237 lines
18 KiB
Markdown
237 lines
18 KiB
Markdown
|
|
# 29|落地实践:搭建可持续度量的技术平台
|
|||
|
|
|
|||
|
|
你好,我是柳胜。
|
|||
|
|
|
|||
|
|
前面我们花了不少篇幅来讨论度量体系的设计,在方法论上扫清了障碍。
|
|||
|
|
|
|||
|
|
理论讲得通,实践也要做得通。想要在工作中落地、出效果,那就一定要把度量可视化。什么是度量可视化呢?简单来说,就是让相关人员能直观看到度量展现出来的样子。
|
|||
|
|
|
|||
|
|
在正文开始之前,我先分享几个可视化的例子,帮你建立更直观的感受。就拿单标度量来说,它通常是一个数字值。比如冒烟自动化测试覆盖率38.14%,就可以展现成下面这样的数字仪表盘。
|
|||
|
|
|
|||
|
|
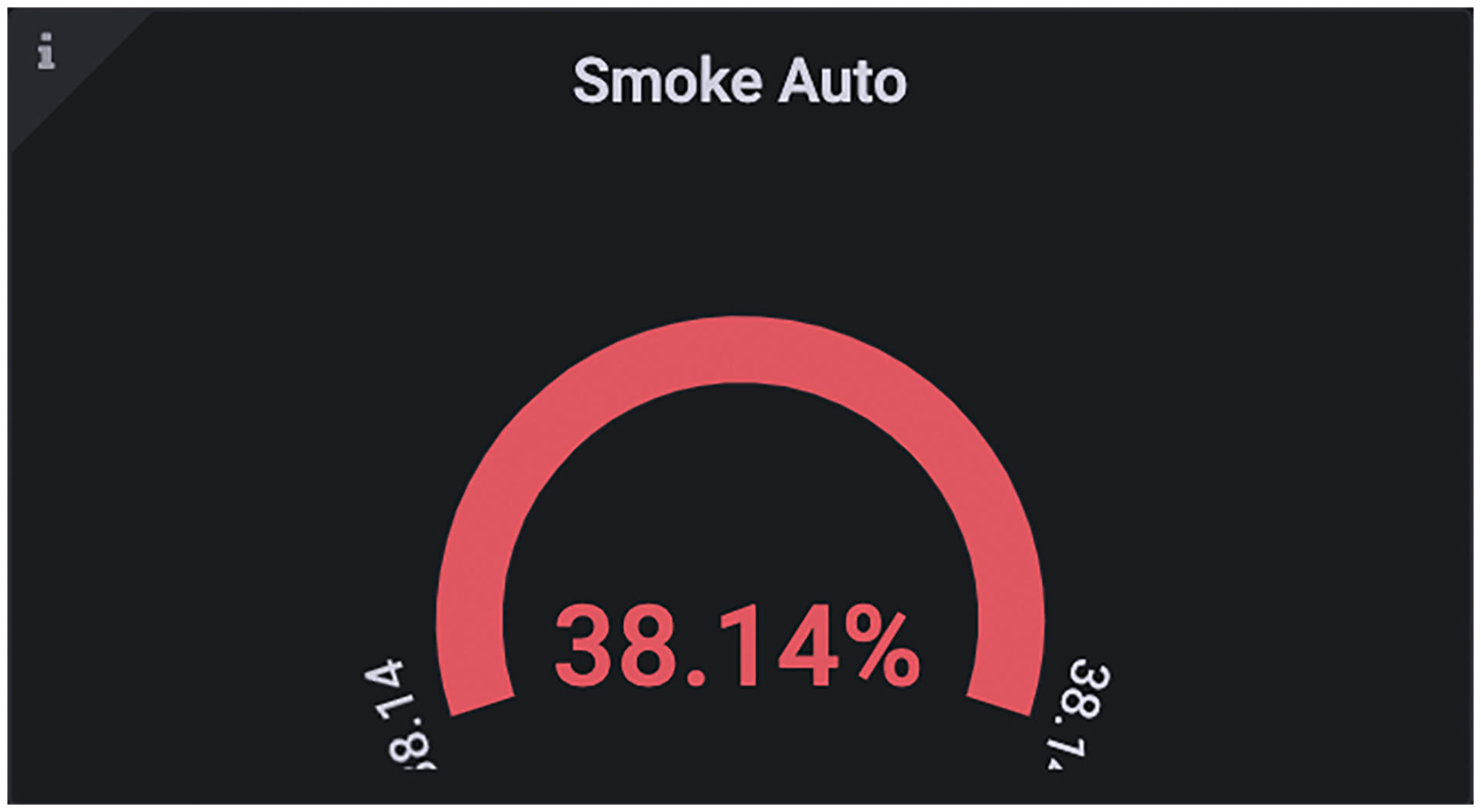
|
|||
|
|
|
|||
|
|
而对标度量是时间轴上的一条折线或柱状图。下面展现的是Bug泄漏率随着时间的变化趋势图:
|
|||
|
|
|
|||
|
|
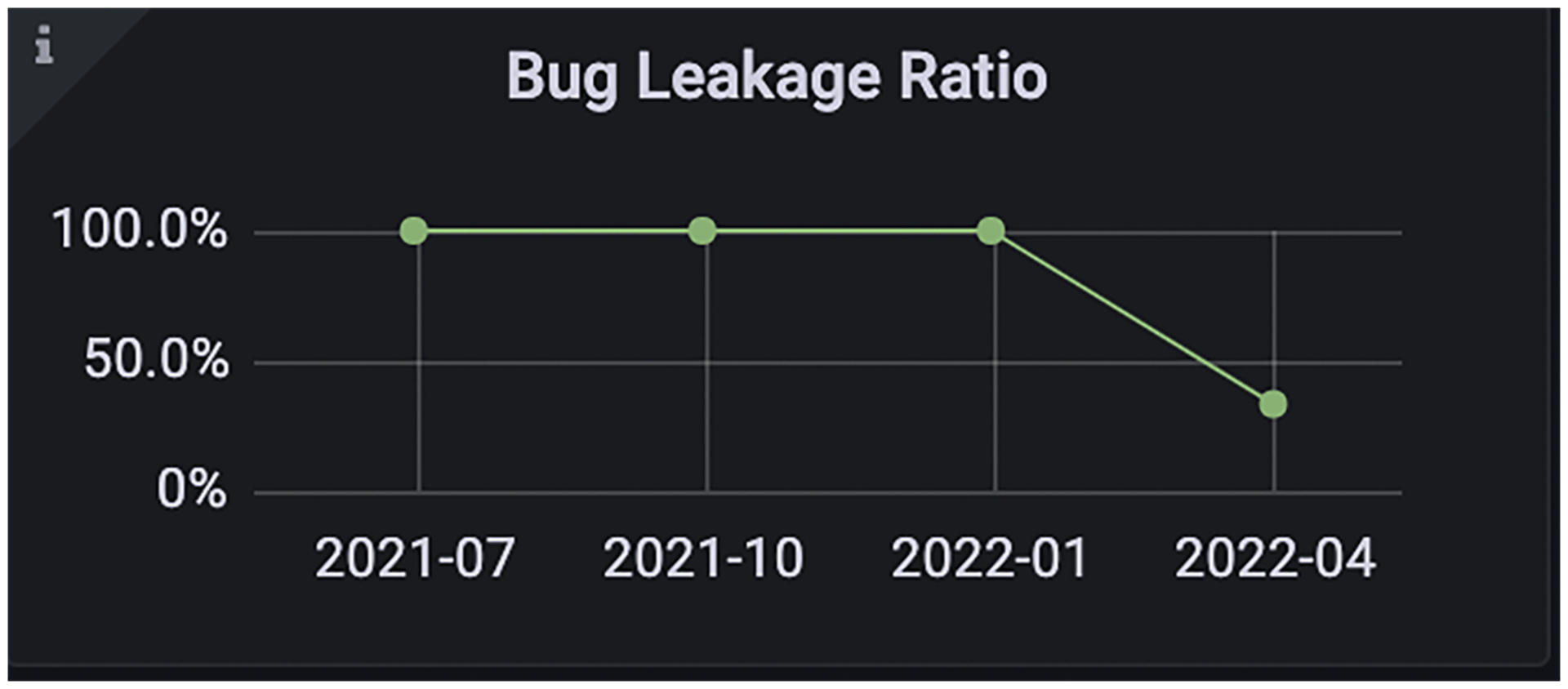
|
|||
|
|
|
|||
|
|
为了比较两个数值的差异,我们也可以把相似的度量放在一张折线图里。
|
|||
|
|
|
|||
|
|
比如下面这张图,展现的是不同归因的Bug数量。Bug的根源有的来自于API,有的来自数据,还有的是需求等等,把它们放在一起对比,有助于你看出软件开发周期的薄弱环节。
|
|||
|
|
|
|||
|
|
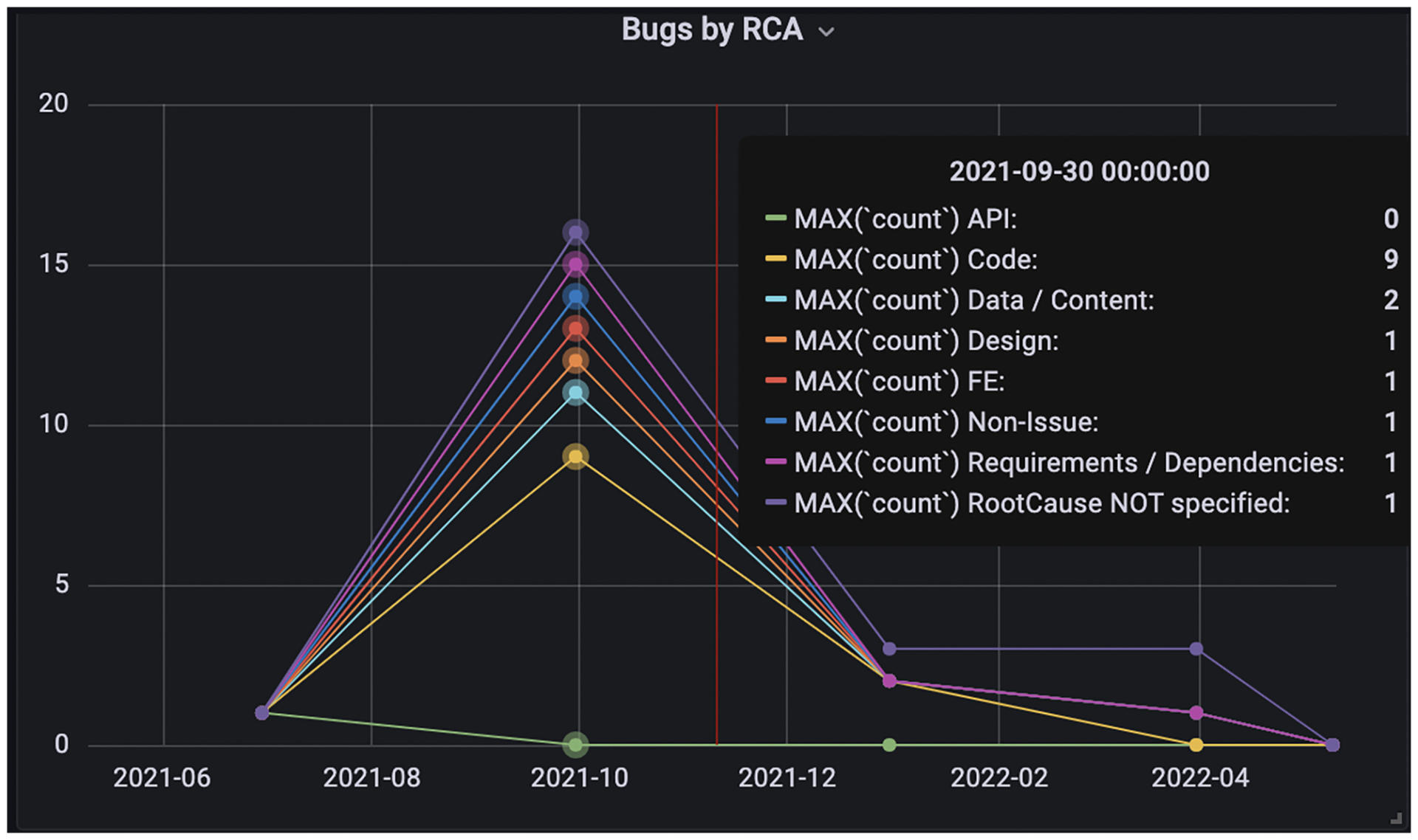
|
|||
|
|
|
|||
|
|
这几类可视化的图片还只是冰山一角。这一讲,我将为你揭秘,这种度量数据可视化的实现相关技术和工作原理是什么。此外,我还会和你分享一下如何在自己的团队里,快速搭建一个度量数据实时观测平台。
|
|||
|
|
|
|||
|
|
## ETLA数据全周期技术
|
|||
|
|
|
|||
|
|
度量的工作无非就是收集、处理和展示数据,所以从本质上说,度量技术就是一个数据工程。
|
|||
|
|
|
|||
|
|
