304 lines
21 KiB
Markdown
304 lines
21 KiB
Markdown
|
|
# 24|启动运行:基于Job模型的框架实现和运行
|
|||
|
|
|
|||
|
|
你好,我是柳胜。
|
|||
|
|
|
|||
|
|
今天是设计篇的最后一讲,从第十七讲到现在,我们围绕Job元数据模型讲了很多内容。毕竟,这个Job模型设计,是一个新的设计方法论,需要从模型推演、设计方法、不同场景的设计案例等各个方面来学习理解。虽然过程中有点像盲人摸象一样,但我们最后终于勾勒出了一个全面的理解。
|
|||
|
|
|
|||
|
|
不过,一种新的设计方法想要生根发芽,不光要在理论层面讲得通,还要让使用者轻松快速地掌握它,并且学以致用。沿着这个思路,今天我们把基于Job模型的框架实现梳理一遍,明确都需要实现什么,以及怎么实现。
|
|||
|
|
|
|||
|
|
经历了这个思考过程,对你把Job模型在团队里推广和使用大有帮助,而且对你去设计、推广自己的框架也同样适用。一个设计方法要在工作里落地,它就必须要和日常的设计活动,开发维护活动结合在一起,有3个关键场景:
|
|||
|
|
|
|||
|
|
1.自动化测试设计的评审和交流(设计文档化);
|
|||
|
|
2.自动化测试设计和实现的一致性维护(设计代码化);
|
|||
|
|
3.自动化测试的报告呈现(结果可视化)。
|
|||
|
|
|
|||
|
|
## Job设计文档化
|
|||
|
|
|
|||
|
|
我们先从设计评审和交流说起,这离不开一份清晰易读的设计文档。在软件技术迅猛发展的今天,开发人员可以用Swagger来表达API的接口设计,运维人员可以用YAML来表达部署的方案,但**测试人员却没有一个表达自动化设计的文档格式,真是遗憾**。
|
|||
|
|
|
|||
|
|
而现在,有了Job模型后,作为自动化测试人员,你可以骄傲地说,我的自动化测试也有设计文档!
|
|||
|
|
|
|||
|
|
文档化怎么做呢?在前面几讲的案例中,我们都是用画六边形的方法来表达Job树的设计。这种方法有点像画思维导图,一边想,一边展开,帮助你迅速完成设计。但设计是最终要输出成文档的,尤其我们要版本化管理设计文档的时候。
|
|||
|
|
|
|||
|
|
这个设计文档用什么格式比较好呢?我们需要把Job树图转成可读的数据文件,Job树是一个树形结构,那我们继续思考,树形结构适合用什么格式来表达?业界里的树形结构数据表达格式已经非常多了,XML、Json、YAML都能胜任。
|
|||
|
|
|
|||
|
|
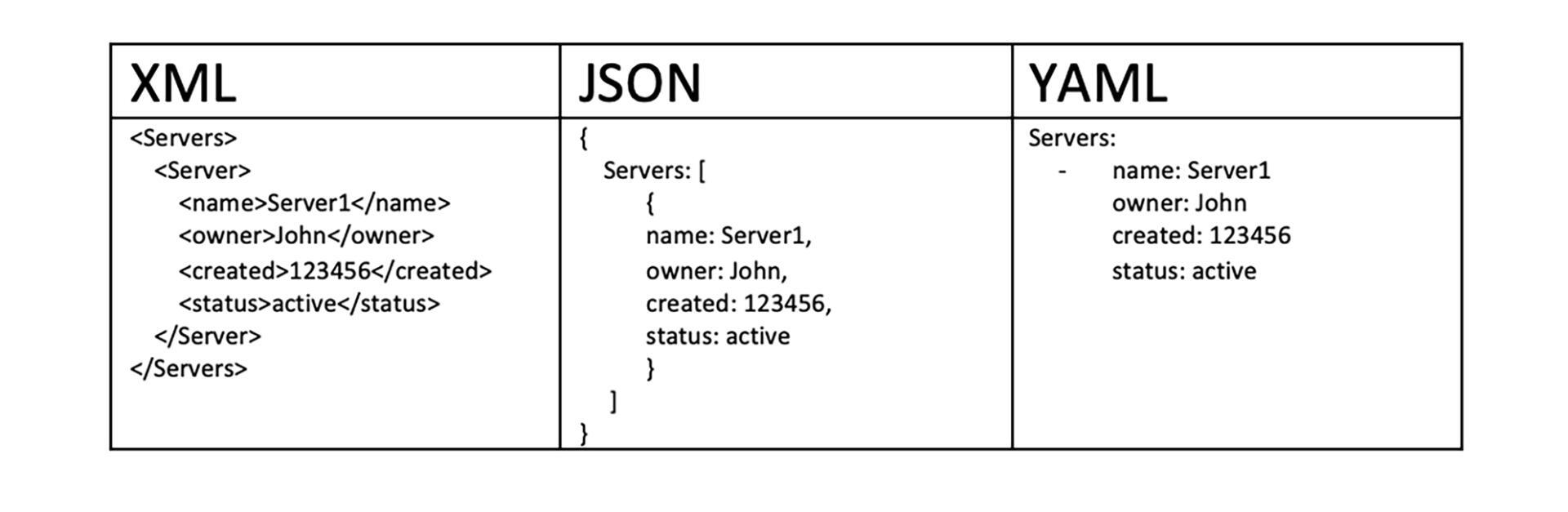
|
|||
|
|
|
|||
|
|
用XML作为载体,展现视频会议(视频会议案例可以回顾[第二十三讲](https://time.geekbang.org/column/article/517078))的Job设计树,也就是TestJobFile.xml的例子如下:
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<TestJob name="VideoMeeting" description="Meeting Full automation">
|
|||
|
|
<TestJob name="ScheduleMeeting">
|
|||
|
|
<TestJob name="createMeeting" host="10.0.0.1" driver="Selenium">
|
|||
|
|
<JobOutput name="MEETING_URL"/>
|
|||
|
|
</TestJob>
|
|||
|
|
<TestJob name="JoinMeetingDesktop" host="10.0.0.2" depends="createMeeting" driver="WinappDriver">
