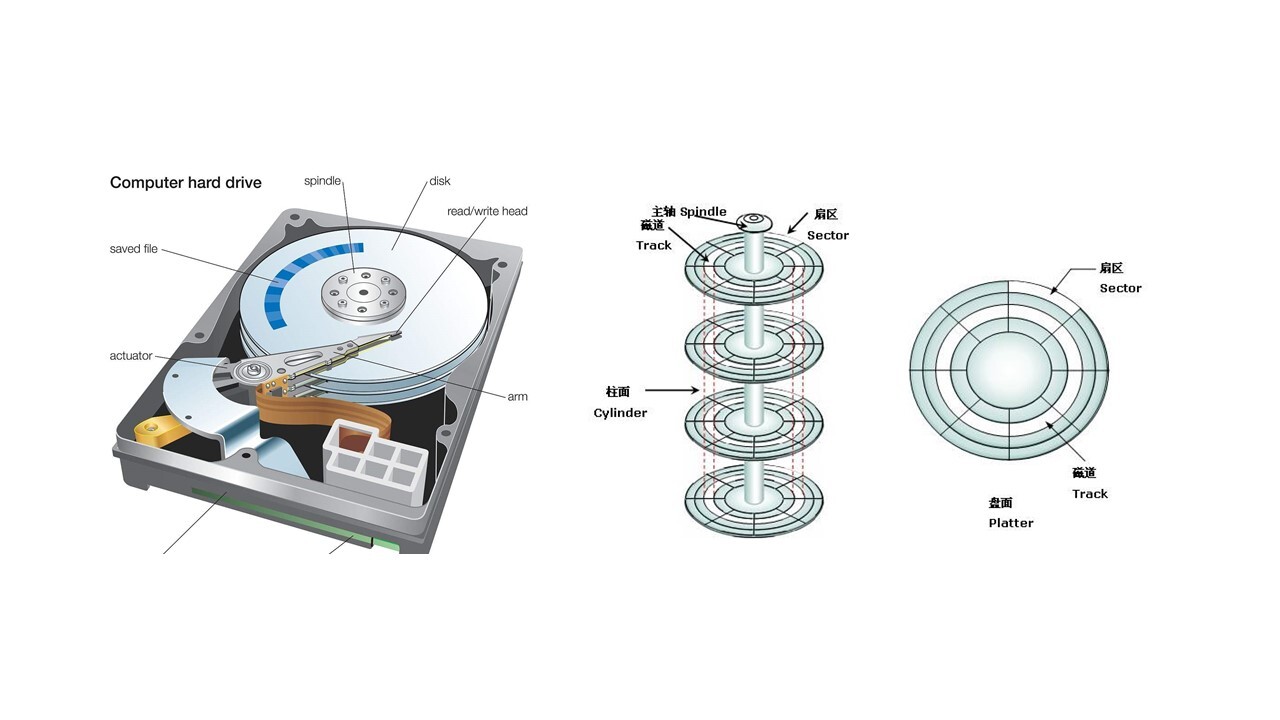
我们常见的硬盘是上面这幅图左边的样子,中间圆的部分是磁盘的盘片,右边的图是抽象出来的图。每一层里分多个磁道,每个磁道分多个扇区,每个扇区是512个字节。
|
|
|
|
|
|
|
|
|
|
|
|
文件系统就是安装在这样的硬盘之上。这一节我们重点目前Linux下最主流的文件系统格式——**ext系列**的文件系统的格式。
|
|
|
|
|
|
|
|
|
|
|
|
## inode与块的存储
|
|
|
|
|
|
|
|
|
|
|
|
就像图书馆的书架都要分成大小相同的格子,硬盘也是一样的。硬盘分成相同大小的单元,我们称为**块**(Block)。一块的大小是扇区大小的整数倍,默认是4K。在格式化的时候,这个值是可以设定的。
|
|
|
|
|
|
|
|
|
|
|
|
一大块硬盘被分成了一个个小的块,用来存放文件的数据部分。这样一来,如果我们像存放一个文件,就不用给他分配一块连续的空间了。我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。
|
|
|
|
|
|
|
|
|
|
|
|
但是这也带来一个新的问题,那就是文件的数据存放得太散,找起来就比较困难。有什么办法解决呢?我们是不是可以像图书馆那样,也设立一个索引区域,用来维护“某个文件分成几块、每一块在哪里”等等这些**基本信息**?
|
|
|
|
|
|
|
|
|
|
|
|
另外,文件还有**元数据**部分,例如名字、权限等,这就需要一个结构**inode**来存放。
|
|
|
|
|
|
|
|
|
|
|
|
什么是inode呢?inode的“i”是index的意思,其实就是“索引”,类似图书馆的索引区域。既然如此,我们每个文件都会对应一个inode;一个文件夹就是一个文件,也对应一个inode。
|
|
|
|
|
|
|
|
|
|
|
|
至于inode里面有哪些信息,其实我们在内核中就有定义。你可以看下面这个数据结构。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct ext4_inode {
|
|
|
|
|
|
__le16 i_mode; /* File mode */
|
|
|
|
|
|
__le16 i_uid; /* Low 16 bits of Owner Uid */
|
|
|
|
|
|
__le32 i_size_lo; /* Size in bytes */
|
|
|
|
|
|
__le32 i_atime; /* Access time */
|
|
|
|
|
|
__le32 i_ctime; /* Inode Change time */
|
|
|
|
|
|
__le32 i_mtime; /* Modification time */
|
|
|
|
|
|
__le32 i_dtime; /* Deletion Time */
|
|
|
|
|
|
__le16 i_gid; /* Low 16 bits of Group Id */
|
|
|
|
|
|
__le16 i_links_count; /* Links count */
|
|
|
|
|
|
__le32 i_blocks_lo; /* Blocks count */
|
|
|
|
|
|
__le32 i_flags; /* File flags */
|
|
|
|
|
|
......
|
|
|
|
|
|
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
|
|
|
|
|
|
__le32 i_generation; /* File version (for NFS) */
|
|
|
|
|
|
__le32 i_file_acl_lo; /* File ACL */
|
|
|
|
|
|
__le32 i_size_high;
|
|
|
|
|
|
......