在业界,典型的数据处理过程就是ETL,ETL是怎么来的呢?这就要说到数据生命周期的前三个阶段:分别是提取数据(Extract)、聚合数据(Transform)以及持久化数据(Load)。
|
|||
|
|
|
|||
|
|
三个阶段的英文单词首字母组合起来,就是ETL,ETL完成了业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,用在度量技术里,也就是把分散、零乱、标准不一致的原始数据转换成统一的度量的过程。
|
|||
|
|
|
|||
|
|
但是度量生成后,最终还需要用图表形式实现可视化。所以,我们再给ETL加上一个A,A是Analyze的首字母,而ETLA就是我们今天要学习的**全周期数据度量技术**。
|
|||
|
|
|
|||
|
|
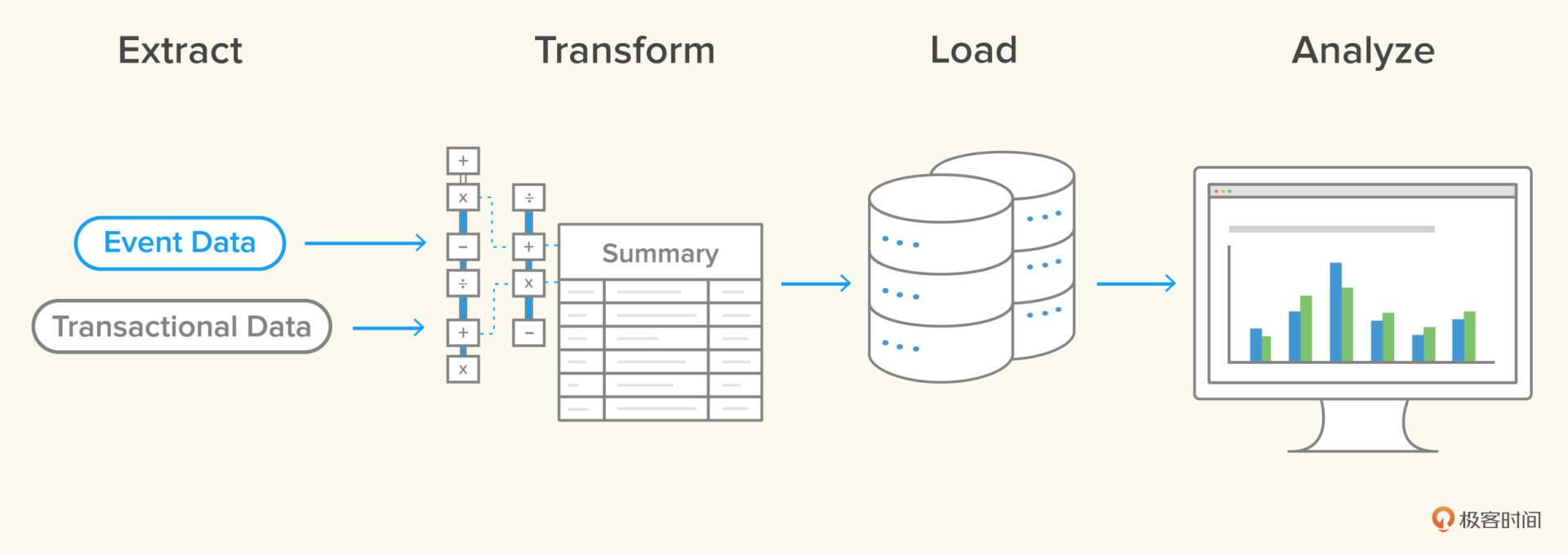
|
|||
|
|
|
|||
|
|
数据生命周期的这四个阶段,每个阶段都有不同的技术工具,下面我们就一一地学习。
|
|||
|
|
|
|||
|
|
### 数据提取(Extract)
|
|||
|
|
|
|||
|
|
Extract是从数据源里提取数据,这个数据源可以是API,也可能是数据库,或者文件系统等等所有能提供数据的地方。
|
|||
|
|
|
|||
|
|
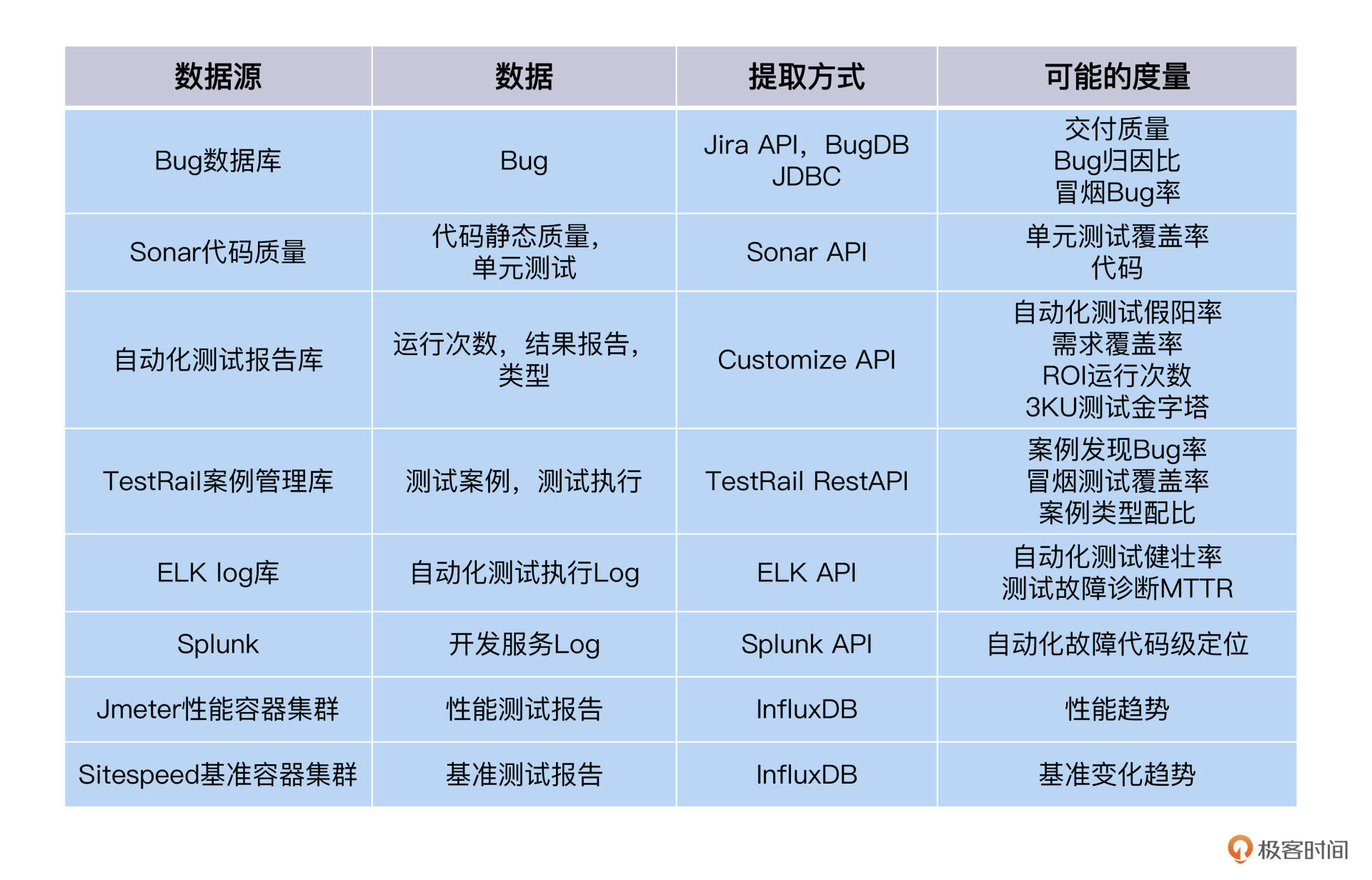
在整个软件生命周期里,从需求到设计,开发,测试再到生产运维,会产生大量的数据,我们来理一下有哪些数据跟软件质量相关的,它们应该怎么提取。
|
|||
|
|
|
|||
|
|
你可以参考我整理的数据源表格,如下所示:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
在Extract环节,我给你分享两条实践原则,它们都来自我的实践经验:
|
|||
|
|
|
|||
|
|
**第一,提取的数据要尽可能得多。**因为在分析阶段,你可能会用到多种数据才能算出一个度量,不要等到用的时候,才想到临时提取。
|
|||
|
|
|
|||
|
|
尤其那些趋势的度量,它们需要一定周期的时间序列数据才能计算出来。比如季度环比Bug增长率,当前是第二季度,不仅需要第二季度的Bug数据,还需要第一季度的Bug数据才能做环比。如果是同比增长率,那就还需要一年前的Bug数据。所以,提前提取好数据,有备无患。