|
|||
|
|
<JobInput name="MEETING_URL"/>
|
|||
|
|
</TestJob>
|
|||
|
|
<TestJob name="JoinMeetingAnroid" host="10.0.0.3" depends="createMeeting" driver="appium">
|
|||
|
|
<JobInput name="MEETING_URL"/>
|
|||
|
|
</TestJob>
|
|||
|
|
</TestJob>
|
|||
|
|
<TestJob name="VerifyJoin" depends="ScheduleMeeting" driver="Restassure">
|
|||
|
|
</TestJob>
|
|||
|
|
<TestJob name="PresentMeeting">
|
|||
|
|
<TestJob name="presentPPT" host="10.0.0.1" driver="Selenium">
|
|||
|
|
<JobOutput name="TR_START_TimeBetweenPresentAndView"/>
|
|||
|
|
</TestJob>
|
|||
|
|
<TestJob name="viewPPT" host="10.0.0.2" driver="WinappDriver">
|
|||
|
|
<JobOutput name="TR_END_TimeBetweenPresentAndView"/>
|
|||
|
|
</TestJob>
|
|||
|
|
<TestJob name="viewPPT" hot="10.0.0.3" driver="appium">
|
|||
|
|
<JobOutput name="TR_END_TimeBetweenPresentAndView"/>
|
|||
|
|
</TestJob>
|
|||
|
|
</TestJob>
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
当然,你用YAML和Json也可以达到同样的表达效果。
|
|||
|
|
|
|||
|
|
有了设计文档后,自动化测试设计就有了自己的表达方式。这就像你和别人聊天的时候,都在说流行的名词“DevOps”,但有人认为DevOps是CICD,有人认为Devops是微服务架构,你甚至无法确定你们讨论的是同一件事。
|
|||
|
|
|
|||
|
|
这个时候怎么办?你需要定义一个内容的骨架,从三个方面:人员组织、流程、技术栈来谈论DevOps。这样,团队的表达方式统一了,交流就会高效了。
|
|||
|
|
|
|||
|
|
所以,能让一份设计文档被不同的人理解,还需要有一致的格式规范。这个格式规范的目的是**让所有人都用同样的关键词**,比如Input、Output、TestData等,都遵守同样的约束,比如同级依赖,实例对抽象的实现等等。
|
|||
|
|
|
|||
|
|
怎么来验证这些格式规范? 你可能已经想到了,XML和YAML用schema验证,Json用JsonValidator来验证。
|
|||
|
|
|
|||
|
|
下面我们结合例子来看看,如何用一个TestJobSchema.xsd文件,来验证TestJobFile.xml是否遵循了关键词使用规范。
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<?xml version="1.0" encoding="UTF-8"?>
|
|||
|
|
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
|
|||