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
从这个数据结构中,我们可以看出,inode里面有文件的读写权限i\_mode,属于哪个用户i\_uid,哪个组i\_gid,大小是多少i\_size\_io,占用多少个块i\_blocks\_io。咱们讲ls命令行的时候,列出来的权限、用户、大小这些信息,就是从这里面取出来的。
|
|
|
|
|
|
|
|
|
|
|
|
另外,这里面还有几个与文件相关的时间。i\_atime是access time,是最近一次访问文件的时间;i\_ctime是change time,是最近一次更改inode的时间;i\_mtime是modify time,是最近一次更改文件的时间。
|
|
|
|
|
|
|
|
|
|
|
|
这里你需要注意区分几个地方。首先,访问了,不代表修改了,也可能只是打开看看,就会改变access time。其次,修改inode,有可能修改的是用户和权限,没有修改数据部分,就会改变change time。只有数据也修改了,才改变modify time。
|
|
|
|
|
|
|
|
|
|
|
|
我们刚才说的“某个文件分成几块、每一块在哪里”,这些在inode里面,应该保存在i\_block里面。
|
|
|
|
|
|
|
|
|
|
|
|
具体如何保存的呢?EXT4\_N\_BLOCKS有如下的定义,计算下来一共有15项。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
#define EXT4_NDIR_BLOCKS 12
|
|
|
|
|
|
#define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
|
|
|
|
|
|
#define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
|
|
|
|
|
|
#define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
|
|
|
|
|
|
#define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
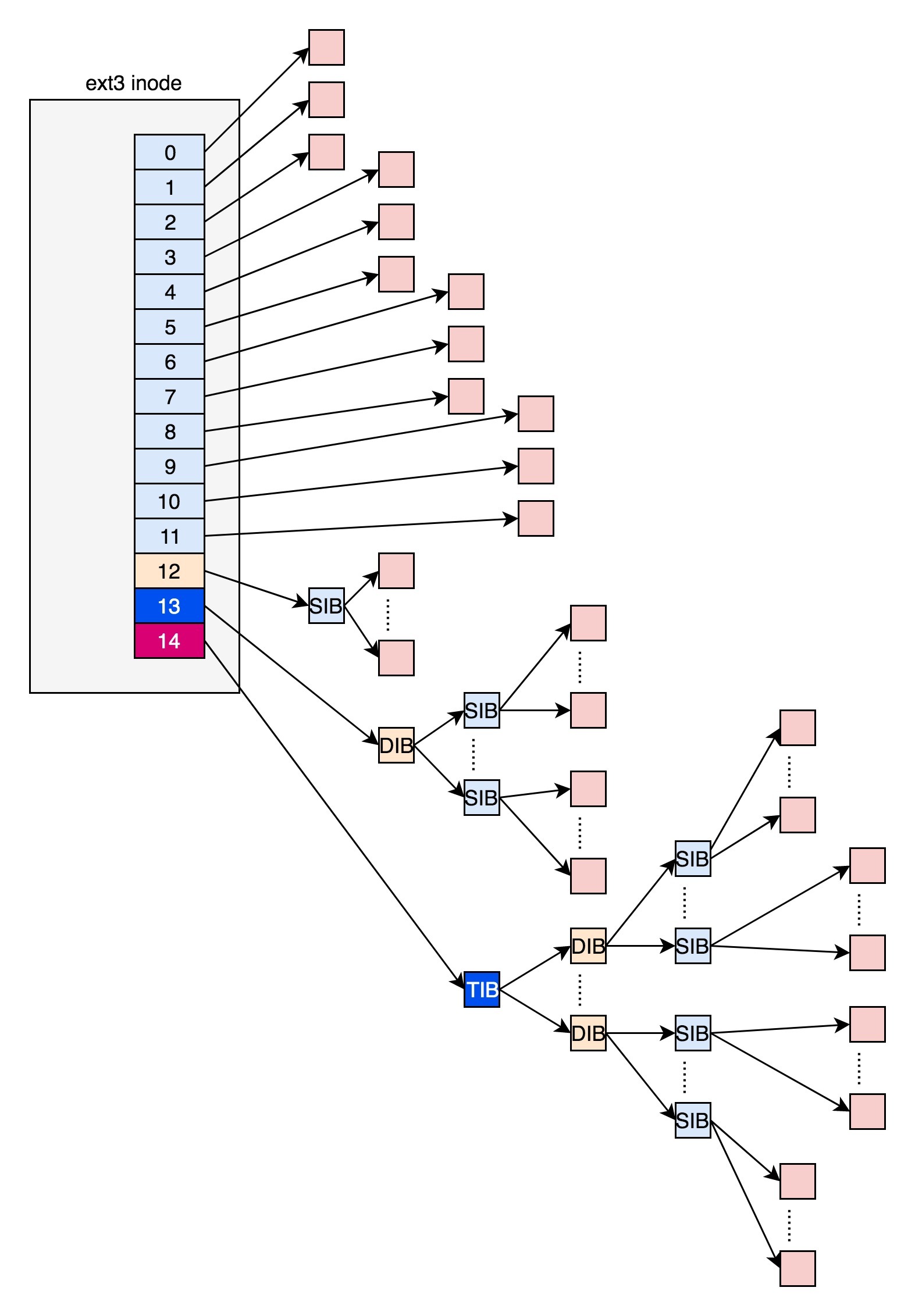
在ext2和ext3中,其中前12项直接保存了块的位置,也就是说,我们可以通过i\_block\[0-11\],直接得到保存文件内容的块。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
但是,如果一个文件比较大,12块放不下。当我们用到i\_block\[12\]的时候,就不能直接放数据块的位置了,要不然i\_block很快就会用完了。这该怎么办呢?我们需要想个办法。我们可以让i\_block\[12\]指向一个块,这个块里面不放数据块,而是放数据块的位置,这个块我们称为**间接块**。也就是说,我们在i\_block\[12\]里面放间接块的位置,通过i\_block\[12\]找到间接块后,间接块里面放数据块的位置,通过间接块可以找到数据块。
|
|
|
|
|
|
|
|
|
|
|
|
如果文件再大一些,i\_block\[13\]会指向一个块,我们可以用二次间接块。二次间接块里面存放了间接块的位置,间接块里面存放了数据块的位置,数据块里面存放的是真正的数据。如果文件再大一些,i\_block\[14\]会指向三次间接块。原理和上面都是一样的,就像一层套一层的俄罗斯套娃,一层一层打开,才能拿到最中心的数据块。
|
|
|
|
|
|
|
|
|
|
|
|
如果你稍微有点经验,现在你应该能够意识到,这里面有一个非常显著的问题,对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
|
|
|
|
|
|
|
|
|
|
|
|
为了解决这个问题,ext4做了一定的改变。它引入了一个新的概念,叫做**Extents**。
|
|
|
|
|
|
|
|
|
|
|
|
我们来解释一下Extents。比方说,一个文件大小为128M,如果使用4k大小的块进行存储,需要32k个块。如果按照ext2或者ext3那样散着放,数量太大了。但是Extents可以用于存放连续的块,也就是说,我们可以把128M放在一个Extents里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。
|
|
|
|
|
|
|
|
|
|
|
|
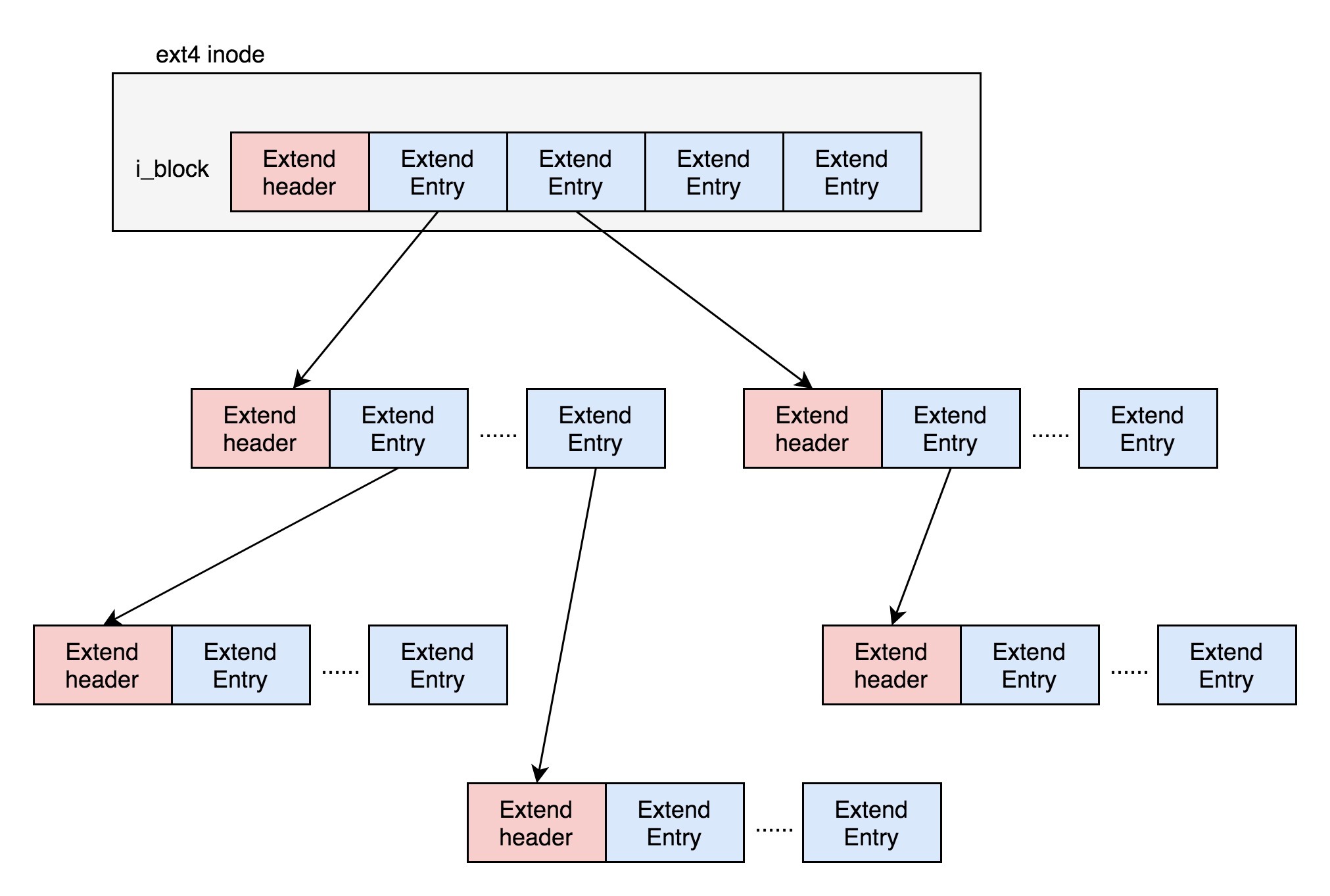
Exents如何来存储呢?它其实会保存成一棵树。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
树有一个个的节点,有叶子节点,也有分支节点。每个节点都有一个头,ext4\_extent\_header可以用来描述某个节点。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct ext4_extent_header {