|
|||
|
|
|
|||
|
|
**第二,提取数据的过程不要人工污染。**这个原则在前面已经说过了,人工的污染指的是个人的判断和决策加到数据里去了。比如说,在提取Bug的过程中,有的Bug没有标注发生的环境,你给它们加了一个默认值,都认作是测试环境,这就把Bug数据污染了。
|
|||
|
|
|
|||
|
|
### 数据转换及加载(Transform & Load)
|
|||
|
|
|
|||
|
|
Transform和Load是解决度量数据聚合转换和持久化的问题。这两个环节的技术方案做不做,怎么做,都取决于你的场景需求。别忘了我们贯穿始终的最优ROI思维,要把做“必要”的工作当作目标,不要“过度”工作。
|
|||
|
|
|
|||
|
|
举一个例子,在Extract环节,我们已经把TestRail里的测试案例信息提取出来了,那还需要在Load环节,再设置一个新的数据库来保存它们么?
|
|||
|
|
|
|||
|
|
这时你需要考虑这样做的收益和付出的成本,根据 [CAP原理](https://zh.m.wikipedia.org/zh-hans/CAP%E5%AE%9A%E7%90%86),如果技术方案里出现了分布式数据源,会大大增加系统的复杂度,你就必须在CAP里三选二,不能得三。要么是追求数据一致性,舍弃掉及时可用性,要么是为了及时可用性,你就得忍受数据可能不一致的状态。
|
|||
|
|
|
|||
|
|
所以,针对TestRail案例库,你要慎重考虑。如无必要,无需增加实体,这也符合我们早在[第二讲](https://time.geekbang.org/column/article/497405)就提到过的[奥卡姆剃须刀原则](https://zh.m.wikipedia.org/zh/%E5%A5%A5%E5%8D%A1%E5%A7%86%E5%89%83%E5%88%80)。所以,你可以把测试案例的数据聚合成度量,自动化测试案例百分比,冒烟测试百分比等等,不用Load,直接对接Analyze环节做可视化了。
|
|||
|
|
|
|||
|
|
不过在度量场景里,有一种情况,你不得不考虑增加一个度量数据库。是什么场景呢?