|
|
targetNamespace="http://www.example.com/jobSchema"
|
|||
|
|
xmlns="http://www.example.com/jobSchema"
|
|||
|
|
elementFormDefault="qualified">
|
|||
|
|
<xsd:element name="TestJob">
|
|||
|
|
<xsd:complexType>
|
|||
|
|
<xsd:choice minOccurs="0" maxOccurs="unbounded">
|
|||
|
|
<xsd:element name="TestJob" type="TestJobType" minOccurs="1" maxOccurs="unbounded"/>
|
|||
|
|
<xsd:group ref="TestJobGeneralElements"/>
|
|||
|
|
<xsd:group ref="TestJobElementsGroup"/>
|
|||
|
|
</xsd:choice>
|
|||
|
|
<xsd:attributeGroup ref="TestJobGeneralAttributes"/>
|
|||
|
|
</xsd:complexType>
|
|||
|
|
</xsd:element>
|
|||
|
|
<xsd:attributeGroup name="TestJobGeneralAttributes">
|
|||
|
|
<xsd:attribute name="name" type="xsd:string" use="required"/>
|
|||
|
|
<xsd:attribute name="description" type="xsd:string" use="required"/>
|
|||
|
|
<xsd:attribute name="depends" type="xsd:string" use="optional"/>
|
|||
|
|
<xsd:attribute name="host" type="xsd:string" use="optional"/>
|
|||
|
|
<xsd:attribute name="timeout" type="xsd:nonNegativeInteger" use="optional"/>
|
|||
|
|
</xsd:attributeGroup>
|
|||
|
|
<xsd:group name="TestJobGeneralElements">
|
|||
|
|
<xsd:sequence>
|
|||
|
|
<xsd:element name="JobInput" type="JobInputType" minOccurs="0" maxOccurs="unbounded"/>
|
|||
|
|
<xsd:element name="JobOutput" type="JobOutputType" minOccurs="0" maxOccurs="unbounded"/>
|
|||
|
|
<xsd:element name="TestData" type="TestDataType" minOccurs="0" maxOccurs="unbounded"/>
|
|||
|
|
</xsd:sequence>
|
|||
|
|
</xsd:group>
|
|||
|
|
</xsd:schema>
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
有了Schema文件后,就能保证不同的人设计出来的Job都遵循同样的规范。然后,就可以在团队里开展设计评审、版本升级维护等等自动化测试设计相关的活动了。这样,自动化测试设计就在团队激活了!