|
|
|
|
|
|
__le16 eh_magic; /* probably will support different formats */
|
|
|
|
|
|
__le16 eh_entries; /* number of valid entries */
|
|
|
|
|
|
__le16 eh_max; /* capacity of store in entries */
|
|
|
|
|
|
__le16 eh_depth; /* has tree real underlying blocks? */
|
|
|
|
|
|
__le32 eh_generation; /* generation of the tree */
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
我们仔细来看里面的内容。eh\_entries表示这个节点里面有多少项。这里的项分两种,如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点ext4\_extent;如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点ext4\_extent\_idx。这两种类型的项的大小都是12个byte。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
/*
|
|
|
|
|
|
* This is the extent on-disk structure.
|
|
|
|
|
|
* It's used at the bottom of the tree.
|
|
|
|
|
|
*/
|
|
|
|
|
|
struct ext4_extent {
|
|
|
|
|
|
__le32 ee_block; /* first logical block extent covers */
|
|
|
|
|
|
__le16 ee_len; /* number of blocks covered by extent */
|
|
|
|
|
|
__le16 ee_start_hi; /* high 16 bits of physical block */
|
|
|
|
|
|
__le32 ee_start_lo; /* low 32 bits of physical block */
|
|
|
|
|
|
};
|
|
|
|
|
|
/*
|
|
|
|
|
|
* This is index on-disk structure.
|
|
|
|
|
|
* It's used at all the levels except the bottom.
|
|
|
|
|
|
*/
|
|
|
|
|
|
struct ext4_extent_idx {
|
|
|
|
|
|
__le32 ei_block; /* index covers logical blocks from 'block' */
|
|
|
|
|
|
__le32 ei_leaf_lo; /* pointer to the physical block of the next *
|
|
|
|
|
|
* level. leaf or next index could be there */
|
|
|
|
|
|
__le16 ei_leaf_hi; /* high 16 bits of physical block */
|
|
|
|
|
|
__u16 ei_unused;
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
如果文件不大,inode里面的i\_block中,可以放得下一个ext4\_extent\_header和4项ext4\_extent。所以这个时候,eh\_depth为0,也即inode里面的就是叶子节点,树高度为0。
|
|
|
|
|
|
|
|
|
|
|
|
如果文件比较大,4个extent放不下,就要分裂成为一棵树,eh\_depth>0的节点就是索引节点,其中根节点深度最大,在inode中。最底层eh\_depth=0的是叶子节点。
|
|
|
|
|
|
|
|
|
|
|
|
除了根节点,其他的节点都保存在一个块4k里面,4k扣除ext4\_extent\_header的12个byte,剩下的能够放340项,每个extent最大能表示128MB的数据,340个extent会使你表示的文件达到42.5GB。这已经非常大了,如果再大,我们可以增加树的深度。
|
|
|
|
|
|
|
|
|
|
|
|
## inode位图和块位图
|
|
|
|
|
|
|
|
|
|
|
|
到这里,我们知道了,硬盘上肯定有一系列的inode和一系列的块排列起来。
|
|
|
|
|
|
|
|
|
|
|
|
接下来的问题是,如果我要保存一个数据块,或者要保存一个inode,我应该放在硬盘上的哪个位置呢?难道需要将所有的inode列表和块列表扫描一遍,找个空的地方随便放吗?