|
|||
|
|
|
|||
|
|
在度量分析里,我们要经常要做两种分析,横向分析和纵向分析。
|
|||
|
|
|
|||
|
|
横向分析是比较不同集合的相似度量数据。比如对两个项目的Bug泄漏率进行对比,这样能够启发我们寻找组织内的最佳实践。纵向分析则是比较同一个度量它的历史数据和当前数据。比如Bug的趋势,自动化测试假阳率的趋势。
|
|||
|
|
|
|||
|
|
我们不难发现,想要实现纵向分析,需要我们先记录时间轴上一个个数据点,最终整合为时间序列数据。
|
|||
|
|
|
|||
|
|
有些原始数据源只会保存最新的数据信息,比如我们获得“Open的Bug”趋势,昨天“Open状态的Bug”是100个,今天可能是120个。
|
|||
|
|
|
|||
|
|
如果昨天没有记录下100这个数字,今天你就无法追溯回去,这种情况,我们就应该把每次采集到的数据以时间序列的格式存进度量数据库里。
|
|||
|
|
|
|||
|
|
度量数据库存储的是时间序列数据,它的Json表达是这样的:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
{
|
|||
|
|
"fleet": "JiraBugs",
|
|||
|
|
"tags": "FoodCome",
|
|||
|
|
"datapoints":
|
|||
|
|
[
|
|||
|
|
{
|
|||
|
|
"Bugs_OPEN": 100
|
|||
|
|
"timestamp": 1466734431563,
|
|||
|
|
},
|
|||
|
|
{
|
|||
|
|
"Bugs_OPEN": 120
|
|||
|
|
"timestamp": 1466734432763,
|
|||
|
|
}
|
|||
|
|
]
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
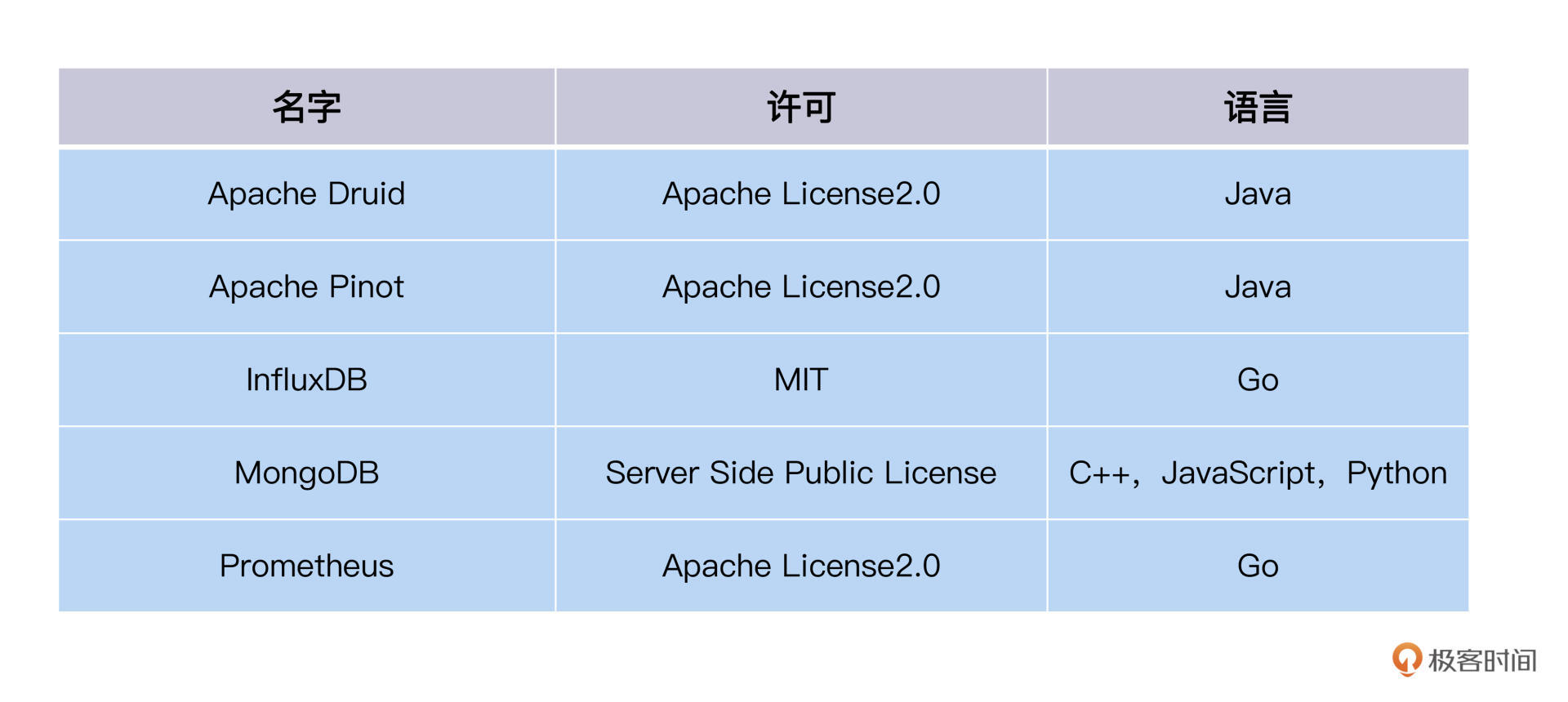
时间序列数据库英文又叫TSDB(Time Series Database), 它是一种非关系数据库,业界主流的有InfluxDB、Graphite、Prometheus、MongoDB等等。你可以参照这个列表来选择TSDB作为自己组织的度量数据库。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
完整列表参考[这里](https://en.wikipedia.org/wiki/Time_series_database)。
