928 lines
32 KiB
Markdown
928 lines
32 KiB
Markdown
|
|
# 55 | 网络虚拟化:如何成立独立的合作部?
|
|||
|
|
|
|||
|
|
上一节,我们讲了存储虚拟化,这一节我们来讲网络虚拟化。
|
|||
|
|
|
|||
|
|
网络虚拟化有和存储虚拟化类似的地方,例如,它们都是基于virtio的,因而我们在看网络虚拟化的过程中,会看到和存储虚拟化很像的数据结构和原理。但是,网络虚拟化也有自己的特殊性。例如,存储虚拟化是将宿主机上的文件作为客户机上的硬盘,而网络虚拟化需要依赖于内核协议栈进行网络包的封装与解封装。那怎么实现客户机和宿主机之间的互通呢?我们就一起来看一看。
|
|||
|
|
|
|||
|
|
## 解析初始化过程
|
|||
|
|
|
|||
|
|
我们还是从Virtio Network Device这个设备的初始化讲起。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static const TypeInfo device_type_info = {
|
|||
|
|
.name = TYPE_DEVICE,
|
|||
|
|
.parent = TYPE_OBJECT,
|
|||
|
|
.instance_size = sizeof(DeviceState),
|
|||
|
|
.instance_init = device_initfn,
|
|||
|
|
.instance_post_init = device_post_init,
|
|||
|
|
.instance_finalize = device_finalize,
|
|||
|
|
.class_base_init = device_class_base_init,
|
|||
|
|
.class_init = device_class_init,
|
|||
|
|
.abstract = true,
|
|||
|
|
.class_size = sizeof(DeviceClass),
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
static const TypeInfo virtio_device_info = {
|
|||
|
|
.name = TYPE_VIRTIO_DEVICE,
|
|||
|
|
.parent = TYPE_DEVICE,
|
|||
|
|
.instance_size = sizeof(VirtIODevice),
|
|||
|
|
.class_init = virtio_device_class_init,
|
|||
|
|
.instance_finalize = virtio_device_instance_finalize,
|
|||
|
|
.abstract = true,
|
|||
|
|
.class_size = sizeof(VirtioDeviceClass),
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
static const TypeInfo virtio_net_info = {
|
|||
|
|
.name = TYPE_VIRTIO_NET,
|
|||
|
|
.parent = TYPE_VIRTIO_DEVICE,
|
|||
|
|
.instance_size = sizeof(VirtIONet),
|
|||
|
|
.instance_init = virtio_net_instance_init,
|
|||
|
|
.class_init = virtio_net_class_init,
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
static void virtio_register_types(void)
|
|||
|
|
{
|
|||
|
|
type_register_static(&virtio_net_info);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
type_init(virtio_register_types)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
Virtio Network Device这种类的定义是有多层继承关系的,TYPE\_VIRTIO\_NET的父类是TYPE\_VIRTIO\_DEVICE,TYPE\_VIRTIO\_DEVICE的父类是TYPE\_DEVICE,TYPE\_DEVICE的父类是TYPE\_OBJECT,继承关系到头了。
|
|||
|
|
|
|||
|
|
type\_init用于注册这种类。这里面每一层都有class\_init,用于从TypeImpl生成xxxClass,也有instance\_init,会将xxxClass初始化为实例。
|
|||
|
|
|
|||
|
|
TYPE\_VIRTIO\_NET层的class\_init函数virtio\_net\_class\_init,定义了DeviceClass的realize函数为virtio\_net\_device\_realize,这一点和存储块设备是一样的。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static void virtio_net_device_realize(DeviceState *dev, Error **errp)
|
|||
|
|
{
|
|||
|
|
VirtIODevice *vdev = VIRTIO_DEVICE(dev);
|
|||
|
|
VirtIONet *n = VIRTIO_NET(dev);
|
|||
|
|
NetClientState *nc;
|
|||
|
|
int i;
|
|||
|
|
......
|
|||
|
|
virtio_init(vdev, "virtio-net", VIRTIO_ID_NET, n->config_size);
|
|||
|
|
|
|||
|
|
/*
|
|||
|
|
* We set a lower limit on RX queue size to what it always was.
|
|||
|
|
* Guests that want a smaller ring can always resize it without
|
|||
|
|
* help from us (using virtio 1 and up).
|
|||
|
|
*/
|
|||
|
|
if (n->net_conf.rx_queue_size < VIRTIO_NET_RX_QUEUE_MIN_SIZE ||
|
|||
|
|
n->net_conf.rx_queue_size > VIRTQUEUE_MAX_SIZE ||
|
|||
|
|
!is_power_of_2(n->net_conf.rx_queue_size)) {
|
|||
|
|
......
|
|||
|
|
return;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
if (n->net_conf.tx_queue_size < VIRTIO_NET_TX_QUEUE_MIN_SIZE ||
|
|||
|
|
n->net_conf.tx_queue_size > VIRTQUEUE_MAX_SIZE ||
|
|||
|
|
!is_power_of_2(n->net_conf.tx_queue_size)) {
|
|||
|
|
......
|
|||
|
|
return;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
n->max_queues = MAX(n->nic_conf.peers.queues, 1);
|
|||
|
|
if (n->max_queues * 2 + 1 > VIRTIO_QUEUE_MAX) {
|
|||
|
|
......
|
|||
|
|
return;
|
|||
|
|
}
|
|||
|
|
n->vqs = g_malloc0(sizeof(VirtIONetQueue) * n->max_queues);
|
|||
|
|
n->curr_queues = 1;
|
|||
|
|
......
|
|||
|
|
n->net_conf.tx_queue_size = MIN(virtio_net_max_tx_queue_size(n),
|
|||
|
|
n->net_conf.tx_queue_size);
|
|||
|
|
|
|||
|
|
for (i = 0; i < n->max_queues; i++) {
|
|||
|
|
virtio_net_add_queue(n, i);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
n->ctrl_vq = virtio_add_queue(vdev, 64, virtio_net_handle_ctrl);
|
|||
|
|
qemu_macaddr_default_if_unset(&n->nic_conf.macaddr);
|
|||
|
|
memcpy(&n->mac[0], &n->nic_conf.macaddr, sizeof(n->mac));
|
|||
|
|
n->status = VIRTIO_NET_S_LINK_UP;
|
|||
|
|
|
|||
|
|
if (n->netclient_type) {
|
|||
|
|
n->nic = qemu_new_nic(&net_virtio_info, &n->nic_conf,
|
|||
|
|
n->netclient_type, n->netclient_name, n);
|
|||
|
|
} else {
|
|||
|
|
n->nic = qemu_new_nic(&net_virtio_info, &n->nic_conf,
|
|||
|
|
object_get_typename(OBJECT(dev)), dev->id, n);
|
|||
|
|
}
|
|||
|
|
......