|
|
|
|
|
|
|
|
|
|
|
|
当然,这样效率太低了。所以在文件系统里面,我们专门弄了一个块来保存inode的位图。在这4k里面,每一位对应一个inode。如果是1,表示这个inode已经被用了;如果是0,则表示没被用。同样,我们也弄了一个块保存block的位图。
|
|
|
|
|
|
|
|
|
|
|
|
上海虹桥火车站的厕位智能引导系统,不知道你有没有见过?这个系统很厉害,我们要想知道哪个位置有没有被占用,不用挨个拉门,从这样一个电子版上就能看到了。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们来看位图究竟是如何在Linux操作系统里面起作用的。前一节我们讲过,如果创建一个新文件,会调用open函数,并且参数会有O\_CREAT。这表示当文件找不到的时候,我们就需要创建一个。open是一个系统调用,在内核里面会调用sys\_open,定义如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
|
|
|
|
|
|
{
|
|
|
|
|
|
if (force_o_largefile())
|
|
|
|
|
|
flags |= O_LARGEFILE;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
return do_sys_open(AT_FDCWD, filename, flags, mode);
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里我们还是重点看对于inode的操作。其实open一个文件很复杂,下一节我们会详细分析整个过程。
|
|
|
|
|
|
|
|
|
|
|
|
我们来看接下来的调用链:do\_sys\_open-> do\_filp\_open->path\_openat->do\_last->lookup\_open。这个调用链的逻辑是,要打开一个文件,先要根据路径找到文件夹。如果发现文件夹下面没有这个文件,同时又设置了O\_CREAT,就说明我们要在这个文件夹下面创建一个文件,那我们就需要一个新的inode。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
static int lookup_open(struct nameidata *nd, struct path *path,
|
|
|
|
|
|
struct file *file,
|
|
|
|
|
|
const struct open_flags *op,
|
|
|
|
|
|
bool got_write, int *opened)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
if (!dentry->d_inode && (open_flag & O_CREAT)) {
|
|
|
|
|
|
......
|
|
|
|
|
|
error = dir_inode->i_op->create(dir_inode, dentry, mode,
|
|
|
|
|
|
open_flag & O_EXCL);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
想要创建新的inode,我们就要调用dir\_inode,也就是文件夹的inode的create函数。它的具体定义是这样的:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
const struct inode_operations ext4_dir_inode_operations = {
|
|
|
|
|
|
.create = ext4_create,
|
|
|
|
|
|
.lookup = ext4_lookup,
|
|
|
|
|
|
.link = ext4_link,
|
|
|
|
|
|
.unlink = ext4_unlink,
|
|
|
|
|
|
.symlink = ext4_symlink,
|
|
|
|
|
|
.mkdir = ext4_mkdir,
|
|
|
|
|
|
.rmdir = ext4_rmdir,
|
|
|
|
|
|
.mknod = ext4_mknod,
|
|
|
|
|
|
.tmpfile = ext4_tmpfile,