|
|||
|
|
|
|||
|
|
### 可视化(Analyze)
|
|||
|
|
|
|||
|
|
做了这么多准备工作,我们现在终于到了最重要的环节,也就是度量数据的可视化。
|
|||
|
|
|
|||
|
|
这个环节可用工具不少。你既可以选择自开发可视化前端,也可以选择现成的工具,主流的工具有Grafana、Kibana、Tableau等等,它们都提供了基本的数据展现功能,像柱图、线图、点图和表格等等。
|
|||
|
|
|
|||
|
|
不过,它们在应用领域上有一些微小区别,Grafana有免费版,在DevOps领域有经验优势。像Amazon的内部服务监控Telemetry,Oracle Public Cloud的度量服务T2都是用Grafana作为可视前端的。而Tableau是商业版,在Business Inteligence上更为擅长。
|
|||
|
|
|
|||
|
|
对测试度量可视化需求来说,要展现数字度量表盘、线图、柱图等等,不管是Tableau、Kibana还是Grafana,都能胜任。其中Grafana具有轻量开源的特点,我们就看一下Grafana怎么实现数据可视化。
|
|||
|
|
|
|||
|
|
Grafana用Docker启动很简单,执行下面命令:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
docker run -d -p 3000:3000 --name=grafana -v /home/ec2-user/data/grafana:/var/lib/grafana -v /home/ec2-user/data/conf:/usr/share/grafana/conf grafana/grafana
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
访问本机的3000端口,你就会看到Grafana的Home页面了。下面是演示图:
|
|||
|
|
|
|||
|
|
|
|||
|
|
Grafana是一个Web UI前端,自带了一个Sqlite小数据库。不过Sqllite不是存储度量数据的,而是用来放Grafana的访问账号和其它配置信息的。
|
|||
|
|
|
|||
|
|
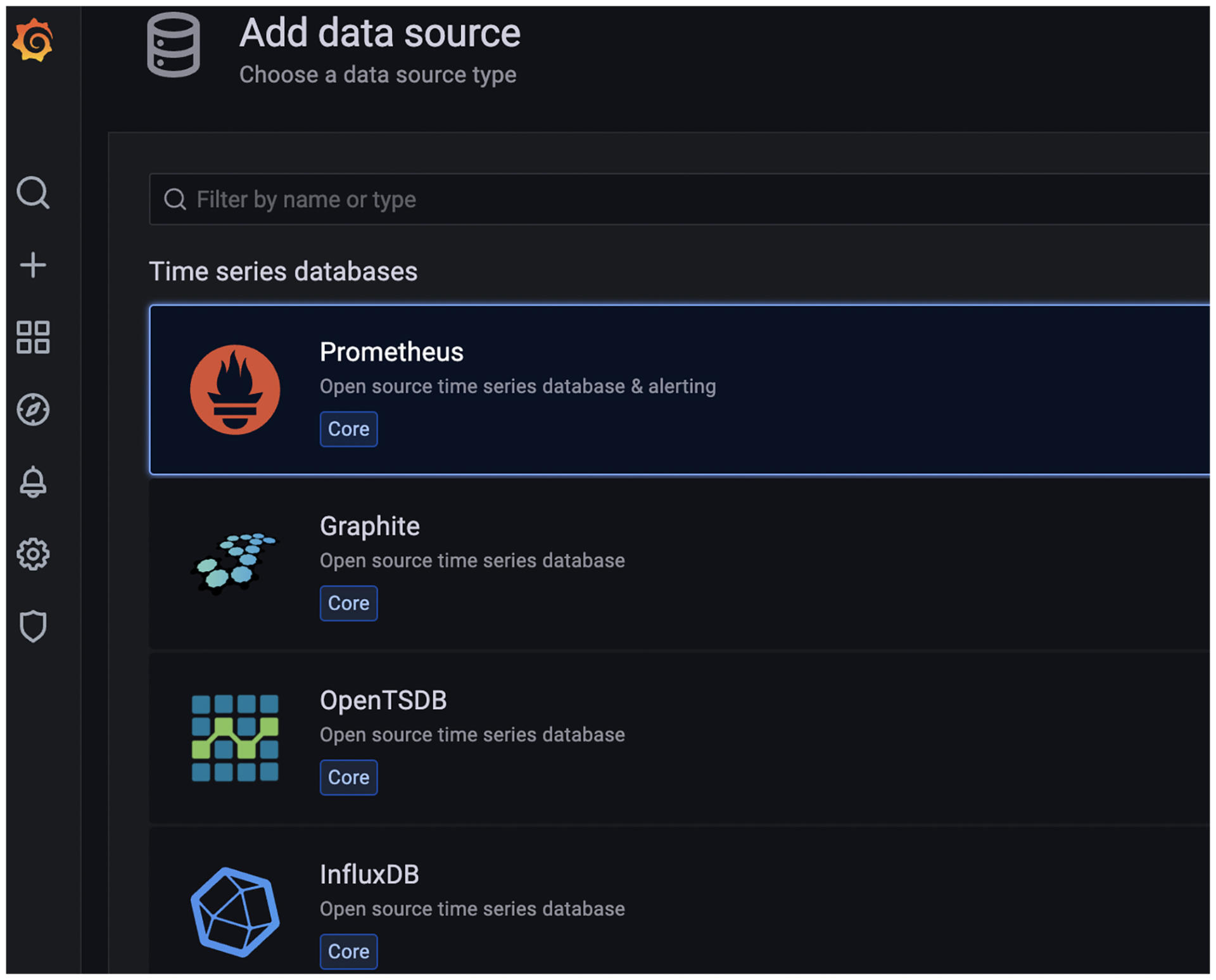
那Grafana的度量数据源从哪里来呢?我们可以在数据源配置中心里,看看Grafana支持哪些数据源。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