|
|||
|
|
|
|||
|
|
## Job设计代码化
|
|||
|
|
|
|||
|
|
按照软件生命周期,设计完成后,工作重心就需要转移到开发阶段了。传统开发模式里,这个过程一般是手工的,在设计阶段设计好多少个模块,每个模块的出入口是什么,再交由开发人员根据设计文档来实现代码。
|
|||
|
|
|
|||
|
|
这种模式在软件迭代初期是奏效的,因为设计和代码是一致的。但随着时间推移,迭代次数增加,不断修改bug,团队成员也换了几波后,代码和设计就会产生越来越大的偏差,这就是我们常说的“**架构腐化**”问题。
|
|||
|
|
|
|||
|
|
自动化测试开发本质上也是软件开发活动,当然也存在设计和代码脱节的风险。如果不解决掉这个问题,自动化测试设计最后还是会成为形式工程。试想一下,设计做了,文档也有了,但代码就是不按照设计来做,长此以往,谁还会注重自动化测试设计呢?
|
|||
|
|
|
|||
|
|
怎么办?解决架构腐化是个棘手的问题,幸运的是,现在业界也认识到了这一点,推出了很多方法论和技术。其中一个方法,就是通过设计直接生成代码来保持两者的一致性。
|
|||
|
|
|
|||
|
|
我在[第十六讲](https://time.geekbang.org/column/article/511982)里讲过Cucumber框架,利用Cucumber,测试设计的Feature文件可以直接转化成Java代码,Feature文件里的关键字Given,When,Then以注解的方式加在函数声明上。这就是设计转成代码的方法之一。
|
|||
|
|
|
|||
|
|
那TestJob该怎么做,才能让设计和代码保持一致呢?
|