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这里面创建了一个VirtIODevice,这一点和存储虚拟化也是一样的。virtio\_init用来初始化这个设备。VirtIODevice结构里面有一个VirtQueue数组,这就是virtio前端和后端互相传数据的队列,最多有VIRTIO\_QUEUE\_MAX个。
|
|||
|
|
|
|||
|
|
刚才我们说的都是一样的地方,其实也有不一样的地方,我们下面来看。
|
|||
|
|
|
|||
|
|
你会发现,这里面有这样的语句n->max\_queues \* 2 + 1 > VIRTIO\_QUEUE\_MAX。为什么要乘以2呢?这是因为,对于网络设备来讲,应该分发送队列和接收队列两个方向,所以乘以2。
|
|||
|
|
|
|||
|
|
接下来,我们调用virtio\_net\_add\_queue来初始化队列,可以看出来,这里面就有发送tx\_vq和接收rx\_vq两个队列。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
typedef struct VirtIONetQueue {
|
|||
|
|
VirtQueue *rx_vq;
|
|||
|
|
VirtQueue *tx_vq;
|
|||
|
|
QEMUTimer *tx_timer;
|
|||
|
|
QEMUBH *tx_bh;
|
|||
|
|
uint32_t tx_waiting;
|
|||
|
|
struct {
|
|||
|
|
VirtQueueElement *elem;
|
|||
|
|
} async_tx;
|
|||
|
|
struct VirtIONet *n;
|
|||
|
|
} VirtIONetQueue;
|
|||
|
|
|
|||
|
|
static void virtio_net_add_queue(VirtIONet *n, int index)
|
|||
|
|
{
|
|||
|
|
VirtIODevice *vdev = VIRTIO_DEVICE(n);
|
|||
|
|
|
|||
|
|
n->vqs[index].rx_vq = virtio_add_queue(vdev, n->net_conf.rx_queue_size, virtio_net_handle_rx);
|
|||
|
|
|
|||
|
|
......
|
|||
|
|
|
|||
|
|
n->vqs[index].tx_vq = virtio_add_queue(vdev, n->net_conf.tx_queue_size, virtio_net_handle_tx_bh);
|
|||
|
|
n->vqs[index].tx_bh = qemu_bh_new(virtio_net_tx_bh, &n->vqs[index]);
|
|||
|
|
n->vqs[index].n = n;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
每个VirtQueue中,都有一个vring用来维护这个队列里面的数据;另外还有函数virtio\_net\_handle\_rx用于处理网络包的接收;函数virtio\_net\_handle\_tx\_bh用于网络包的发送,这个函数我们后面会用到。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
NICState *qemu_new_nic(NetClientInfo *info,
|
|||
|
|
NICConf *conf,
|
|||
|
|
const char *model,
|
|||
|
|
const char *name,
|
|||
|
|
void *opaque)
|
|||
|
|
{
|
|||
|
|
NetClientState **peers = conf->peers.ncs;
|
|||
|
|
NICState *nic;
|
|||
|
|
int i, queues = MAX(1, conf->peers.queues);
|
|||
|
|
......
|
|||
|
|
nic = g_malloc0(info->size + sizeof(NetClientState) * queues);
|
|||
|
|
nic->ncs = (void *)nic + info->size;
|
|||
|
|
nic->conf = conf;
|
|||
|
|
nic->opaque = opaque;
|
|||
|
|
|
|||
|
|
for (i = 0; i < queues; i++) {
|
|||
|
|
qemu_net_client_setup(&nic->ncs[i], info, peers[i], model, name, NULL);
|
|||
|
|
nic->ncs[i].queue_index = i;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
return nic;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
static void qemu_net_client_setup(NetClientState *nc,
|
|||
|
|
NetClientInfo *info,
|
|||
|
|
NetClientState *peer,
|
|||
|
|
const char *model,
|
|||
|
|
const char *name,
|
|||
|
|
NetClientDestructor *destructor)
|
|||
|
|
{
|
|||
|
|
nc->info = info;
|
|||
|
|
nc->model = g_strdup(model);
|
|||
|
|
if (name) {
|
|||
|
|
nc->name = g_strdup(name);
|
|||
|
|
} else {
|
|||
|
|
nc->name = assign_name(nc, model);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
QTAILQ_INSERT_TAIL(&net_clients, nc, next);
|
|||
|
|
|
|||
|
|
nc->incoming_queue = qemu_new_net_queue(qemu_deliver_packet_iov, nc);
|
|||
|
|
nc->destructor = destructor;
|
|||
|
|
QTAILQ_INIT(&nc->filters);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
接下来,qemu\_new\_nic会创建一个虚拟机里面的网卡。
|
|||
|
|
|
|||
|
|
## qemu的启动过程中的网络虚拟化
|
|||
|
|
|
|||
|
|
初始化过程解析完毕以后,我们接下来从qemu的启动过程看起。
|
|||
|
|
|
|||
|
|
对于网卡的虚拟化,qemu的启动参数里面有关的是下面两行:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
-netdev tap,fd=32,id=hostnet0,vhost=on,vhostfd=37
|
|||
|
|
-device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:d1:2d:99,bus=pci.0,addr=0x3
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
qemu的main函数会调用net\_init\_clients进行网络设备的初始化,可以解析net参数,也可以在net\_init\_clients中解析netdev参数。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int net_init_clients(Error **errp)
|
|||
|
|
{
|
|||
|
|
QTAILQ_INIT(&net_clients);
|
|||
|
|
if (qemu_opts_foreach(qemu_find_opts("netdev"),
|
|||
|
|
net_init_netdev, NULL, errp)) {
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
if (qemu_opts_foreach(qemu_find_opts("nic"), net_param_nic, NULL, errp)) {
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
if (qemu_opts_foreach(qemu_find_opts("net"), net_init_client, NULL, errp)) {
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
net\_init\_clients会解析参数。上面的参数netdev会调用net\_init\_netdev->net\_client\_init->net\_client\_init1。
|
|||
|
|
|
|||
|
|
net\_client\_init1会根据不同的driver类型,调用不同的初始化函数。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static int (* const net_client_init_fun[NET_CLIENT_DRIVER__MAX])(
|
|||
|
|
const Netdev *netdev,
|
|||
|
|
const char *name,
|
|||
|
|
NetClientState *peer, Error **errp) = {
|
|||
|
|
[NET_CLIENT_DRIVER_NIC] = net_init_nic,
|
|||
|
|
[NET_CLIENT_DRIVER_TAP] = net_init_tap,
|
|||
|
|
[NET_CLIENT_DRIVER_SOCKET] = net_init_socket,
|
|||
|
|
[NET_CLIENT_DRIVER_HUBPORT] = net_init_hubport,
|
|||
|
|
......
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
由于我们配置的driver的类型是tap,因而这里会调用net\_init\_tap->net\_tap\_init->tap\_open。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
#define PATH_NET_TUN "/dev/net/tun"
|
|||
|
|
|
|||
|
|
int tap_open(char *ifname, int ifname_size, int *vnet_hdr,
|
|||
|
|
int vnet_hdr_required, int mq_required, Error **errp)
|
|||
|
|
{
|
|||
|
|
struct ifreq ifr;
|
|||
|
|
int fd, ret;
|
|||
|
|
int len = sizeof(struct virtio_net_hdr);
|
|||
|
|
unsigned int features;
|
|||
|
|
|
|||
|
|
TFR(fd = open(PATH_NET_TUN, O_RDWR));
|
|||
|
|
memset(&ifr, 0, sizeof(ifr));
|
|||
|
|
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
|
|||
|
|
|
|||
|
|
if (ioctl(fd, TUNGETFEATURES, &features) == -1) {
|
|||
|
|
features = 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
if (features & IFF_ONE_QUEUE) {
|
|||
|
|
ifr.ifr_flags |= IFF_ONE_QUEUE;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
if (*vnet_hdr) {
|
|||
|
|
if (features & IFF_VNET_HDR) {
|
|||
|
|
*vnet_hdr = 1;
|
|||
|
|
ifr.ifr_flags |= IFF_VNET_HDR;
|
|||
|
|
} else {
|
|||
|
|
*vnet_hdr = 0;
|
|||
|
|
}
|
|||
|
|
ioctl(fd, TUNSETVNETHDRSZ, &len);
|
|||
|
|
}
|
|||
|
|
......
|
|||
|
|
ret = ioctl(fd, TUNSETIFF, (void *) &ifr);
|
|||
|
|
......