这有一个数据源的列表,我们可以看到Grafana支持的数据源类型,有时间序列数据库Graphite、InlfuxDB等等,也有基于Log文件的数据源ElasticSearch等,还有关系型数据库MySQL、PostgresSQL、MS SQL Server,Cloud数据源Cloud Watch、S3等等。你可以看看[这个链接](https://grafana.com/docs/grafana/latest/datasources)。
|
|||
|
|
|
|||
|
|
有了数据源后,下一步就是把度量数据展现在Grafana上了。
|
|||
|
|
|
|||
|
|
在Grafana的世界里,一个度量会通过一个Panel来完成可视化。所以,Panel的定义要包含两个信息:度量的数据来自哪里,以及度量以什么方式展现。
|
|||
|
|
|
|||
|
|
我们沿用上面的JiraBugs做例子。在Panel的Query Setting里,我们可以设置查询SQL,来告诉Grafana数据怎么取,设置参数如下所示:
|
|||
|
|
|
|||
|
|
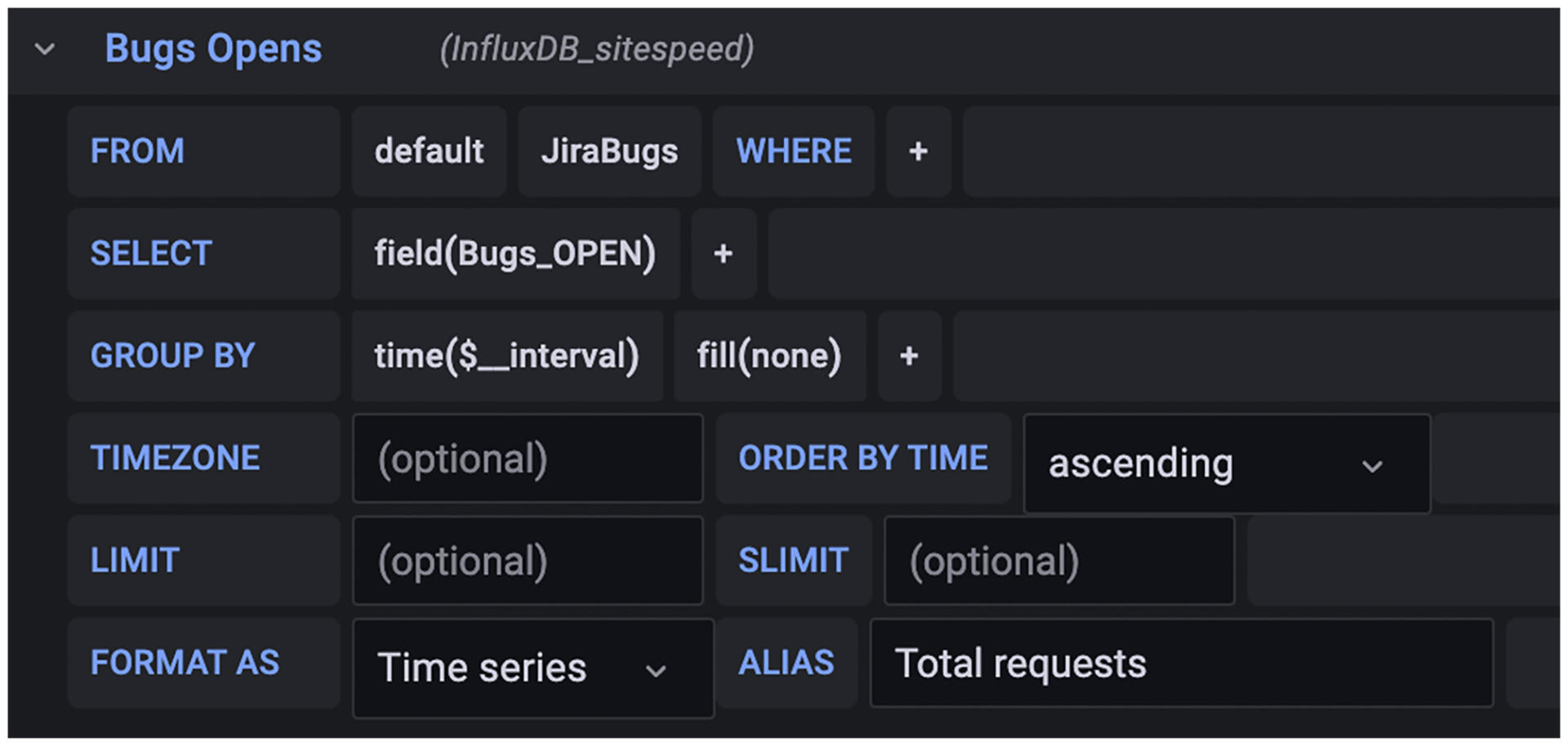
|
|||
|
|
|
|||
|
|
这样设置之后,存在InfluxDB里的JiraBugs的数据点就会被拉出来。因为每个Bugs\_OPEN数据点都会有一个时间戳,所以上面的SQL会查出这样一个数据集,如下所示:
|
|||
|
|
|
|||
|
|
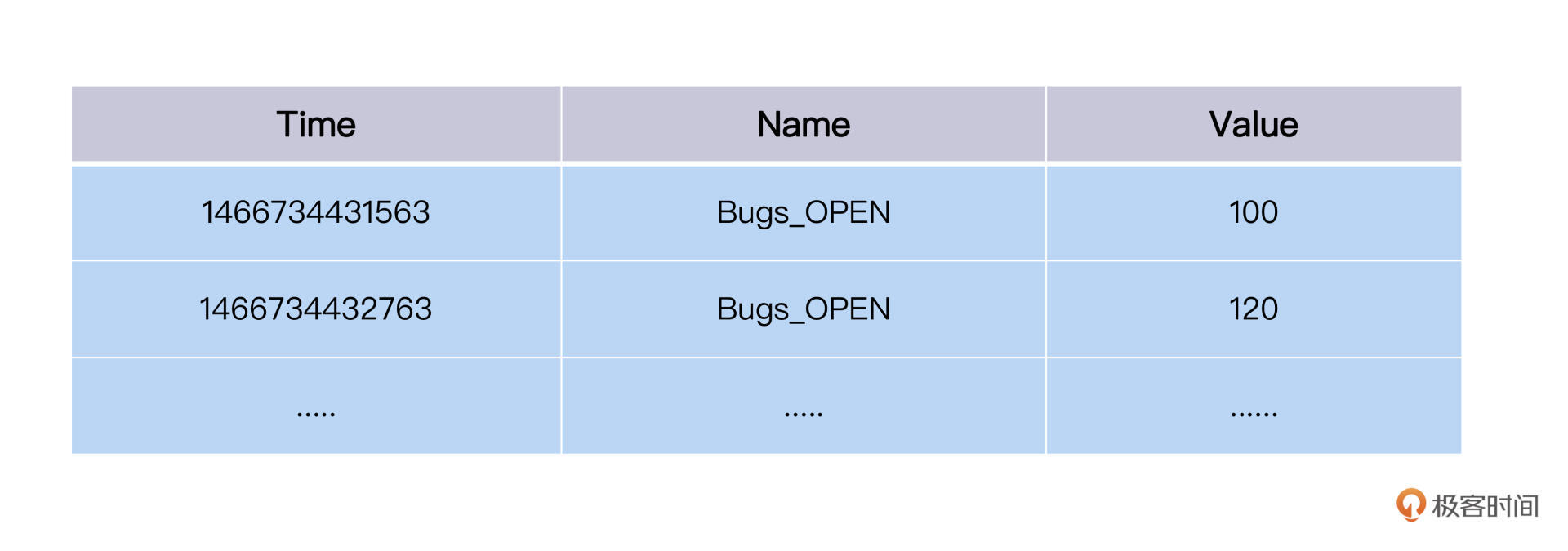
|
|||
|
|
|
|||
|
|
这些时间序列的数据该怎么展现呢?我们只需在Grafana的Visualization下拉列表里,选择展现的样式:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
这时,我们设定Panel的展现形式为Time Series折线图,Grafana就会把上面的时间序列数据画成一条折线图:
|
|||
|
|
|
|||
|
|
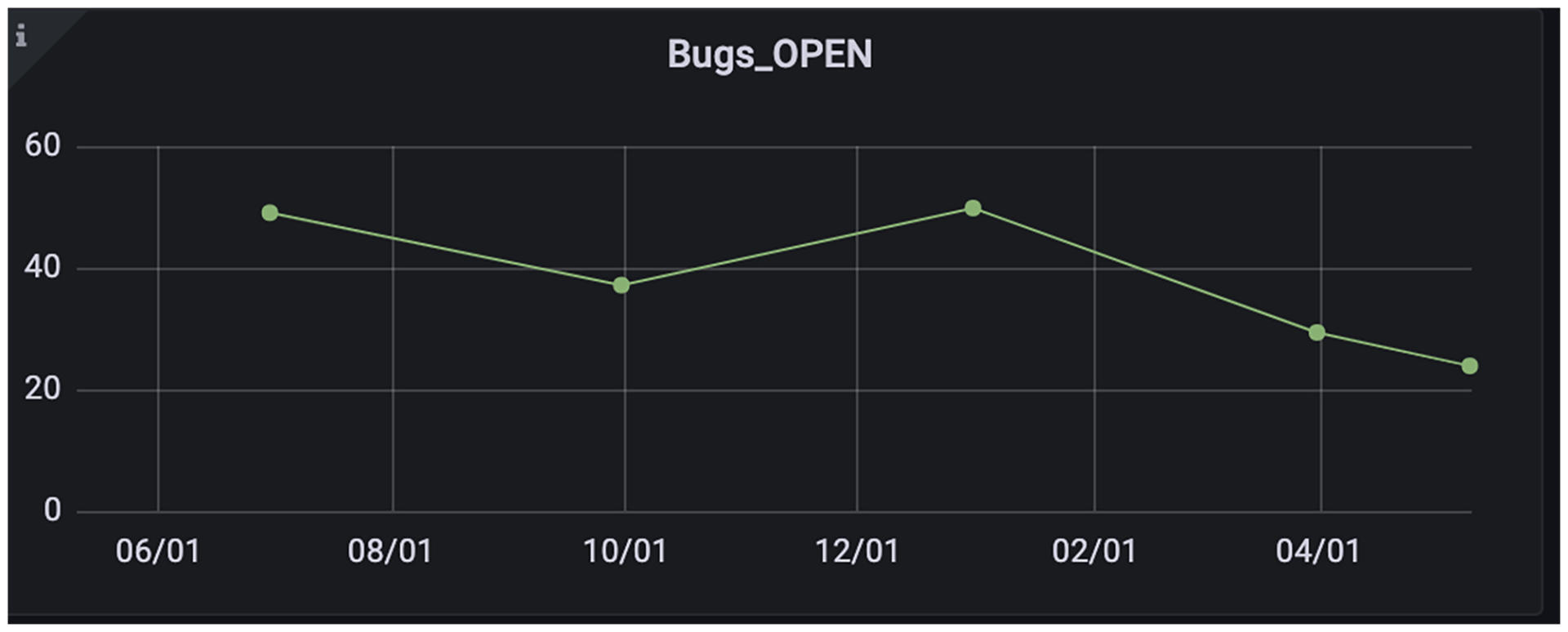
|
|||
|
|
|
|||
|
|
如果我们更换Panel的展现形式是Table,Grafana就会为我们画出一张表格:
|
|||
|
|
|
|||
|
|
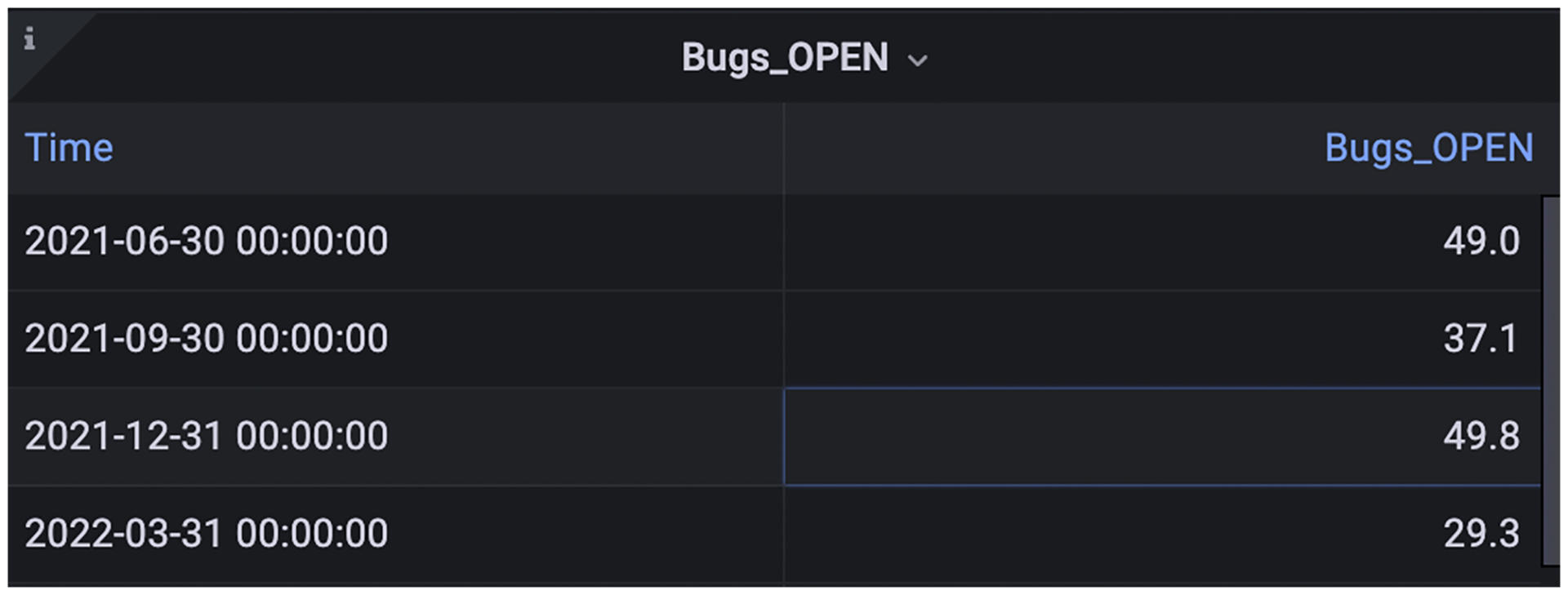
|
|||
|
|
|
|||
|
|
到现在,相信你能体验到Grafana的强大功能了!