|
|
|
|
|
|
.rename = ext4_rename2,
|
|
|
|
|
|
.setattr = ext4_setattr,
|
|
|
|
|
|
.getattr = ext4_getattr,
|
|
|
|
|
|
.listxattr = ext4_listxattr,
|
|
|
|
|
|
.get_acl = ext4_get_acl,
|
|
|
|
|
|
.set_acl = ext4_set_acl,
|
|
|
|
|
|
.fiemap = ext4_fiemap,
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里面定义了,如果文件夹inode要做一些操作,每个操作对应应该调用哪些函数。这里create操作调用的是ext4\_create。
|
|
|
|
|
|
|
|
|
|
|
|
接下来的调用链是这样的:ext4\_create->ext4\_new\_inode\_start\_handle->\_\_ext4\_new\_inode。在\_\_ext4\_new\_inode函数中,我们会创建新的inode。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct inode *__ext4_new_inode(handle_t *handle, struct inode *dir,
|
|
|
|
|
|
umode_t mode, const struct qstr *qstr,
|
|
|
|
|
|
__u32 goal, uid_t *owner, __u32 i_flags,
|
|
|
|
|
|
int handle_type, unsigned int line_no,
|
|
|
|
|
|
int nblocks)
|
|
|
|
|
|
{
|
|
|
|
|
|
......
|
|
|
|
|
|
inode_bitmap_bh = ext4_read_inode_bitmap(sb, group);
|
|
|
|
|
|
......
|
|
|
|
|
|
ino = ext4_find_next_zero_bit((unsigned long *)
|
|
|
|
|
|
inode_bitmap_bh->b_data,
|
|
|
|
|
|
EXT4_INODES_PER_GROUP(sb), ino);
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这里面一个重要的逻辑就是,从文件系统里面读取inode位图,然后找到下一个为0的inode,就是空闲的inode。
|
|
|
|
|
|
|
|
|
|
|
|
对于block位图,在写入文件的时候,也会有这个过程,我就不展开说了。感兴趣的话,你可以自己去找代码看。
|
|
|
|
|
|
|
|
|
|
|
|
## 文件系统的格式
|
|
|
|
|
|
|
|
|
|
|
|
看起来,我们现在应该能够很顺利地通过inode位图和block位图创建文件了。如果仔细计算一下,其实还是有问题的。
|
|
|
|
|
|
|
|
|
|
|
|
数据块的位图是放在一个块里面的,共4k。每位表示一个数据块,共可以表示$4 \* 1024 \* 8 = 2^{15}$个数据块。如果每个数据块也是按默认的4K,最大可以表示空间为$2^{15} \* 4 \* 1024 = 2^{27}$个byte,也就是128M。
|
|
|
|
|
|
|
|
|
|
|
|
也就是说按照上面的格式,如果采用“**一个块的位图+一系列的块**”,外加“**一个块的inode的位图+一系列的inode的结构**”,最多能够表示128M。是不是太小了?现在很多文件都比这个大。我们先把这个结构称为一个**块组**。有N多的块组,就能够表示N大的文件。
|
|
|
|
|
|
|
|
|
|
|
|
对于块组,我们也需要一个数据结构来表示为ext4\_group\_desc。这里面对于一个块组里的inode位图bg\_inode\_bitmap\_lo、块位图bg\_block\_bitmap\_lo、inode列表bg\_inode\_table\_lo,都有相应的成员变量。
|
|
|
|
|
|
|
|
|
|
|
|
这样一个个块组,就基本构成了我们整个文件系统的结构。因为块组有多个,块组描述符也同样组成一个列表,我们把这些称为**块组描述符表**。