|
|||
|
|
fcntl(fd, F_SETFL, O_NONBLOCK);
|
|||
|
|
return fd;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
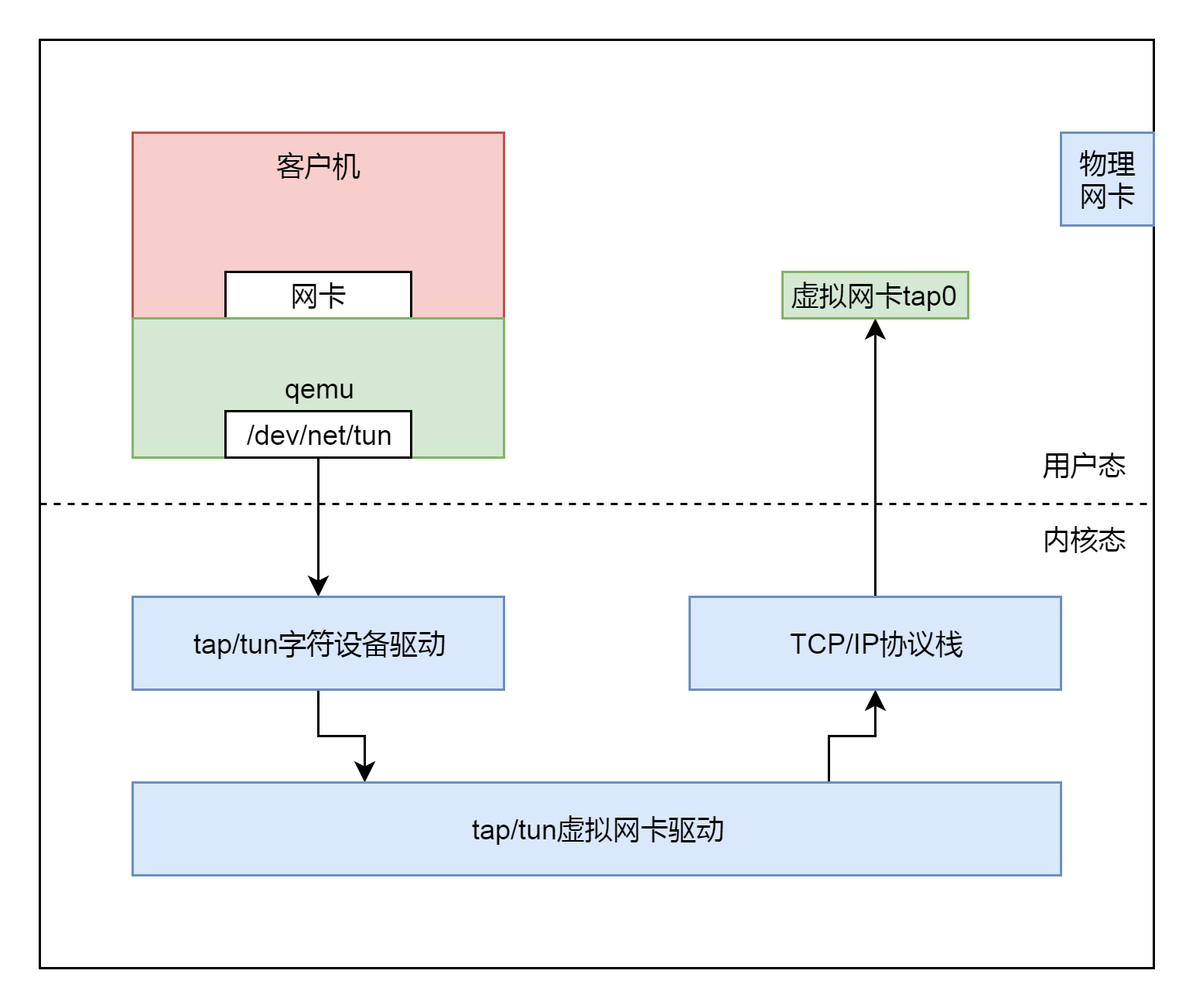
在tap\_open中,我们打开一个文件"/dev/net/tun",然后通过ioctl操作这个文件。这是Linux内核的一项机制,和KVM机制很像。其实这就是一种通过打开这个字符设备文件,然后通过ioctl操作这个文件和内核打交道,来使用内核的能力。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
为什么需要使用内核的机制呢?因为网络包需要从虚拟机里面发送到虚拟机外面,发送到宿主机上的时候,必须是一个正常的网络包才能被转发。要形成一个网络包,我们那就需要经过复杂的协议栈,协议栈的复杂咱们在[发送网络包](https://time.geekbang.org/column/article/106490)那一节讲过了。
|
|||
|
|
|
|||
|
|
客户机会将网络包发送给qemu。qemu自己没有网络协议栈,现去实现一个也不可能,太复杂了。于是,它就要借助内核的力量。
|
|||
|
|
|
|||
|
|
qemu会将客户机发送给它的网络包,然后转换成为文件流,写入"/dev/net/tun"字符设备。就像写一个文件一样。内核中TUN/TAP字符设备驱动会收到这个写入的文件流,然后交给TUN/TAP的虚拟网卡驱动。这个驱动会将文件流再次转成网络包,交给TCP/IP栈,最终从虚拟TAP网卡tap0发出来,成为标准的网络包。后面我们会看到这个过程。
|
|||
|
|
|
|||
|
|
现在我们到内核里面,看一看打开"/dev/net/tun"字符设备后,内核会发生什么事情。内核的实现在drivers/net/tun.c文件中。这是一个字符设备驱动程序,应该符合字符设备的格式。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
module_init(tun_init);
|
|||
|
|
module_exit(tun_cleanup);
|
|||
|
|
MODULE_DESCRIPTION(DRV_DESCRIPTION);
|
|||
|
|
MODULE_AUTHOR(DRV_COPYRIGHT);
|
|||
|
|
MODULE_LICENSE("GPL");
|
|||
|
|
MODULE_ALIAS_MISCDEV(TUN_MINOR);
|
|||
|
|
MODULE_ALIAS("devname:net/tun");
|
|||
|
|
|
|||
|
|
static int __init tun_init(void)
|
|||
|
|
{
|
|||
|
|
......
|
|||
|
|
ret = rtnl_link_register(&tun_link_ops);
|
|||
|
|
......
|
|||
|
|
ret = misc_register(&tun_miscdev);
|
|||
|
|
......
|
|||
|
|
ret = register_netdevice_notifier(&tun_notifier_block);
|
|||
|
|
......