|
|||
|
|
|
|||
|
|
你只需准备好度量数据源,这个数据源可以是数据库,文件系统,API,云端数据,然后告诉Grafana这个数据源在哪里。Grafana会把它的时间序列数据拉出来,并根据你的定制,展现成各种格式的图表,这就完成了数据可视化。
|
|||
|
|
|
|||
|
|
而且,Grafana还内嵌了一些数据聚合函数,像Sum、Mean等运算。如果你想查看一个测试工程师平均每天处理多少个Bug,你可以把Bug先Sum在一起,再求Mean,这些计算都在Grafana侧前端完成的,而不需要更改度量数据库。
|
|||
|
|
|
|||
|
|
因此,你可以这样理解:**Grafana也做了一部分ETLA的Transform工作**。
|
|||
|
|
|
|||
|
|
学会了一个Panel的制作以后,你就可以如法炮制,制作多个Panel,放在一个Dashboard里。Dashboard是一个度量集合,用来反映一个组织或者一个项目的关注的所有度量。
|
|||
|
|
|
|||
|
|
比如,下面的Dashbaord反映了一个敏捷开发的Squad小组的活动状态,包括开发代码质量,自动化测试覆盖率,执行效率等等:
|
|||
|
|
|
|||
|
|
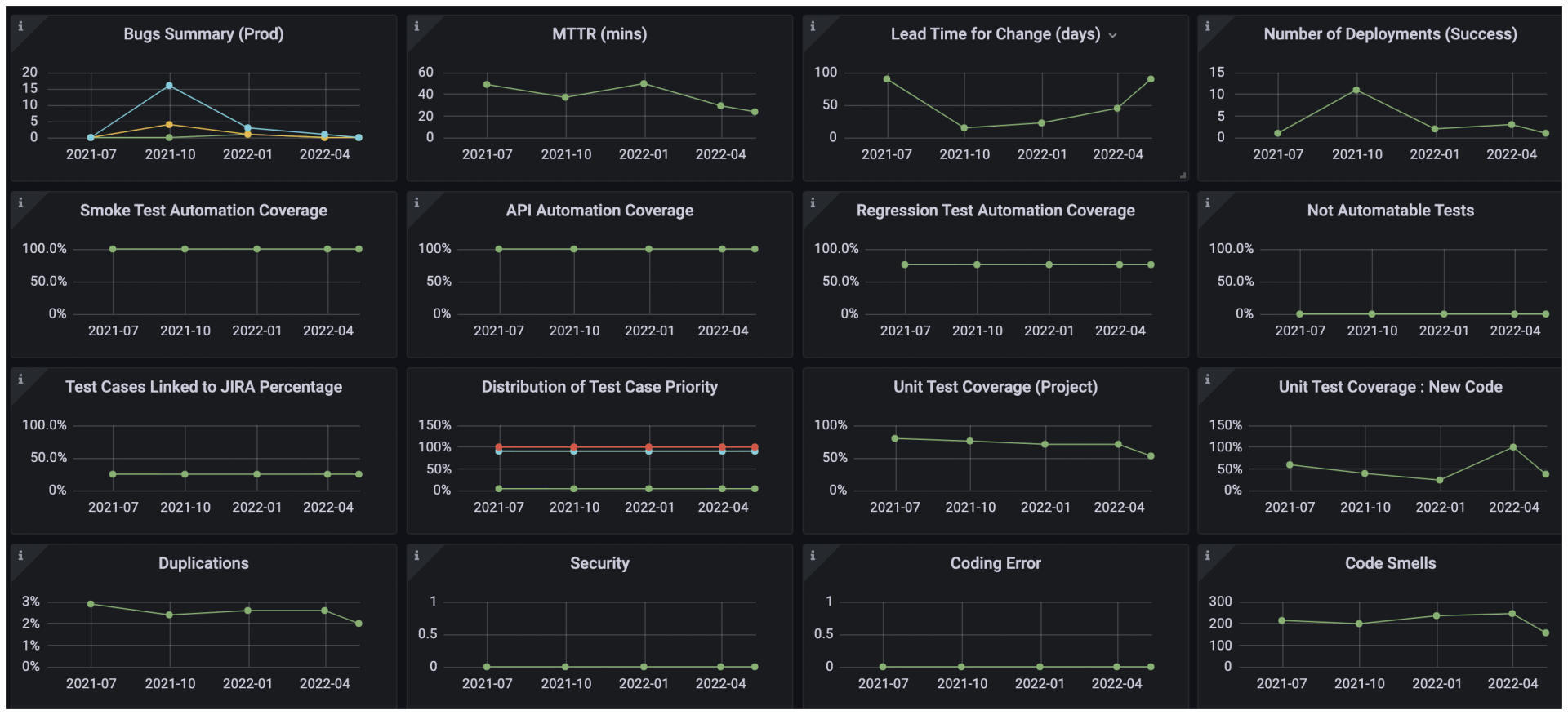
|
|||
|
|
|
|||
|
|
上图的度量集合有的来自Bug数据库,有的来自静态代码扫描结果,还有来自Ops工具等等不同数据。通过这样一个Dashboard,能把这些度量组织在一起,你就能对这个项目的质量状态一目了然了!
|
|||
|
|
|
|||
|
|
能观测,我们还不满足,我们还要能够设定目标,用于发现短板,驱动优化和提升。这块怎么实现呢?
|
|||
|
|
|
|||
|
|
利用Grafana的告警功能,我们就能给度量设置阈值。比如我们设置好,当Bug泄漏率超过了20%,就需要告诉团队,需要采取行动了。
|
|||
|
|
|
|||
|
|
这个“告诉”的方式,可以是发一封邮件,也可以直接提交一个工单,结合你的团队习惯,使用团队成员都习惯的工作跟踪系统即可。详细使用方法,你可以参照Grafana Alerts[文档链接](https://grafana.com/docs/grafana/latest/alerting)。
|
|||
|
|
|
|||
|
|
## 自动化测试报告展现
|
|||
|
|
|
|||
|
|
上面我们学习了数据可视化的整个技术链条。只要有数据点和时间戳信息,就可以把它们放到度量数据库里,让Grafana生成各种各样的图表。
|
|||
|
|
|
|||
|
|
这种数据可视化方案跟传统的报告相比,有巨大的优势。第一,高度可定制化,图表的展现形式多种多样,聚合的函数也丰富。第二,动态观测,每次刷新Dashboard,都会获得新的数据,图表也会随之更新。
|
|||
|
|
|
|||
|
|
在我看来,自动化测试报告未来的样子就应该接近于这种数据可视化方案,在[第二十四讲](https://time.geekbang.org/column/article/517969)我曾经说过,传统自动化测试报告数据和格式都很固定,展示样式死板,自开发成本又高。
|
|||
|
|
|
|||
|
|
这里推荐你考虑把Grafana作为自动化测试报告的展现前端。这样一来,作为自动化测试开发人员,我们只需要关注数据,画图做表的工作都可以交给Grafana。
|
|||
|
|
|
|||
|
|
这个逻辑上是可行的。因为自动化测试会反复运行多次,每运行一次,就相当产生一个时间序列上的时间点。只不过,这个时间点对应的数据并不是一个简单的数据点,而是一个Json树形对象结构,包含了本次测试运行产生所有的结果数据。
|
|||
|
|
|
|||
|
|
逻辑上可行,实践中有没有落地呢?Jmeter的性能测试就可以用Grafana+influxDB+Jmeter的Docker容器编排,一站式完成。
|
|||
|
|
|
|||
|
|
实现思路是这样的:
|
|||
|
|
|
|||
|
|
1.Jmeter在BackendListener添加InfluxDBBackendListener,把结果数据传送给它;