|
|
|
|
|
|
|
|
|
|
|
|
当然,我们还需要有一个数据结构,对整个文件系统的情况进行描述,这个就是**超级块**ext4\_super\_block。这里面有整个文件系统一共有多少inode,s\_inodes\_count;一共有多少块,s\_blocks\_count\_lo,每个块组有多少inode,s\_inodes\_per\_group,每个块组有多少块,s\_blocks\_per\_group等。这些都是这类的全局信息。
|
|
|
|
|
|
|
|
|
|
|
|
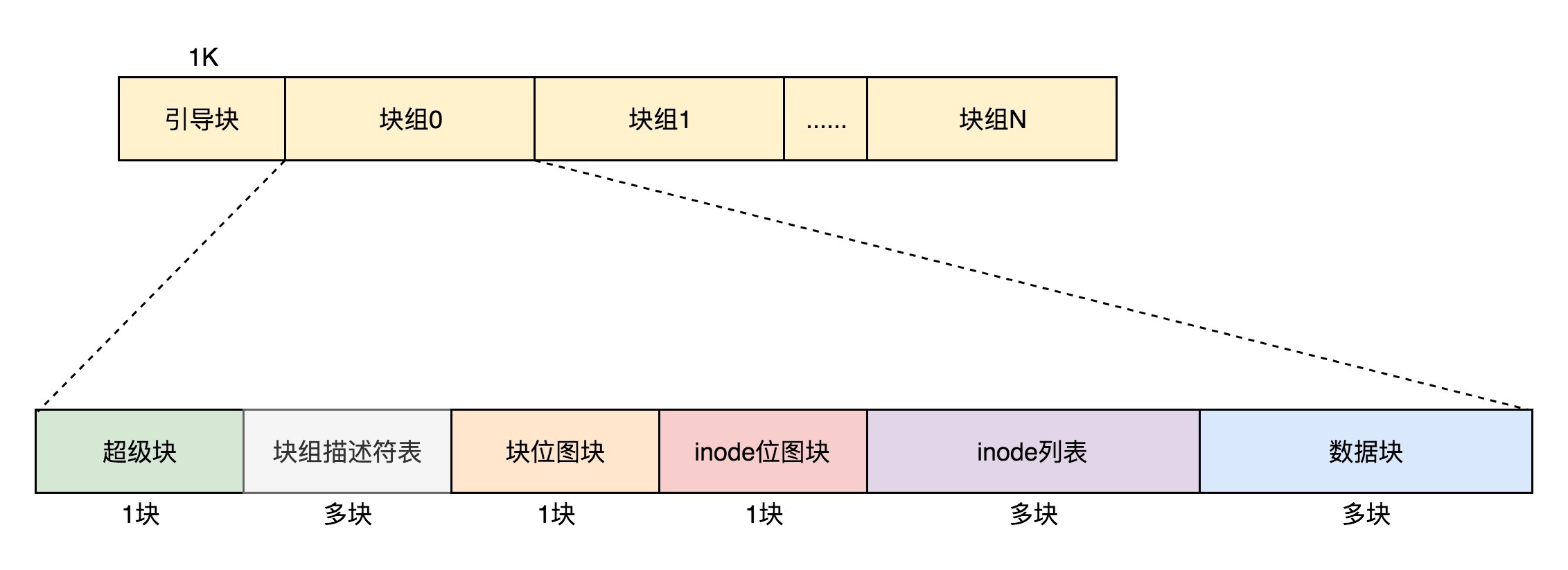
对于整个文件系统,别忘了咱们讲系统启动的时候说的。如果是一个启动盘,我们需要预留一块区域作为引导区,所以第一个块组的前面要留1K,用于启动引导区。
|
|
|
|
|
|
|
|
|
|
|
|
最终,整个文件系统格式就是下面这个样子。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这里面我还需要重点说一下,超级块和块组描述符表都是全局信息,而且这些数据很重要。如果这些数据丢失了,整个文件系统都打不开了,这比一个文件的一个块损坏更严重。所以,这两部分我们都需要备份,但是采取不同的策略。
|
|
|
|
|
|
|
|
|
|
|
|
默认情况下,超级块和块组描述符表都有副本保存在每一个块组里面。
|
|
|
|
|
|
|
|
|
|
|
|
如果开启了sparse\_super特性,超级块和块组描述符表的副本只会保存在块组索引为0、3、5、7的整数幂里。除了块组0中存在一个超级块外,在块组1($3^0=1$)的第一个块中存在一个副本;在块组3($3^1=3$)、块组5($5^1=5$)、块组7($7^1=7$)、块组9($3^2=9$)、块组25($5^2=25$)、块组27($3^3=27$)的第一个block处也存在一个副本。
|
|
|
|
|
|
|
|
|
|
|
|
对于超级块来讲,由于超级块不是很大,所以就算我们备份多了也没有太多问题。但是,对于块组描述符表来讲,如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大128M,而块组描述符表里面有多少项,这就限制了有多少个块组,128M \* 块组的总数目是整个文件系统的大小,就被限制住了。
|
|
|
|
|
|
|
|
|
|
|
|
我们的改进的思路就是引入**Meta Block Groups特性**。
|
|
|
|
|
|
|
|
|
|
|
|
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,我们称为元块组(Meta Block Group)。每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含64个块组,这样一个元块组中的块组描述符表最多64项。我们假设一共有256个块组,原来是一个整的块组描述符表,里面有256项,要备份就全备份,现在分成4个元块组,每个元块组里面的块组描述符表就只有64项了,这就小多了,而且四个元块组自己备份自己的。
|
|
|
|
|
|
|
|
|
|
|
|
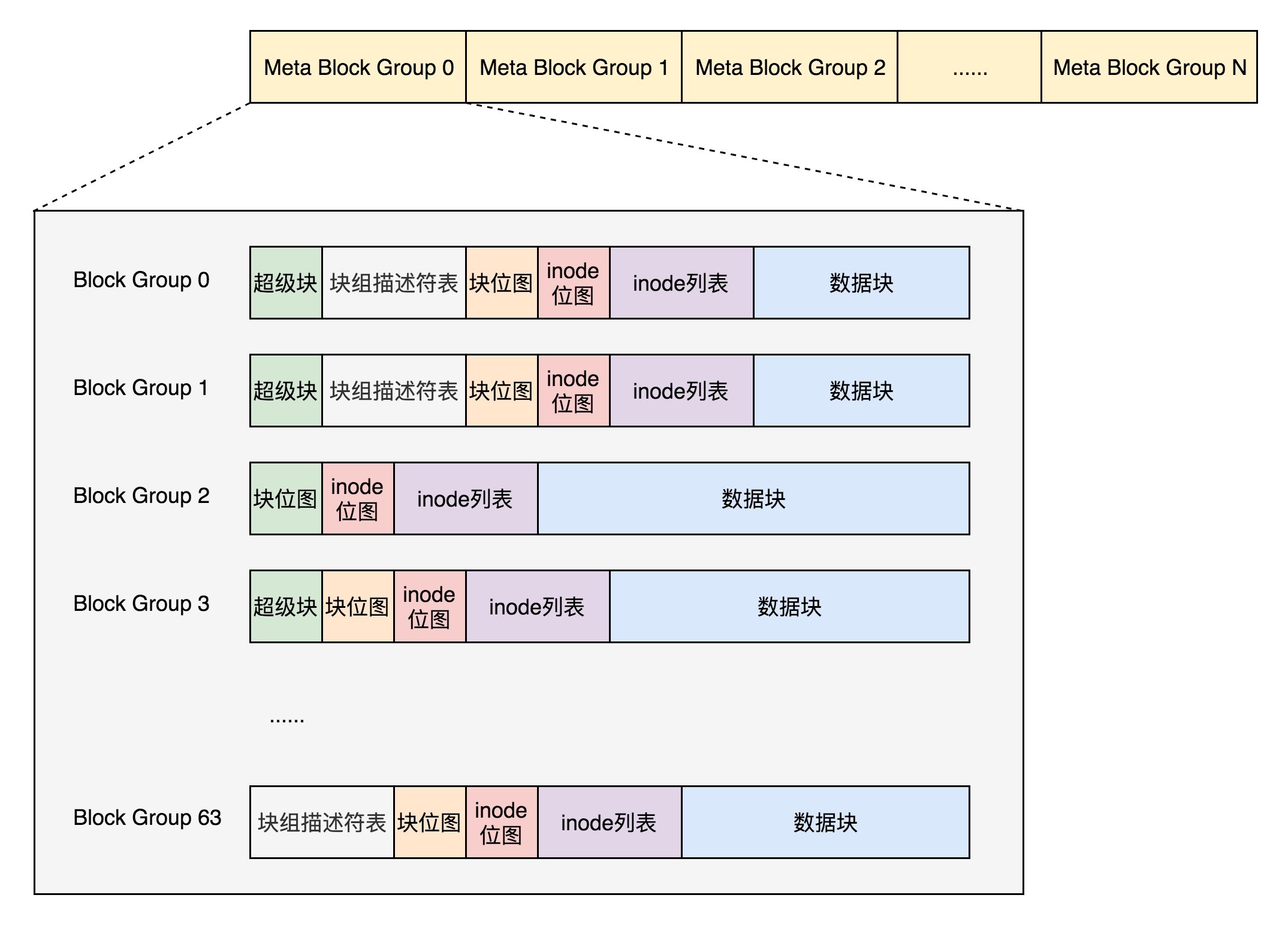
|
|
|
|
|
|
|
|
|
|
|
|
根据图中,每一个元块组包含64个块组,块组描述符表也是64项,备份三份,在元块组的第一个,第二个和最后一个块组的开始处。
|
|
|
|
|
|
|
|
|
|
|
|
这样化整为零,我们就可以发挥出ext4的48位块寻址的优势了,在超级块ext4\_super\_block的定义中,我们可以看到块寻址分为高位和低位,均为32位,其中有用的是48位,2^48个块是1EB,足够用了。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct ext4_super_block {
|
|
|
|
|
|
......
|
|
|
|
|
|
__le32 s_blocks_count_lo; /* Blocks count */
|
|
|
|
|
|
__le32 s_r_blocks_count_lo; /* Reserved blocks count */
|
|
|
|
|
|
__le32 s_free_blocks_count_lo; /* Free blocks count */
|