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这里面注册了一个tun\_miscdev字符设备,从它的定义可以看出,这就是"/dev/net/tun"字符设备。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static struct miscdevice tun_miscdev = {
|
|||
|
|
.minor = TUN_MINOR,
|
|||
|
|
.name = "tun",
|
|||
|
|
.nodename = "net/tun",
|
|||
|
|
.fops = &tun_fops,
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
static const struct file_operations tun_fops = {
|
|||
|
|
.owner = THIS_MODULE,
|
|||
|
|
.llseek = no_llseek,
|
|||
|
|
.read_iter = tun_chr_read_iter,
|
|||
|
|
.write_iter = tun_chr_write_iter,
|
|||
|
|
.poll = tun_chr_poll,
|
|||
|
|
.unlocked_ioctl = tun_chr_ioctl,
|
|||
|
|
.open = tun_chr_open,
|
|||
|
|
.release = tun_chr_close,
|
|||
|
|
.fasync = tun_chr_fasync,
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
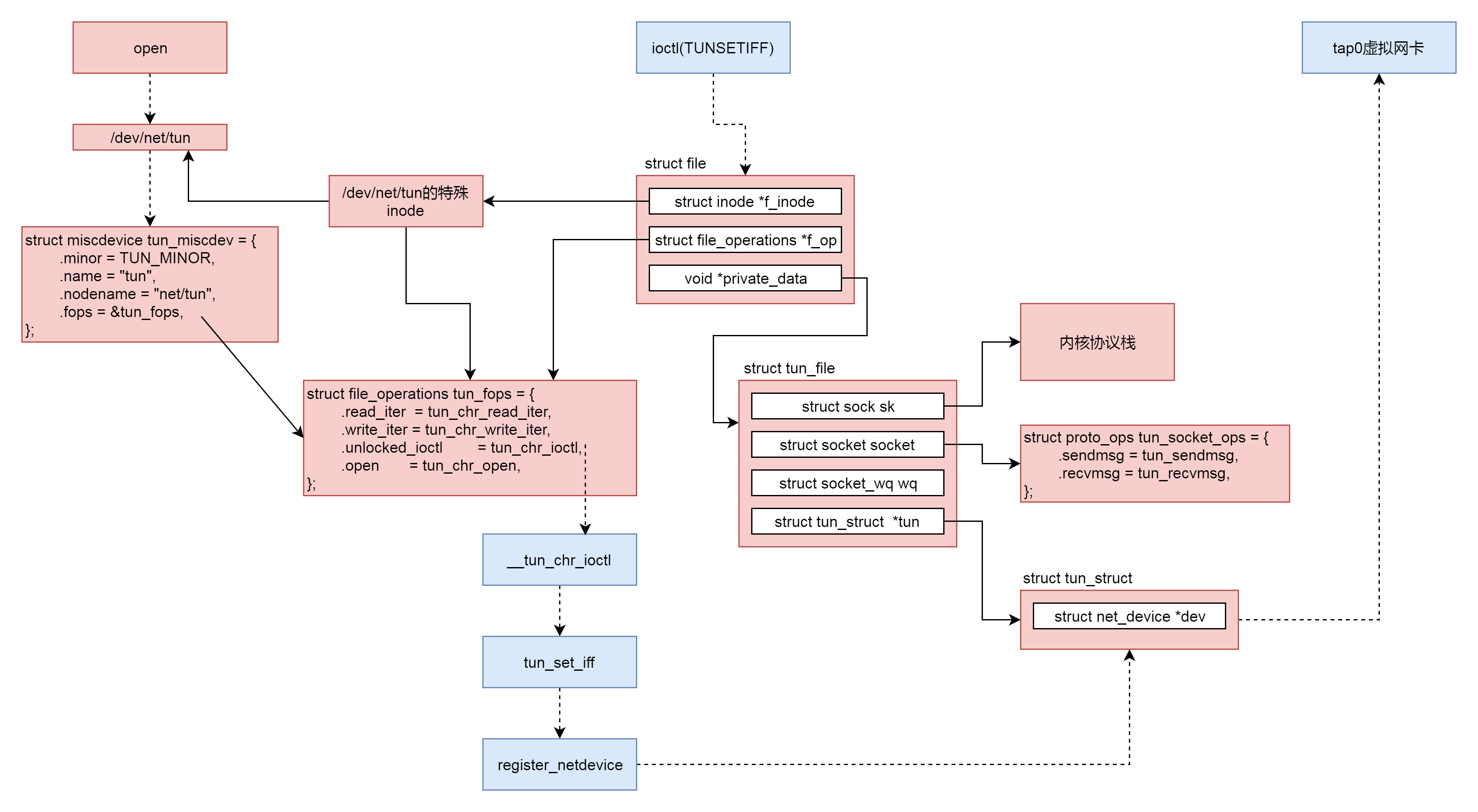
qemu的tap\_open函数会打开这个字符设备PATH\_NET\_TUN。打开字符设备的过程我们不再重复。我就说一下,到了驱动这一层,调用的是tun\_chr\_open。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static int tun_chr_open(struct inode *inode, struct file * file)
|
|||
|
|
{
|
|||
|
|
struct tun_file *tfile;
|
|||
|
|
tfile = (struct tun_file *)sk_alloc(net, AF_UNSPEC, GFP_KERNEL,
|
|||
|
|
&tun_proto, 0);
|
|||
|
|
RCU_INIT_POINTER(tfile->tun, NULL);
|
|||
|
|
tfile->flags = 0;
|
|||
|
|
tfile->ifindex = 0;
|
|||
|
|
|
|||
|
|
init_waitqueue_head(&tfile->wq.wait);
|
|||
|
|
RCU_INIT_POINTER(tfile->socket.wq, &tfile->wq);
|
|||
|
|
|
|||
|
|
tfile->socket.file = file;
|
|||
|
|
tfile->socket.ops = &tun_socket_ops;
|
|||
|
|
|
|||
|
|
sock_init_data(&tfile->socket, &tfile->sk);
|
|||
|
|
|
|||
|
|
tfile->sk.sk_write_space = tun_sock_write_space;
|
|||
|
|
tfile->sk.sk_sndbuf = INT_MAX;
|
|||
|
|
|
|||
|
|
file->private_data = tfile;
|
|||
|
|
INIT_LIST_HEAD(&tfile->next);
|
|||
|
|
|
|||
|
|
sock_set_flag(&tfile->sk, SOCK_ZEROCOPY);
|
|||
|
|
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在tun\_chr\_open的参数里面,有一个struct file,这是代表什么文件呢?它代表的就是打开的字符设备文件"/dev/net/tun",因而往这个字符设备文件中写数据,就会通过这个struct file写入。这个struct file里面的file\_operations,按照字符设备打开的规则,指向的就是tun\_fops。
|
|||
|
|
|
|||
|
|
另外,我们还需要在tun\_chr\_open创建了一个结构struct tun\_file,并且将struct file的private\_data指向它。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
/* A tun_file connects an open character device to a tuntap netdevice. It
|
|||
|
|
* also contains all socket related structures
|
|||
|
|
* to serve as one transmit queue for tuntap device.
|
|||
|
|
*/
|
|||
|
|
struct tun_file {
|
|||
|
|
struct sock sk;
|
|||
|
|
struct socket socket;
|
|||
|
|
struct socket_wq wq;
|
|||
|
|
struct tun_struct __rcu *tun;
|
|||
|
|
struct fasync_struct *fasync;
|
|||
|
|
/* only used for fasnyc */
|
|||
|
|
unsigned int flags;
|
|||
|
|
union {
|
|||
|
|
u16 queue_index;
|
|||
|
|
unsigned int ifindex;
|
|||
|
|
};
|
|||
|
|
struct list_head next;
|
|||
|
|
struct tun_struct *detached;
|
|||
|
|
struct skb_array tx_array;
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
struct tun_struct {
|
|||
|
|
struct tun_file __rcu *tfiles[MAX_TAP_QUEUES];
|
|||
|
|
unsigned int numqueues;
|
|||
|
|
unsigned int flags;
|
|||
|
|
kuid_t owner;
|
|||
|
|
kgid_t group;
|
|||
|
|
|
|||
|
|
struct net_device *dev;
|
|||
|
|
netdev_features_t set_features;
|
|||
|
|
int align;
|
|||
|
|
int vnet_hdr_sz;
|
|||
|
|
int sndbuf;
|
|||
|
|
struct tap_filter txflt;
|
|||
|
|
struct sock_fprog fprog;
|
|||
|
|
/* protected by rtnl lock */
|
|||
|
|
bool filter_attached;
|
|||
|
|
spinlock_t lock;
|
|||
|
|
struct hlist_head flows[TUN_NUM_FLOW_ENTRIES];
|
|||
|
|
struct timer_list flow_gc_timer;
|
|||
|
|
unsigned long ageing_time;
|
|||
|
|
unsigned int numdisabled;
|
|||
|
|
struct list_head disabled;
|
|||
|
|
void *security;
|
|||
|
|
u32 flow_count;
|
|||
|
|
u32 rx_batched;
|
|||
|
|
struct tun_pcpu_stats __percpu *pcpu_stats;
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
static const struct proto_ops tun_socket_ops = {
|
|||
|
|
.peek_len = tun_peek_len,
|
|||
|
|
.sendmsg = tun_sendmsg,
|
|||
|
|
.recvmsg = tun_recvmsg,
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在struct tun\_file中,有一个成员struct tun\_struct,它里面有一个struct net\_device,这个用来表示宿主机上的tuntap网络设备。在struct tun\_file中,还有struct socket和struct sock,因为要用到内核的网络协议栈,所以就需要这两个结构,这在[网络协议](https://time.geekbang.org/column/article/105338)那一节已经分析过了。
|
|||
|
|
|
|||
|
|
所以,按照struct tun\_file的注释说的,这是一个很重要的数据结构。"/dev/net/tun"对应的struct file的private\_data指向它,因而可以接收qemu发过来的数据。除此之外,它还可以通过struct sock来操作内核协议栈,然后将网络包从宿主机上的tuntap网络设备发出去,宿主机上的tuntap网络设备对应的struct net\_device也归它管。
|
|||
|
|
|
|||
|
|
在qemu的tap\_open函数中,打开这个字符设备文件之后,接下来要做的事情是,通过ioctl来设置宿主机的网卡TUNSETIFF。
|
|||
|
|
|
|||
|
|
接下来,ioctl到了内核里面,会调用tun\_chr\_ioctl。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static long __tun_chr_ioctl(struct file *file, unsigned int cmd,
|
|||
|
|
unsigned long arg, int ifreq_len)
|
|||
|
|
{
|
|||
|
|
struct tun_file *tfile = file->private_data;
|
|||
|
|
struct tun_struct *tun;
|
|||
|
|
void __user* argp = (void __user*)arg;
|
|||
|
|
struct ifreq ifr;
|
|||
|
|
kuid_t owner;
|
|||
|
|
kgid_t group;
|
|||
|
|
int sndbuf;
|
|||
|
|
int vnet_hdr_sz;
|
|||
|
|
unsigned int ifindex;
|
|||
|
|
int le;
|
|||
|
|
int ret;
|
|||
|
|
|
|||
|
|
if (cmd == TUNSETIFF || cmd == TUNSETQUEUE || _IOC_TYPE(cmd) == SOCK_IOC_TYPE) {
|
|||
|
|
if (copy_from_user(&ifr, argp, ifreq_len))
|
|||
|
|
return -EFAULT;
|
|||
|
|
}
|
|||
|
|
......