|||
|
|
|
|||
|
|
### Auto Gen Auto:注解驱动机制
|
|||
|
|
|
|||
|
|
首先我们可以采用Cucumber的思路,把Job模型的关键字与代码概念做一个映射。比如Java代码,Job结构和Class结构,有以下的对应关系。
|
|||
|
|
|
|||
|
|
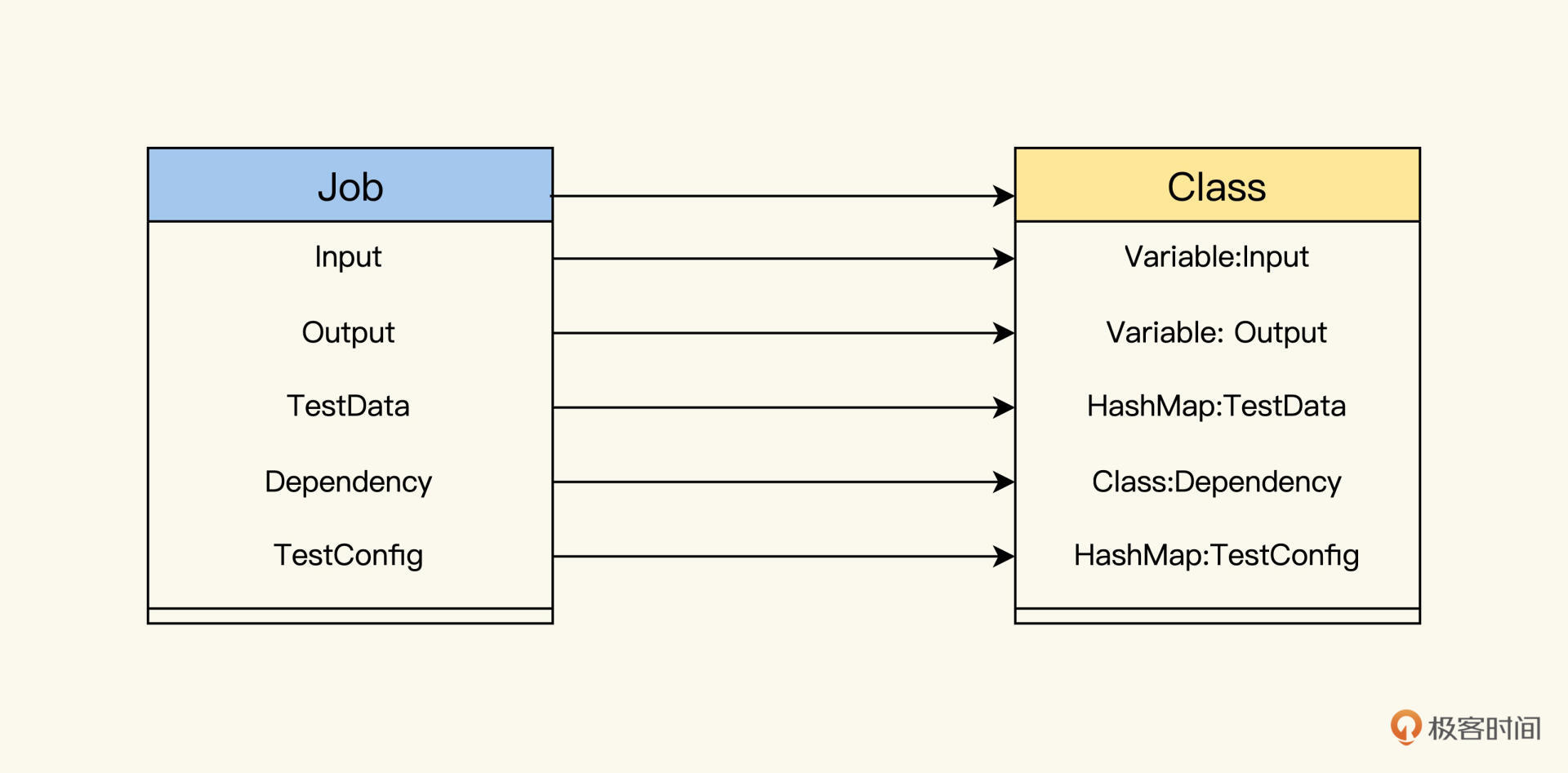
|
|||
|
|
|
|||
|
|
然后,再用上[第五讲](https://time.geekbang.org/column/article/499339)里Auto Gen Auto提到的思路,把模版自动化生成测试代码的方法,用到这里。
|
|||
|
|
|
|||
|
|
如下图所示,由Job Parser来解析Job树,然后将解析后的数据注入到代码模版里,就可以实现Job设计树到代码的自动转换了。
|
|||
|
|
|
|||
|
|
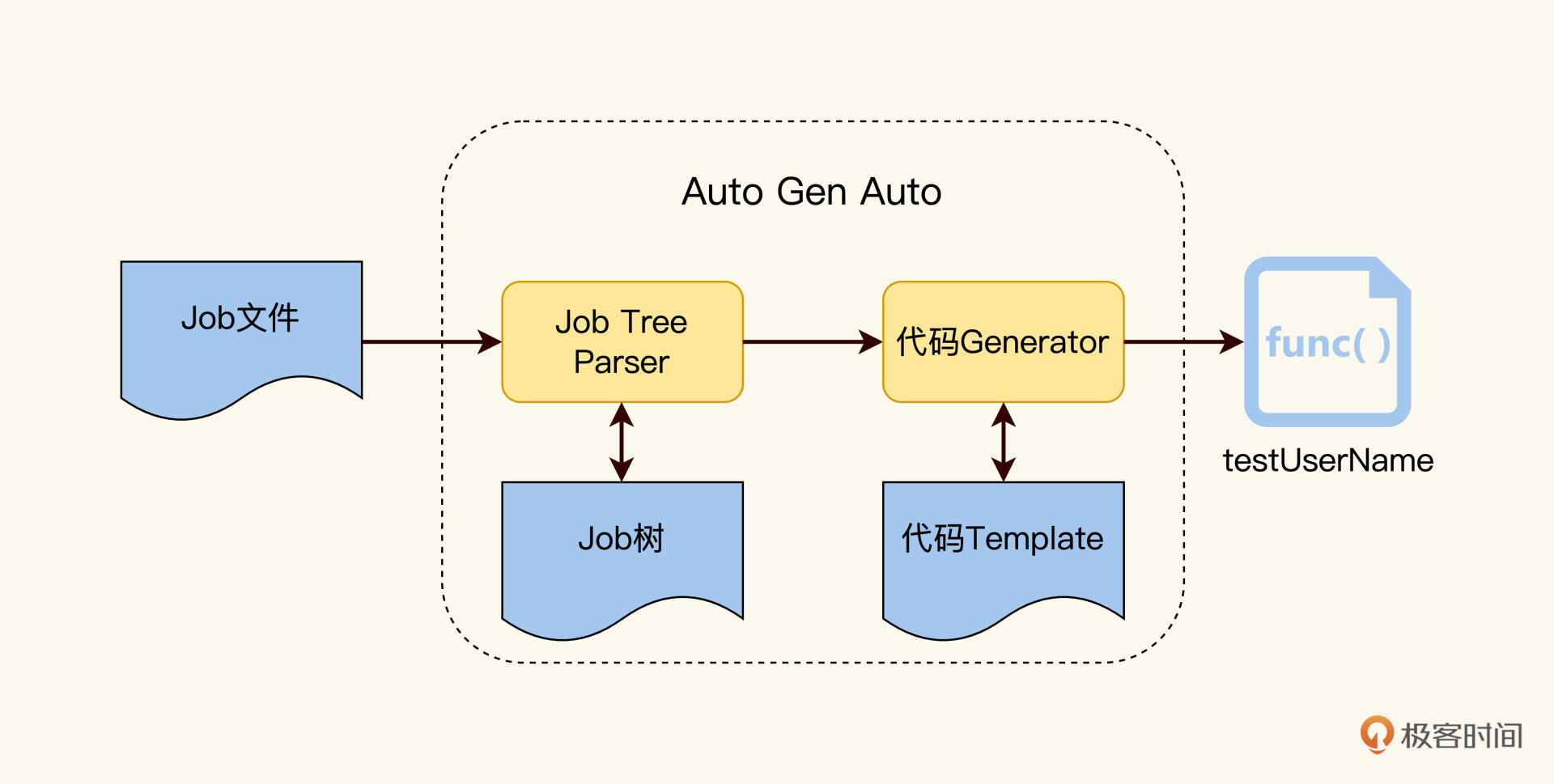
|
|||
|
|
|
|||
|
|
模版技术你可以使用Mustache(链接在[这里](https://en.wikipedia.org/wiki/Mustache_(template_system)))。
|
|||
|
|
|
|||
|
|
大致过程是这样的。首先,我们定义好后缀名为TestJob.mustache的代码模版文件,如下所示:
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
package {{package}};
|
|||
|
|
import java.util.*;