|
|
|
|
|
......
|
|
|
|
|
|
__le32 s_blocks_count_hi; /* Blocks count */
|
|
|
|
|
|
__le32 s_r_blocks_count_hi; /* Reserved blocks count */
|
|
|
|
|
|
__le32 s_free_blocks_count_hi; /* Free blocks count */
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 目录的存储格式
|
|
|
|
|
|
|
|
|
|
|
|
通过前面的描述,我们现在知道了一个普通的文件是如何存储的。有一类特殊的文件,我们会经常用到,就是目录,它是如何保存的呢?
|
|
|
|
|
|
|
|
|
|
|
|
其实目录本身也是个文件,也有inode。inode里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。这些信息我们称为ext4\_dir\_entry。从代码来看,有两个版本,在成员来讲几乎没有差别,只不过第二个版本ext4\_dir\_entry\_2是将一个16位的name\_len,变成了一个8位的name\_len和8位的file\_type。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct ext4_dir_entry {
|
|
|
|
|
|
__le32 inode; /* Inode number */
|
|
|
|
|
|
__le16 rec_len; /* Directory entry length */
|
|
|
|
|
|
__le16 name_len; /* Name length */
|
|
|
|
|
|
char name[EXT4_NAME_LEN]; /* File name */
|
|
|
|
|
|
};
|
|
|
|
|
|
struct ext4_dir_entry_2 {
|
|
|
|
|
|
__le32 inode; /* Inode number */
|
|
|
|
|
|
__le16 rec_len; /* Directory entry length */
|
|
|
|
|
|
__u8 name_len; /* Name length */
|
|
|
|
|
|
__u8 file_type;
|
|
|
|
|
|
char name[EXT4_NAME_LEN]; /* File name */
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在目录文件的块中,最简单的保存格式是列表,就是一项一项地将ext4\_dir\_entry\_2列在哪里。
|
|
|
|
|
|
|
|
|
|
|
|
每一项都会保存这个目录的下一级的文件的文件名和对应的inode,通过这个inode,就能找到真正的文件。第一项是“.”,表示当前目录,第二项是“…”,表示上一级目录,接下来就是一项一项的文件名和inode。
|
|
|
|
|
|
|
|
|
|
|
|
有时候,如果一个目录下面的文件太多的时候,我们想在这个目录下找一个文件,按照列表一个个去找,太慢了,于是我们就添加了索引的模式。
|
|
|
|
|
|
|
|
|
|
|
|
如果在inode中设置EXT4\_INDEX\_FL标志,则目录文件的块的组织形式将发生变化,变成了下面定义的这个样子:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct dx_root
|
|
|
|
|
|
{
|
|
|
|
|
|
struct fake_dirent dot;
|
|
|
|
|
|
char dot_name[4];
|
|
|
|
|
|
struct fake_dirent dotdot;
|
|
|
|
|
|
char dotdot_name[4];
|
|
|
|
|
|
struct dx_root_info
|
|
|
|
|
|
{
|
|
|
|
|
|
__le32 reserved_zero;
|
|
|
|
|
|
u8 hash_version;
|
|
|
|
|
|
u8 info_length; /* 8 */
|
|
|
|
|
|
u8 indirect_levels;
|
|
|
|