|
|||
|
|
tun = __tun_get(tfile);
|
|||
|
|
if (cmd == TUNSETIFF) {
|
|||
|
|
ifr.ifr_name[IFNAMSIZ-1] = '\0';
|
|||
|
|
ret = tun_set_iff(sock_net(&tfile->sk), file, &ifr);
|
|||
|
|
......
|
|||
|
|
if (copy_to_user(argp, &ifr, ifreq_len))
|
|||
|
|
ret = -EFAULT;
|
|||
|
|
}
|
|||
|
|
......
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在\_\_tun\_chr\_ioctl中,我们首先通过copy\_from\_user把配置从用户态拷贝到内核态,调用tun\_set\_iff设置tuntap网络设备,然后调用copy\_to\_user将配置结果返回。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static int tun_set_iff(struct net *net, struct file *file, struct ifreq *ifr)
|
|||
|
|
{
|
|||
|
|
struct tun_struct *tun;
|
|||
|
|
struct tun_file *tfile = file->private_data;
|
|||
|
|
struct net_device *dev;
|
|||
|
|
......
|
|||
|
|
char *name;
|
|||
|
|
unsigned long flags = 0;
|
|||
|
|
int queues = ifr->ifr_flags & IFF_MULTI_QUEUE ?
|
|||
|
|
MAX_TAP_QUEUES : 1;
|
|||
|
|
|
|||
|
|
if (ifr->ifr_flags & IFF_TUN) {
|
|||
|
|
/* TUN device */
|
|||
|
|
flags |= IFF_TUN;
|
|||
|
|
name = "tun%d";
|
|||
|
|
} else if (ifr->ifr_flags & IFF_TAP) {
|
|||
|
|
/* TAP device */
|
|||
|
|
flags |= IFF_TAP;
|
|||
|
|
name = "tap%d";
|
|||
|
|
} else
|
|||
|
|
return -EINVAL;
|
|||
|
|
|
|||
|
|
if (*ifr->ifr_name)
|
|||
|
|
name = ifr->ifr_name;
|
|||
|
|
|
|||
|
|
dev = alloc_netdev_mqs(sizeof(struct tun_struct), name,
|
|||
|
|
NET_NAME_UNKNOWN, tun_setup, queues,
|
|||
|
|
queues);
|
|||
|
|
|
|||
|
|
err = dev_get_valid_name(net, dev, name);
|
|||
|
|
dev_net_set(dev, net);
|
|||
|
|
dev->rtnl_link_ops = &tun_link_ops;
|
|||
|
|
dev->ifindex = tfile->ifindex;
|
|||
|
|
dev->sysfs_groups[0] = &tun_attr_group;
|
|||
|
|
|
|||
|
|
tun = netdev_priv(dev);
|
|||
|
|
tun->dev = dev;
|
|||
|
|
tun->flags = flags;
|
|||
|
|
tun->txflt.count = 0;
|
|||
|
|
tun->vnet_hdr_sz = sizeof(struct virtio_net_hdr);
|
|||
|
|
|
|||
|
|
tun->align = NET_SKB_PAD;
|
|||
|
|
tun->filter_attached = false;
|
|||
|
|
tun->sndbuf = tfile->socket.sk->sk_sndbuf;
|
|||
|
|
tun->rx_batched = 0;
|
|||
|
|
|
|||
|
|
tun_net_init(dev);
|
|||
|
|
tun_flow_init(tun);
|
|||
|
|
|
|||
|
|
err = tun_attach(tun, file, false);
|
|||
|
|
err = register_netdevice(tun->dev);
|
|||
|
|
|
|||
|
|
netif_carrier_on(tun->dev);
|
|||
|
|
|
|||
|
|
if (netif_running(tun->dev))
|
|||
|
|
netif_tx_wake_all_queues(tun->dev);
|
|||
|
|
|
|||
|
|
strcpy(ifr->ifr_name, tun->dev->name);
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
tun\_set\_iff创建了struct tun\_struct和struct net\_device,并且将这个tuntap网络设备通过register\_netdevice注册到内核中。这样,我们就能在宿主机上通过ip addr看到这个网卡了。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
至此宿主机上的内核的数据结构也完成了。
|
|||
|
|
|
|||
|
|
## 关联前端设备驱动和后端设备驱动
|
|||
|
|
|
|||
|
|
下面,我们来解析在客户机中发送一个网络包的时候,会发生哪些事情。
|
|||
|
|
|
|||
|
|
虚拟机里面的进程发送一个网络包,通过文件系统和Socket调用网络协议栈,到达网络设备层。只不过这个不是普通的网络设备,而是virtio\_net的驱动。
|
|||
|
|
|
|||
|
|
virtio\_net的驱动程序代码在Linux操作系统的源代码里面,文件名为drivers/net/virtio\_net.c。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static __init int virtio_net_driver_init(void)
|
|||
|
|
{
|
|||
|
|
ret = register_virtio_driver(&virtio_net_driver);
|
|||
|
|
......
|
|||
|
|
}
|
|||
|
|
module_init(virtio_net_driver_init);
|
|||
|
|
module_exit(virtio_net_driver_exit);
|
|||
|
|
|
|||
|
|
MODULE_DEVICE_TABLE(virtio, id_table);
|
|||
|
|
MODULE_DESCRIPTION("Virtio network driver");
|
|||
|
|
MODULE_LICENSE("GPL");
|
|||
|
|
|
|||
|
|
static struct virtio_driver virtio_net_driver = {
|
|||
|
|
.driver.name = KBUILD_MODNAME,
|
|||
|
|
.driver.owner = THIS_MODULE,
|
|||
|
|
.id_table = id_table,
|
|||
|
|
.validate = virtnet_validate,
|
|||
|
|
.probe = virtnet_probe,
|
|||
|
|
.remove = virtnet_remove,
|
|||
|
|
.config_changed = virtnet_config_changed,
|
|||
|
|
......