|
|||
|
|
|
|||
|
|
2.InfluxDBBackendListener把数据写入InfluxDB实例;
|
|||
|
|
|
|||
|
|
3.Grafana连接InfluxDB,使用封装好的Dashboard模版来展现性能测试报告。
|
|||
|
|
|
|||
|
|
整个过程,不需要写任何代码,只要运行Jmeter,就可以在Grafana上看报告了!我给你准备了一个[GitHub](https://github.com/testsmith-io/jmeter-influxdb-grafana-docker)的链接,你可以看到docker-compose.yaml和Jmeter的运行脚本。
|
|||
|
|
|
|||
|
|
最后在Grafana上展现的性能测试报告如下:
|
|||
|
|
|
|||
|
|
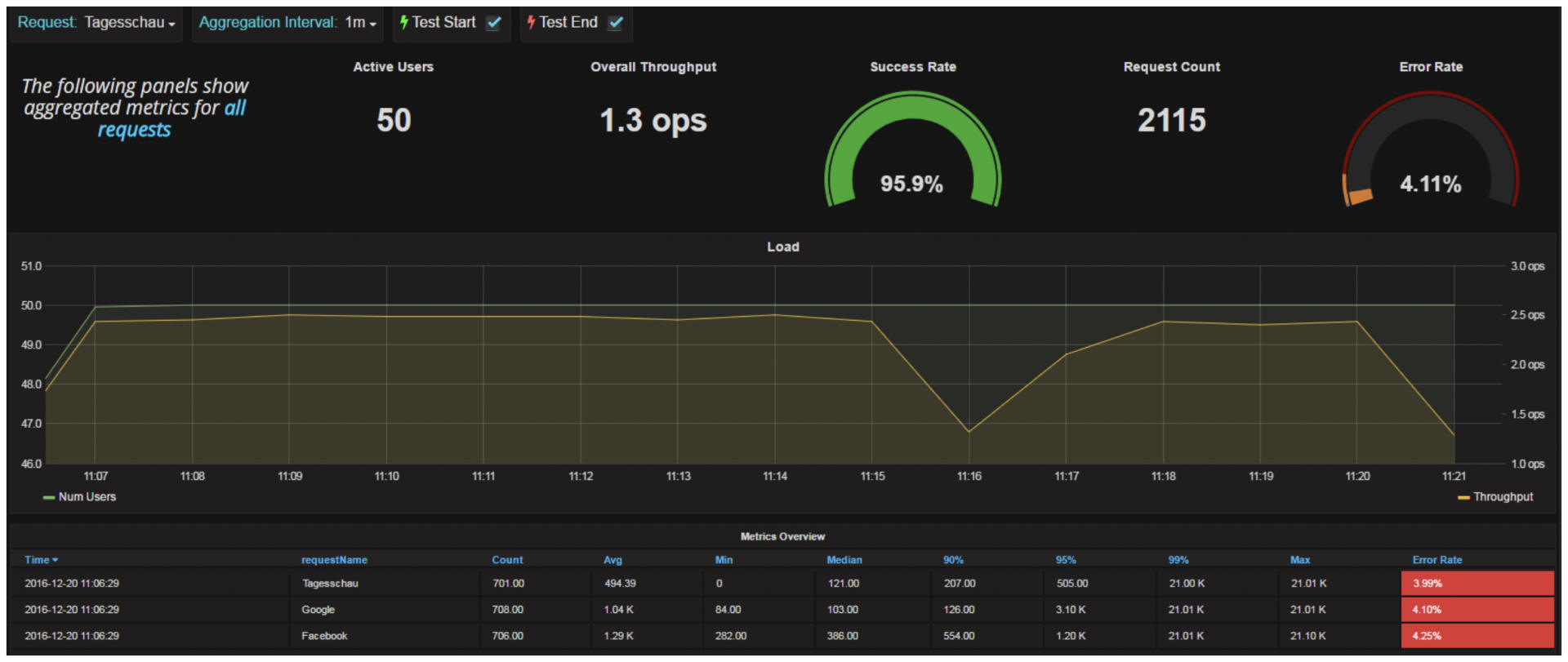
|
|||
|
|
|
|||
|
|
那么剩下的问题是,我们UI自动化测试报告,API自动化测试报告,是不是也可以做成这样的Grafana Dashboard呢?是否可以做,可以的话要如何做,我把这个问题留给你思考一下。
|
|||
|
|
|
|||
|
|
## 小结
|
|||
|
|
|
|||
|
|
在这一讲,我们学习了度量技术平台的实现思路。在前端,技术平台展现的是度量图表,但背后是整个ETLA的工作流,这个工作流其实也是数据的流动:从数据的提取Extract,到数据的聚合Transform,数据的持久化Load,最后到数据可视化Analyze。
|
|||
|
|
|
|||
|
|
在数据生命周期ETLA的每个阶段都有相应的工具和技术,这一讲我给你分享了一个ETLA的落地技术方案。
|
|||
|
|
|
|||
|
|
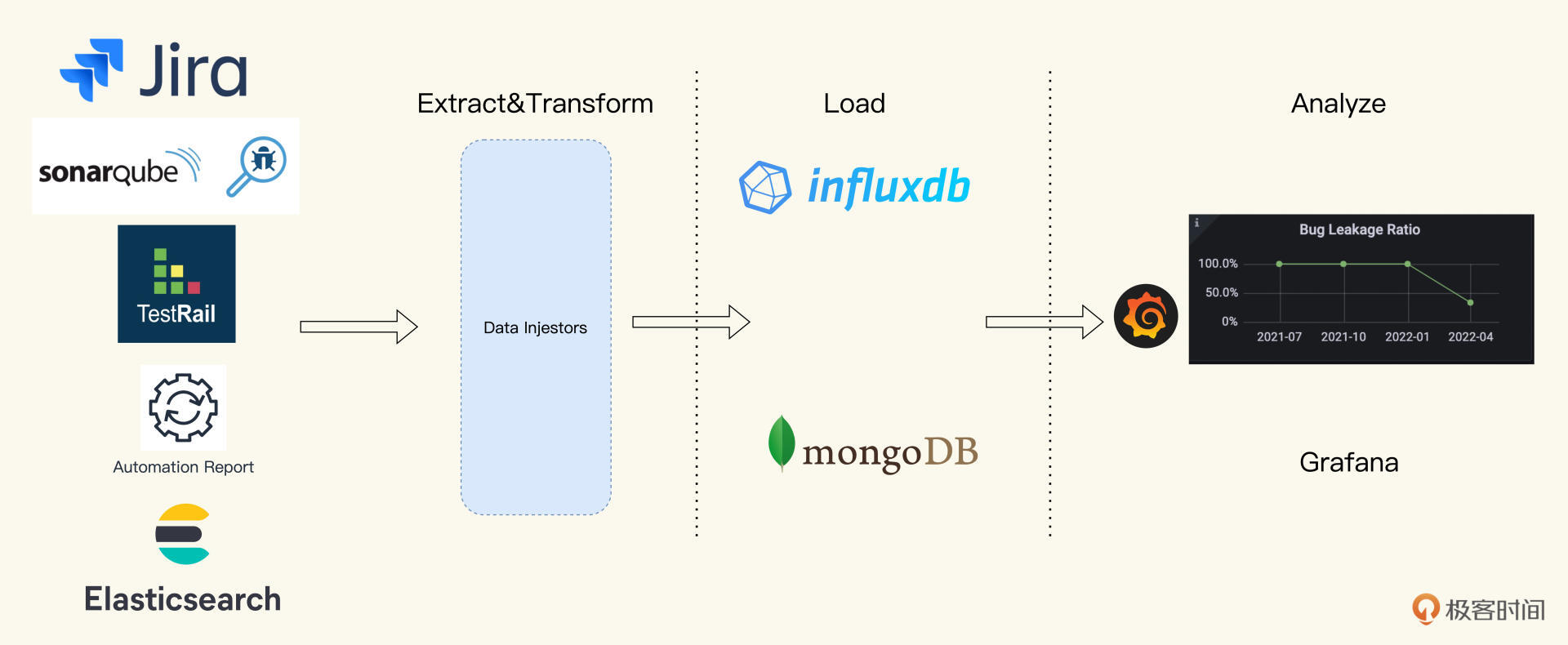
|
|||
|
|
|
|||
|
|
在Extract环节,我给你准备了一个数据源列表,这些数据源是你将来展现质量度量的原始素材。你需要开发Data Injgestor去从这些数据源里拉取数据并转换成度量,存放到Load度量数据库里,或者直接连接Analyze。
|
|||
|
|
|
|||
|
|
在Load环节里,我们需要选择合适的持久化数据源,因为度量要有结构多样,历史对比的能力,所以这里推荐的是非关系型数据库MongoDB,时间序列数据库Influxdb等。
|
|||
|
|
|
|||
|
|
你也可以结合项目需求,采用其它类型的数据库,我就曾经用过MySQL来存储一些变更频繁的度量数据,比如Bug。
|
|||
|
|
|
|||
|
|
在数据可视化这个环节,我重点给你讲解了Grafana这个工具。它免费且功能强大,一个Dashboard上可以展现多个Panel,每个Panel对应一个度量。这样,你的团队就能在一个Dashboard里看到全面的质量数据。发现质量短板后,还可以通过设置度量阈值的方式,给团队设定提升目标,完成整个数据驱动的循环。
|
|||
|
|
|
|||
|
|
在度量数据可视化的实现过程中,我们也发现Grafana的数据可视化能力,同样可以用在自动化测试报告的展现中。
|
|||
|
|
|
|||
|
|
这里我用了一个Jmeter性能测试报告的例子,使用 **Docker容器Jmeter+InfluxDB+Grafana** 做到了运行测试、保存结果数据、展现报告的一站式解决方案。非常方便,你也可以动手试试看。
|
|||
|
|
|
|||
|
|
你还停留在HTML的自动化测试报告么,来试试Grafana强大的报表能力吧。
|
|||
|
|
|
|||
|
|
## 思考题
|
|||
|
|
|
|||
|
|
根据这一讲学到的内容,请你思考一下,你工作里的UI自动化测试报告、API自动化测试报告是不是也可以做成Grafana Dashboard呢?
|
|||
|
|
|
|||
|
|
欢迎你在留言区跟我交流互动。如果觉得今天讲的方法对你有帮助,也推荐你分享给更多朋友、同事。
|
|||
|
|
|