|
|
u8 unused_flags;
|
|
|
|
|
|
}
|
|
|
|
|
|
info;
|
|
|
|
|
|
struct dx_entry entries[0];
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
当然,首先出现的还是差不多的,第一项是“.”,表示当前目录;第二项是“…”,表示上一级目录,这两个不变。接下来就开始发生改变了。是一个dx\_root\_info的结构,其中最重要的成员变量是indirect\_levels,表示间接索引的层数。
|
|
|
|
|
|
|
|
|
|
|
|
接下来我们来看索引项dx\_entry。这个也很简单,其实就是文件名的哈希值和数据块的一个映射关系。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
struct dx_entry
|
|
|
|
|
|
{
|
|
|
|
|
|
__le32 hash;
|
|
|
|
|
|
__le32 block;
|
|
|
|
|
|
};
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是ext4\_dir\_entry\_2的列表,我们只要一项一项找文件名就行。通过索引树,我们可以将一个目录下面的N多的文件分散到很多的块里面,可以很快地进行查找。
|
|
|
|
|
|
|
|
|
|
|
|
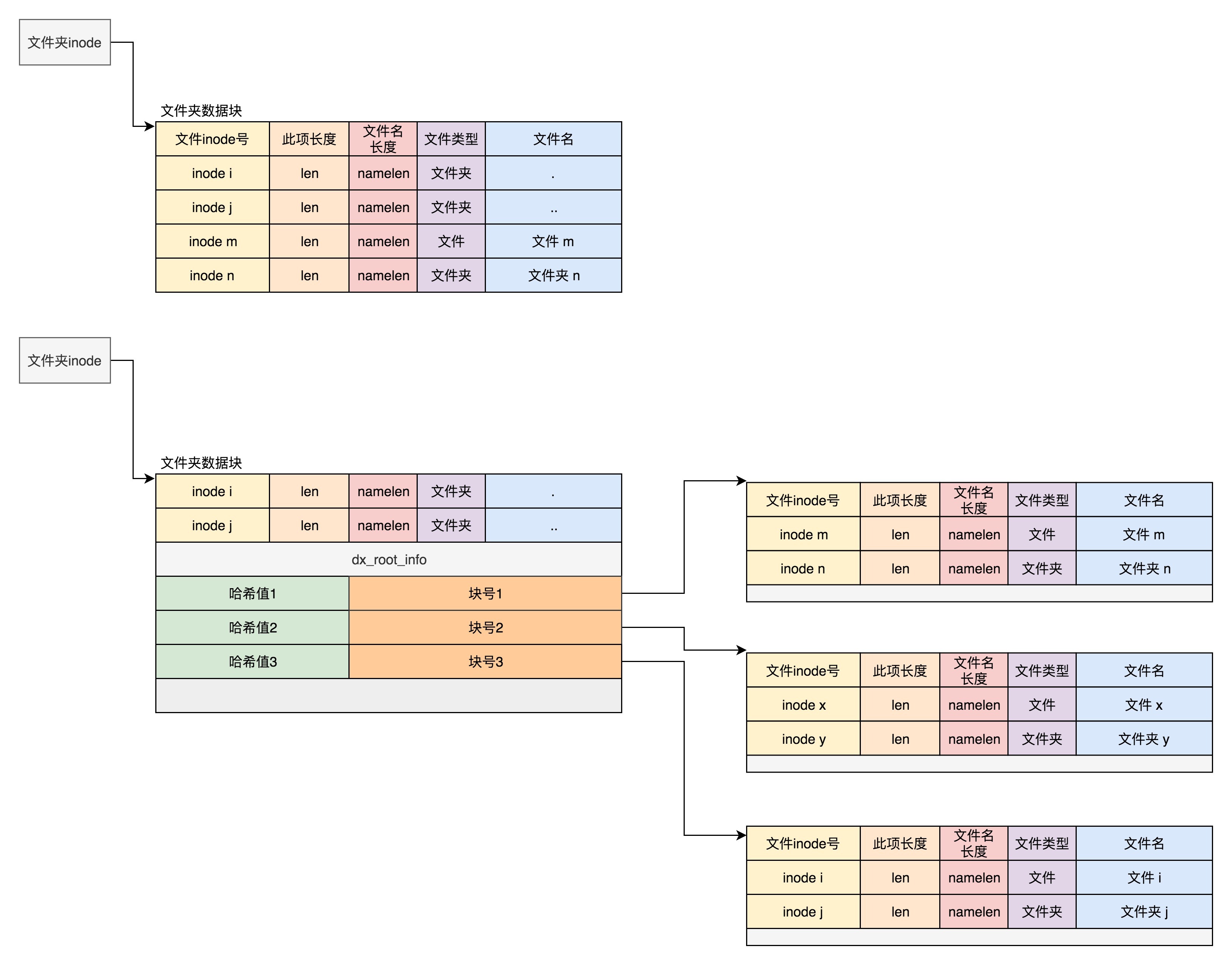
|
|
|
|
|
|
|
|
|
|
|
|
## 软链接和硬链接的存储格式
|
|
|
|
|
|
|
|
|
|
|
|
还有一种特殊的文件格式,硬链接(Hard Link)和软链接(Symbolic Link)。在讲操作文件的命令的时候,我们讲过软链接的概念。所谓的链接(Link),我们可以认为是文件的别名,而链接又可分为两种,硬链接与软链接。通过下面的命令可以创建。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
ln [参数][源文件或目录][目标文件或目录]
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
ln -s创建的是软链接,不带-s创建的是硬链接。它们有什么区别呢?在文件系统里面是怎么保存的呢?
|
|
|
|
|
|
|
|
|
|
|
|
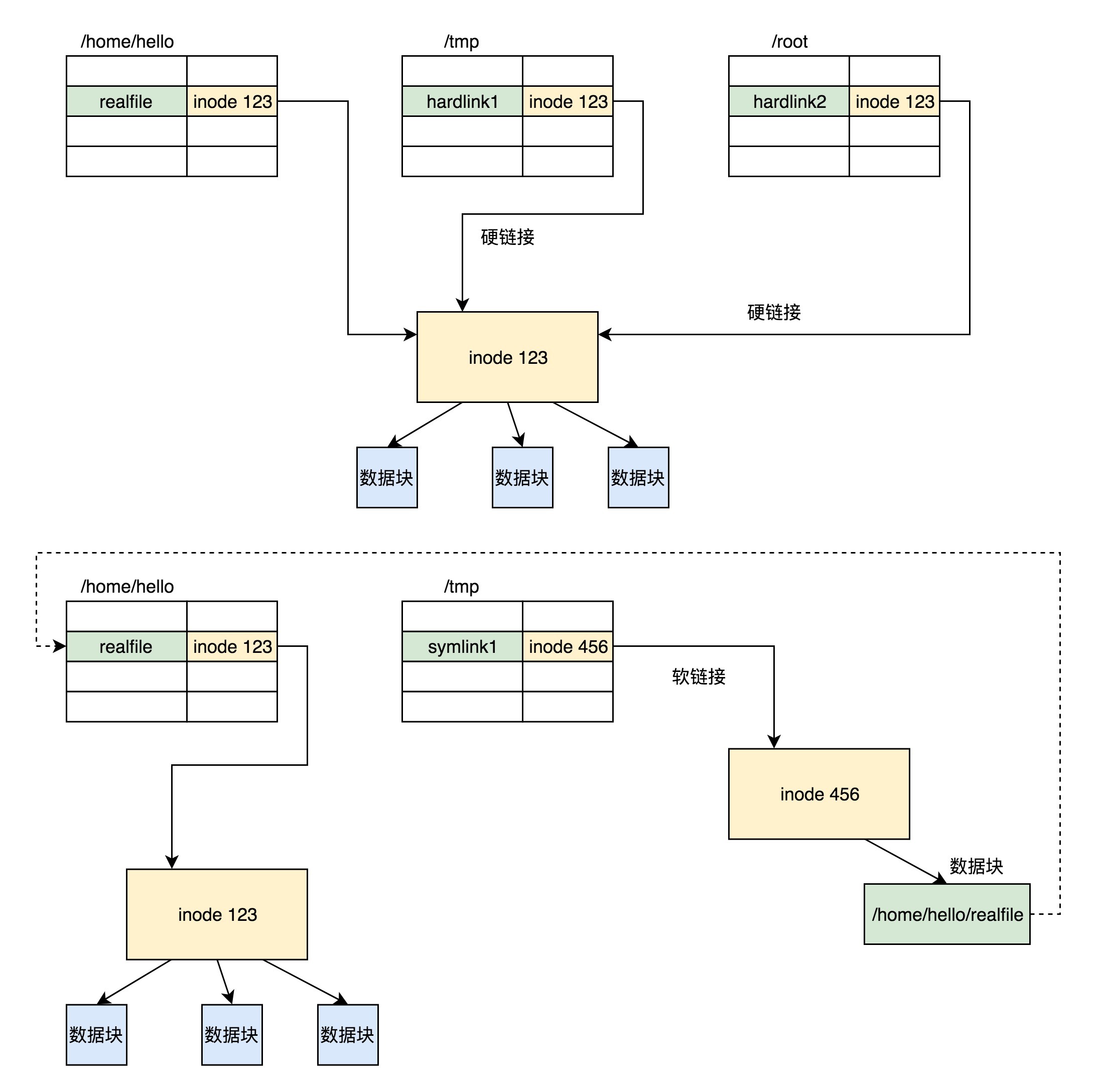
|
|
|
|
|
|
|
|
|
|
|
|
如图所示,硬链接与原始文件共用一个inode的,但是inode是不跨文件系统的,每个文件系统都有自己的inode列表,因而硬链接是没有办法跨文件系统的。
|
|
|
|
|
|
|
|
|
|
|
|
而软链接不同,软链接相当于重新创建了一个文件。这个文件也有独立的inode,只不过打开这个文件看里面内容的时候,内容指向另外的一个文件。这就很灵活了。我们可以跨文件系统,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
|
|
|
|
|
|
|
|
|
|
|
|
## 总结时刻
|
|
|
|
|
|
|
|
|
|
|
|
这一节,我们描述了复杂的硬盘上的文件系统,但是对于咱们平时的应用来讲,用的最多的是两个概念,一个是inode,一个是数据块。
|
|
|
|
|
|
|
|
|
|
|
|
这里我画了一张图,来总结一下inode和数据块在文件系统上的关联关系。
|
|
|
|
|
|
|
|
|
|
|
|
为了表示图中上半部分的那个简单的树形结构,在文件系统上的布局就像图的下半部分一样。无论是文件夹还是文件,都有一个inode。inode里面会指向数据块,对于文件夹的数据块,里面是一个表,是下一层的文件名和inode的对应关系,文件的数据块里面存放的才是真正的数据。
|
|
|
|
|
|
|
|
|
|
|
|
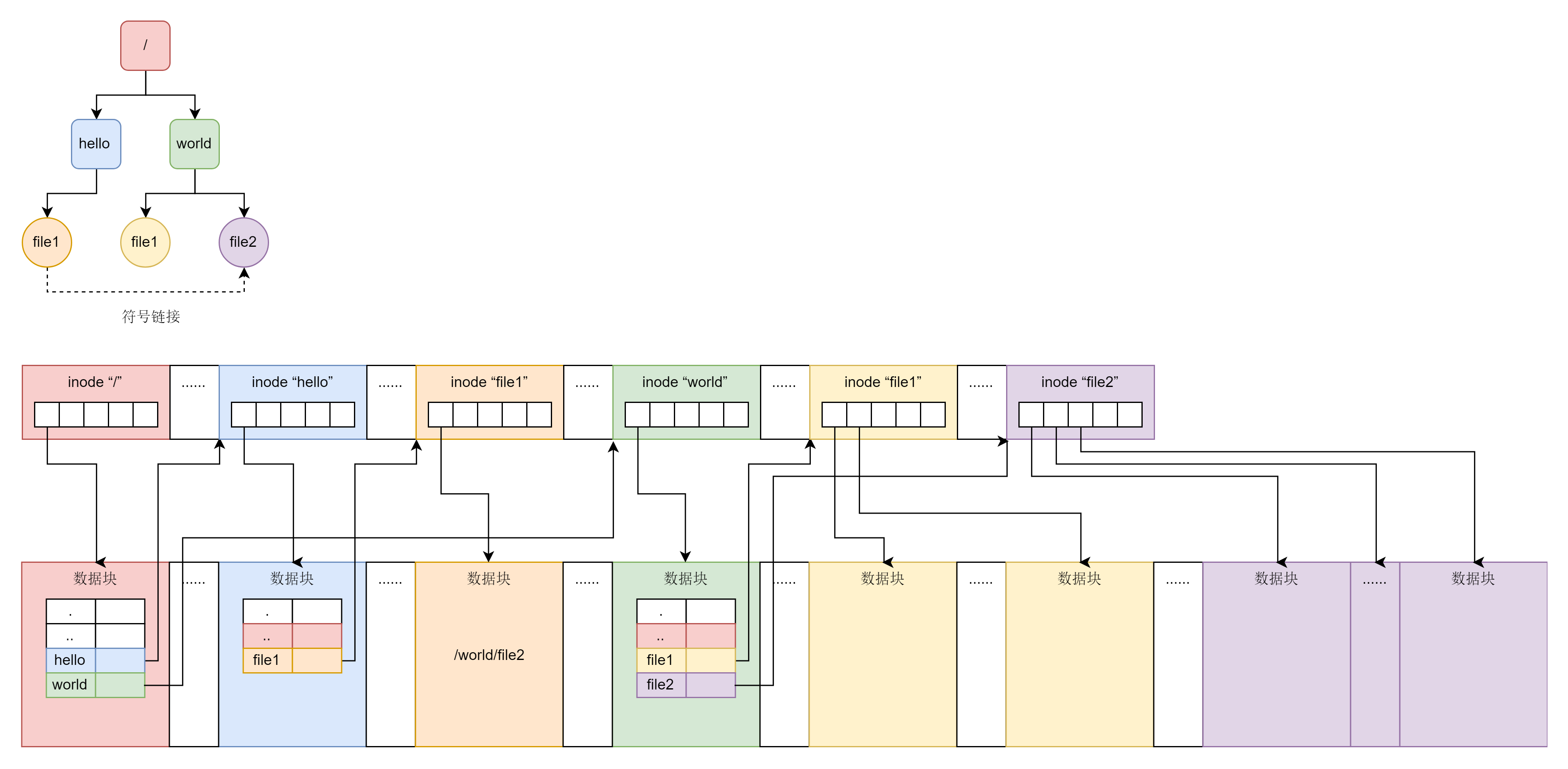
|
|
|
|
|
|
|
|
|
|
|
|
## 课堂练习
|
|
|
|
|
|
|
|
|
|
|
|
你知道如何查看inode的内容和文件夹的内容吗?
|
|
|
|
|
|
|
|
|
|
|
|
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|