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在virtio\_net的驱动程序的初始化代码中,我们需要注册一个驱动函数virtio\_net\_driver。
|
|||
|
|
|
|||
|
|
当一个设备驱动作为一个内核模块被初始化的时候,probe函数会被调用,因而我们来看一下virtnet\_probe。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static int virtnet_probe(struct virtio_device *vdev)
|
|||
|
|
{
|
|||
|
|
int i, err;
|
|||
|
|
struct net_device *dev;
|
|||
|
|
struct virtnet_info *vi;
|
|||
|
|
u16 max_queue_pairs;
|
|||
|
|
int mtu;
|
|||
|
|
|
|||
|
|
/* Allocate ourselves a network device with room for our info */
|
|||
|
|
dev = alloc_etherdev_mq(sizeof(struct virtnet_info), max_queue_pairs);
|
|||
|
|
|
|||
|
|
/* Set up network device as normal. */
|
|||
|
|
dev->priv_flags |= IFF_UNICAST_FLT | IFF_LIVE_ADDR_CHANGE;
|
|||
|
|
dev->netdev_ops = &virtnet_netdev;
|
|||
|
|
dev->features = NETIF_F_HIGHDMA;
|
|||
|
|
|
|||
|
|
dev->ethtool_ops = &virtnet_ethtool_ops;
|
|||
|
|
SET_NETDEV_DEV(dev, &vdev->dev);
|
|||
|
|
......
|
|||
|
|
/* MTU range: 68 - 65535 */
|
|||
|
|
dev->min_mtu = MIN_MTU;
|
|||
|
|
dev->max_mtu = MAX_MTU;
|
|||
|
|
|
|||
|
|
/* Set up our device-specific information */
|
|||
|
|
vi = netdev_priv(dev);
|
|||
|
|
vi->dev = dev;
|
|||
|
|
vi->vdev = vdev;
|
|||
|
|
vdev->priv = vi;
|
|||
|
|
vi->stats = alloc_percpu(struct virtnet_stats);
|
|||
|
|
INIT_WORK(&vi->config_work, virtnet_config_changed_work);
|
|||
|
|
......
|
|||
|
|
vi->max_queue_pairs = max_queue_pairs;
|
|||
|
|
|
|||
|
|
/* Allocate/initialize the rx/tx queues, and invoke find_vqs */
|
|||
|
|
err = init_vqs(vi);
|
|||
|
|
netif_set_real_num_tx_queues(dev, vi->curr_queue_pairs);
|
|||
|
|
netif_set_real_num_rx_queues(dev, vi->curr_queue_pairs);
|
|||
|
|
|
|||
|
|
virtnet_init_settings(dev);
|
|||
|
|
|
|||
|
|
err = register_netdev(dev);
|
|||
|
|
virtio_device_ready(vdev);
|
|||
|
|
virtnet_set_queues(vi, vi->curr_queue_pairs);
|
|||
|
|
......
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在virtnet\_probe中,会创建struct net\_device,并且通过register\_netdev注册这个网络设备,这样在客户机里面,就能看到这个网卡了。
|
|||
|
|
|
|||
|
|
在virtnet\_probe中,还有一件重要的事情就是,init\_vqs会初始化发送和接收的virtqueue。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static int init_vqs(struct virtnet_info *vi)
|
|||
|
|
{
|
|||
|
|
int ret;
|
|||
|
|
|
|||
|
|
/* Allocate send & receive queues */
|
|||
|
|
ret = virtnet_alloc_queues(vi);
|
|||
|
|
ret = virtnet_find_vqs(vi);
|
|||
|
|
......
|
|||
|
|
get_online_cpus();
|
|||
|
|
virtnet_set_affinity(vi);
|
|||
|
|
put_online_cpus();
|
|||
|
|
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
static int virtnet_alloc_queues(struct virtnet_info *vi)
|
|||
|
|
{
|
|||
|
|
int i;
|
|||
|
|
|
|||
|
|
vi->sq = kzalloc(sizeof(*vi->sq) * vi->max_queue_pairs, GFP_KERNEL);
|
|||
|
|
vi->rq = kzalloc(sizeof(*vi->rq) * vi->max_queue_pairs, GFP_KERNEL);
|
|||
|
|
|
|||
|
|
INIT_DELAYED_WORK(&vi->refill, refill_work);
|
|||
|
|
for (i = 0; i < vi->max_queue_pairs; i++) {
|
|||
|
|
vi->rq[i].pages = NULL;
|
|||
|
|
netif_napi_add(vi->dev, &vi->rq[i].napi, virtnet_poll,
|
|||
|
|
napi_weight);
|
|||
|
|
netif_tx_napi_add(vi->dev, &vi->sq[i].napi, virtnet_poll_tx,
|
|||
|
|
napi_tx ? napi_weight : 0);
|
|||
|
|
|
|||
|
|
sg_init_table(vi->rq[i].sg, ARRAY_SIZE(vi->rq[i].sg));
|
|||
|
|
ewma_pkt_len_init(&vi->rq[i].mrg_avg_pkt_len);
|
|||
|
|
sg_init_table(vi->sq[i].sg, ARRAY_SIZE(vi->sq[i].sg));
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
按照上一节的virtio原理,virtqueue是一个介于客户机前端和qemu后端的一个结构,用于在这两端之间传递数据,对于网络设备来讲有发送和接收两个方向的队列。这里建立的struct virtqueue是客户机前端对于队列的管理的数据结构。
|
|||
|
|
|
|||
|
|
队列的实体需要通过函数virtnet\_find\_vqs查找或者生成,这里还会指定接收队列的callback函数为skb\_recv\_done,发送队列的callback函数为skb\_xmit\_done。那当buffer使用发生变化的时候,我们可以调用这个callback函数进行通知。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static int virtnet_find_vqs(struct virtnet_info *vi)
|
|||
|
|
{
|
|||
|
|
vq_callback_t **callbacks;
|
|||
|
|
struct virtqueue **vqs;
|
|||
|
|
int ret = -ENOMEM;
|
|||
|
|
int i, total_vqs;
|
|||
|
|
const char **names;
|
|||
|
|
|
|||
|
|
/* Allocate space for find_vqs parameters */
|
|||
|
|
vqs = kzalloc(total_vqs * sizeof(*vqs), GFP_KERNEL);
|
|||
|
|
callbacks = kmalloc(total_vqs * sizeof(*callbacks), GFP_KERNEL);
|
|||
|
|
names = kmalloc(total_vqs * sizeof(*names), GFP_KERNEL);
|
|||
|
|
|
|||
|
|
/* Allocate/initialize parameters for send/receive virtqueues */
|
|||
|
|
for (i = 0; i < vi->max_queue_pairs; i++) {
|
|||
|
|
callbacks[rxq2vq(i)] = skb_recv_done;
|
|||
|
|
callbacks[txq2vq(i)] = skb_xmit_done;
|
|||
|
|
names[rxq2vq(i)] = vi->rq[i].name;
|
|||
|
|
names[txq2vq(i)] = vi->sq[i].name;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
ret = vi->vdev->config->find_vqs(vi->vdev, total_vqs, vqs, callbacks, names, ctx, NULL);
|
|||
|
|
......
|
|||
|
|
for (i = 0; i < vi->max_queue_pairs; i++) {
|
|||
|
|
vi->rq[i].vq = vqs[rxq2vq(i)];
|
|||
|
|
vi->rq[i].min_buf_len = mergeable_min_buf_len(vi, vi->rq[i].vq);
|
|||
|
|
vi->sq[i].vq = vqs[txq2vq(i)];
|
|||
|
|
}
|
|||
|
|
......
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这里的find\_vqs是在struct virtnet\_info里的struct virtio\_device里的struct virtio\_config\_ops \*config里面定义的。
|
|||
|
|
|
|||
|
|
根据virtio\_config\_ops的定义,find\_vqs会调用vp\_modern\_find\_vqs,到这一步和块设备是一样的了。
|
|||
|
|
|
|||
|
|
在vp\_modern\_find\_vqs中,vp\_find\_vqs会调用vp\_find\_vqs\_intx。在vp\_find\_vqs\_intx中,通过request\_irq注册一个中断处理函数vp\_interrupt。当设备向队列中写入信息时,会产生一个中断,也就是vq中断。中断处理函数需要调用相应的队列的回调函数,然后根据队列的数目,依次调用vp\_setup\_vq完成virtqueue、vring的分配和初始化。
|
|||
|
|
|
|||
|
|
同样,这些数据结构会和virtio后端的VirtIODevice、VirtQueue、vring对应起来,都应该指向刚才创建的那一段内存。
|
|||
|
|
|
|||
|
|
客户机同样会通过调用专门给外部设备发送指令的函数iowrite告诉外部的pci设备,这些共享内存的地址。
|
|||
|
|
|
|||
|
|
至此前端设备驱动和后端设备驱动之间的两个收发队列就关联好了,这两个队列的格式和块设备是一样的。
|
|||
|
|
|
|||
|
|
## 发送网络包过程
|
|||
|
|
|
|||
|
|
接下来,我们来看当真的发送一个网络包的时候,会发生什么。
|
|||
|
|
|
|||
|
|
当网络包经过客户机的协议栈到达virtio\_net驱动的时候,按照net\_device\_ops的定义,start\_xmit会被调用。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static const struct net_device_ops virtnet_netdev = {
|
|||
|
|
.ndo_open = virtnet_open,
|
|||
|
|
.ndo_stop = virtnet_close,
|
|||
|
|
.ndo_start_xmit = start_xmit,
|
|||
|
|
.ndo_validate_addr = eth_validate_addr,
|
|||
|
|
.ndo_set_mac_address = virtnet_set_mac_address,
|
|||
|
|
.ndo_set_rx_mode = virtnet_set_rx_mode,
|
|||
|
|
.ndo_get_stats64 = virtnet_stats,
|
|||
|
|
.ndo_vlan_rx_add_vid = virtnet_vlan_rx_add_vid,
|
|||
|
|
.ndo_vlan_rx_kill_vid = virtnet_vlan_rx_kill_vid,
|
|||
|
|
.ndo_xdp = virtnet_xdp,
|
|||
|
|
.ndo_features_check = passthru_features_check,
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
接下来的调用链为:start\_xmit->xmit\_skb-> virtqueue\_add\_outbuf->virtqueue\_add,将网络包放入队列中,并调用virtqueue\_notify通知接收方。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static netdev_tx_t start_xmit(struct sk_buff *skb, struct net_device *dev)
|
|||
|
|
{
|
|||
|
|
struct virtnet_info *vi = netdev_priv(dev);
|
|||
|
|
int qnum = skb_get_queue_mapping(skb);
|
|||
|
|
struct send_queue *sq = &vi->sq[qnum];
|
|||
|
|
int err;
|
|||
|
|
struct netdev_queue *txq = netdev_get_tx_queue(dev, qnum);
|
|||
|
|
bool kick = !skb->xmit_more;
|
|||
|
|
bool use_napi = sq->napi.weight;
|
|||
|
|
......
|
|||
|
|
/* Try to transmit */
|
|||
|
|
err = xmit_skb(sq, skb);
|
|||
|
|
......
|
|||
|
|
if (kick || netif_xmit_stopped(txq))
|
|||
|
|
virtqueue_kick(sq->vq);
|
|||
|
|
return NETDEV_TX_OK;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
bool virtqueue_kick(struct virtqueue *vq)
|
|||
|
|
{
|
|||
|
|
if (virtqueue_kick_prepare(vq))
|
|||
|
|
return virtqueue_notify(vq);
|
|||
|
|
return true;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
写入一个I/O会使得qemu触发VM exit,这个逻辑我们在解析CPU的时候看到过。
|
|||
|
|
|
|||
|
|
接下来,我们那会调用VirtQueue的handle\_output函数。前面我们已经设置过这个函数了,其实就是virtio\_net\_handle\_tx\_bh。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static void virtio_net_handle_tx_bh(VirtIODevice *vdev, VirtQueue *vq)
|
|||
|
|
{
|
|||
|
|
VirtIONet *n = VIRTIO_NET(vdev);
|
|||
|
|
VirtIONetQueue *q = &n->vqs[vq2q(virtio_get_queue_index(vq))];
|
|||
|
|
|
|||
|
|
q->tx_waiting = 1;
|
|||
|
|
|
|||
|
|
virtio_queue_set_notification(vq, 0);
|
|||
|
|
qemu_bh_schedule(q->tx_bh);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
virtio\_net\_handle\_tx\_bh调用了qemu\_bh\_schedule,而在virtio\_net\_add\_queue中调用qemu\_bh\_new,并把函数设置为virtio\_net\_tx\_bh。
|
|||
|
|
|
|||
|
|
virtio\_net\_tx\_bh函数调用发送函数virtio\_net\_flush\_tx。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static int32_t virtio_net_flush_tx(VirtIONetQueue *q)
|
|||
|
|
{
|
|||
|
|
VirtIONet *n = q->n;
|
|||
|
|
VirtIODevice *vdev = VIRTIO_DEVICE(n);
|
|||
|
|
VirtQueueElement *elem;
|
|||
|
|
int32_t num_packets = 0;
|
|||
|
|
int queue_index = vq2q(virtio_get_queue_index(q->tx_vq));
|
|||
|
|
|
|||
|
|
for (;;) {
|
|||
|
|
ssize_t ret;
|
|||
|
|
unsigned int out_num;
|
|||
|
|
struct iovec sg[VIRTQUEUE_MAX_SIZE], sg2[VIRTQUEUE_MAX_SIZE + 1], *out_sg;
|
|||
|
|
struct virtio_net_hdr_mrg_rxbuf mhdr;
|
|||
|
|
|
|||
|
|
elem = virtqueue_pop(q->tx_vq, sizeof(VirtQueueElement));
|
|||
|
|
out_num = elem->out_num;
|
|||
|
|
out_sg = elem->out_sg;
|
|||
|
|
......
|
|||
|
|
ret = qemu_sendv_packet_async(qemu_get_subqueue(n->nic, queue_index),out_sg, out_num, virtio_net_tx_complete);
|
|||
|
|
}
|
|||
|
|
......
|
|||
|
|
return num_packets;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
virtio\_net\_flush\_tx会调用virtqueue\_pop。这里面,我们能看到对于vring的操作,也即从这里面将客户机里面写入的数据读取出来。
|
|||
|
|
|
|||
|
|
然后,我们调用qemu\_sendv\_packet\_async发送网络包。接下来的调用链为:qemu\_sendv\_packet\_async->qemu\_net\_queue\_send\_iov->qemu\_net\_queue\_flush->qemu\_net\_queue\_deliver。
|
|||
|
|
|
|||
|
|
在qemu\_net\_queue\_deliver中,我们会调用NetQueue的deliver函数。前面qemu\_new\_net\_queue会把deliver函数设置为qemu\_deliver\_packet\_iov。它会调用nc->info->receive\_iov。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static NetClientInfo net_tap_info = {
|
|||
|
|
.type = NET_CLIENT_DRIVER_TAP,
|
|||
|
|
.size = sizeof(TAPState),
|
|||
|
|
.receive = tap_receive,
|
|||
|
|
.receive_raw = tap_receive_raw,
|
|||
|
|
.receive_iov = tap_receive_iov,
|
|||
|
|
.poll = tap_poll,
|
|||
|
|
.cleanup = tap_cleanup,
|
|||
|
|
.has_ufo = tap_has_ufo,
|
|||
|
|
.has_vnet_hdr = tap_has_vnet_hdr,
|
|||
|
|
.has_vnet_hdr_len = tap_has_vnet_hdr_len,
|
|||
|
|
.using_vnet_hdr = tap_using_vnet_hdr,
|
|||
|
|
.set_offload = tap_set_offload,
|
|||
|
|
.set_vnet_hdr_len = tap_set_vnet_hdr_len,
|
|||
|
|
.set_vnet_le = tap_set_vnet_le,
|
|||
|
|
.set_vnet_be = tap_set_vnet_be,
|
|||
|
|
};
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
根据net\_tap\_info的定义调用的是tap\_receive\_iov。他会调用tap\_write\_packet->writev写入这个字符设备。
|
|||
|
|
|
|||
|
|
在内核的字符设备驱动中,tun\_chr\_write\_iter会被调用。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
static ssize_t tun_chr_write_iter(struct kiocb *iocb, struct iov_iter *from)
|
|||
|
|
{
|
|||
|
|
struct file *file = iocb->ki_filp;
|
|||
|
|
struct tun_struct *tun = tun_get(file);
|
|||
|
|
struct tun_file *tfile = file->private_data;
|
|||
|
|
ssize_t result;
|
|||
|
|
|
|||
|
|
result = tun_get_user(tun, tfile, NULL, from,
|
|||
|
|
file->f_flags & O_NONBLOCK, false);
|
|||
|
|
|
|||
|
|
tun_put(tun);
|
|||
|
|
return result;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
当我们使用writev()系统调用向tun/tap设备的字符设备文件写入数据时,tun\_chr\_write函数将被调用。它会使用tun\_get\_user,从用户区接收数据,将数据存入skb中,然后调用关键的函数netif\_rx\_ni(skb) ,将skb送给tcp/ip协议栈处理,最终完成虚拟网卡的数据接收。
|
|||
|
|
|
|||
|
|
至此,从虚拟机内部到宿主机的网络传输过程才算结束。
|
|||
|
|
|
|||
|
|
## 总结时刻
|
|||
|
|
|
|||
|
|
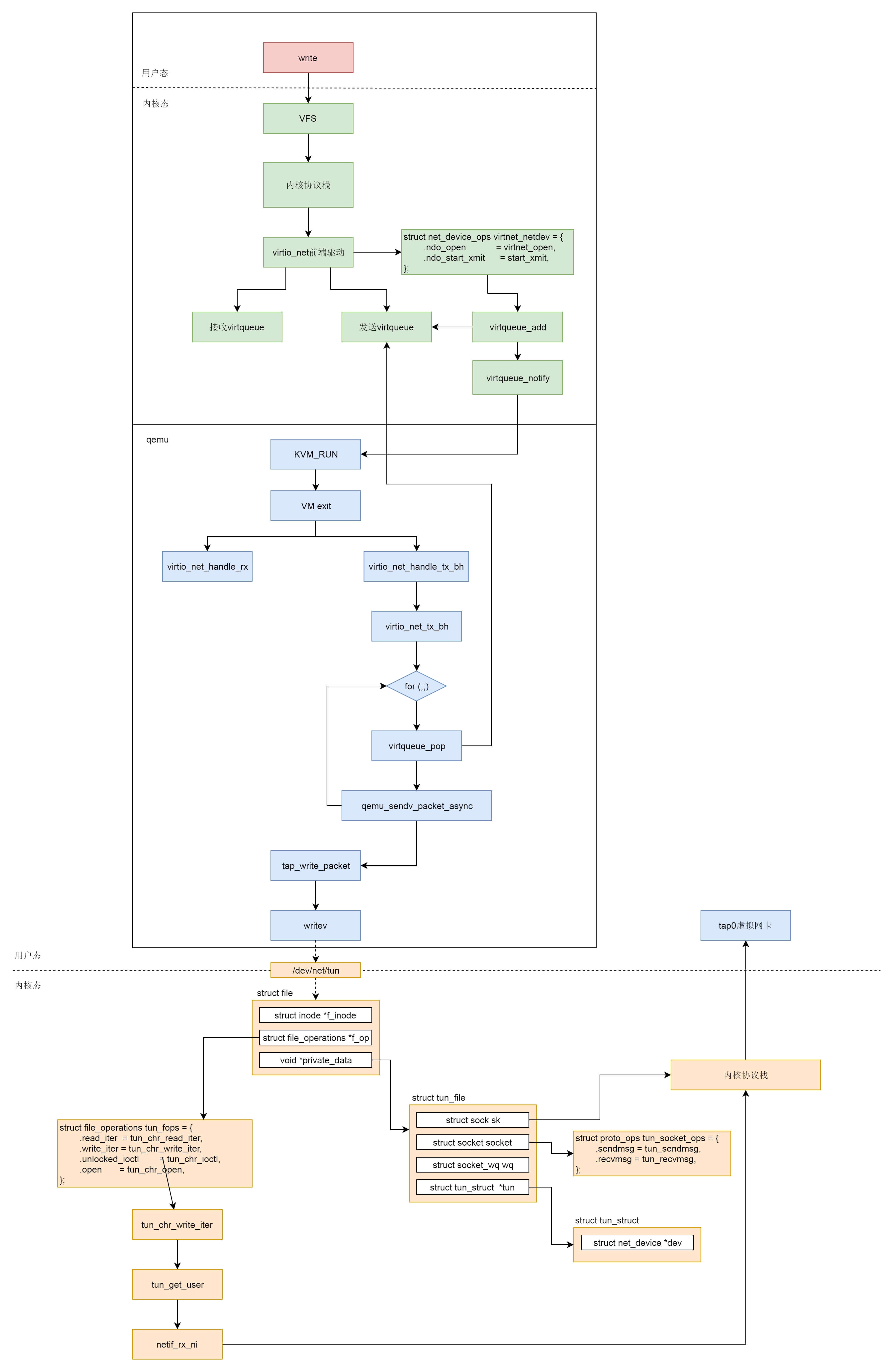
最后,我们把网络虚拟化场景下网络包的发送过程总结一下。
|
|||
|
|
|
|||
|
|
* 在虚拟机里面的用户态,应用程序通过write系统调用写入socket。
|
|||
|
|
* 写入的内容经过VFS层,内核协议栈,到达虚拟机里面的内核的网络设备驱动,也即virtio\_net。
|
|||
|
|
* virtio\_net网络设备有一个操作结构struct net\_device\_ops,里面定义了发送一个网络包调用的函数为start\_xmit。
|
|||
|
|
* 在virtio\_net的前端驱动和qemu中的后端驱动之间,有两个队列virtqueue,一个用于发送,一个用于接收。然后,我们需要在start\_xmit中调用virtqueue\_add,将网络包放入发送队列,然后调用virtqueue\_notify通知qemu。
|
|||
|
|
* qemu本来处于KVM\_RUN的状态,收到通知后,通过VM exit指令退出客户机模式,进入宿主机模式。发送网络包的时候,virtio\_net\_handle\_tx\_bh函数会被调用。
|
|||
|
|
* 接下来是一个for循环,我们需要在循环中调用virtqueue\_pop,从传输队列中获取要发送的数据,然后调用qemu\_sendv\_packet\_async进行发送。
|
|||
|
|
* qemu会调用writev向字符设备文件写入,进入宿主机的内核。
|
|||
|
|
* 在宿主机内核中字符设备文件的file\_operations里面的write\_iter会被调用,也即会调用tun\_chr\_write\_iter。
|
|||
|
|
* 在tun\_chr\_write\_iter函数中,tun\_get\_user将要发送的网络包从qemu拷贝到宿主机内核里面来,然后调用netif\_rx\_ni开始调用宿主机内核协议栈进行处理。
|
|||
|
|
* 宿主机内核协议栈处理完毕之后,会发送给tap虚拟网卡,完成从虚拟机里面到宿主机的整个发送过程。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
## 课堂练习
|
|||
|
|
|
|||
|
|
这一节我们解析的是发送过程,请你根据类似的思路,解析一下接收过程。
|
|||
|
|
|
|||
|
|
欢迎留言和我分享你的疑惑和见解,也欢迎收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|