|
|||
|
|
@dependency({{dependency}})
|
|||
|
|
public class {{classname}} exetnds TestJob{
|
|||
|
|
{{#Inputs}}
|
|||
|
|
@Input
|
|||
|
|
public String {{input}};
|
|||
|
|
{{/inputs}}
|
|||
|
|
{{#Outputs}}
|
|||
|
|
@Output
|
|||
|
|
public String {{output}};
|
|||
|
|
{{/Outputs}}
|
|||
|
|
public run(){
|
|||
|
|
//TODO
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
然后通过Job Parser解析Job文件,向Mustache模版注入变量值,就可以生成代码了! 你可以脑补一下生成的代码。
|
|||
|
|
这种Auto Gen Auto方式解决了从Job设计到自动化测试代码的转换过程,自动化测试开发人员只需填充测试逻辑的实现代码即可。
|
|||
|
|
|
|||
|
|
Job怎么跑呢?这个时候JobRunner需要解析上面代码里的@Dependency、@Input、@Output的一个个注解,进行计算,得出执行路径,然后在运行时把数据注入到框架里。整个运行过程是由注解驱动的。
|
|||
|
|
|
|||
|
|
其实,业界流行的开发框架Spring Boot,就是这种注解驱动的机制,你可以作为参考。
|
|||
|
|
|
|||
|
|
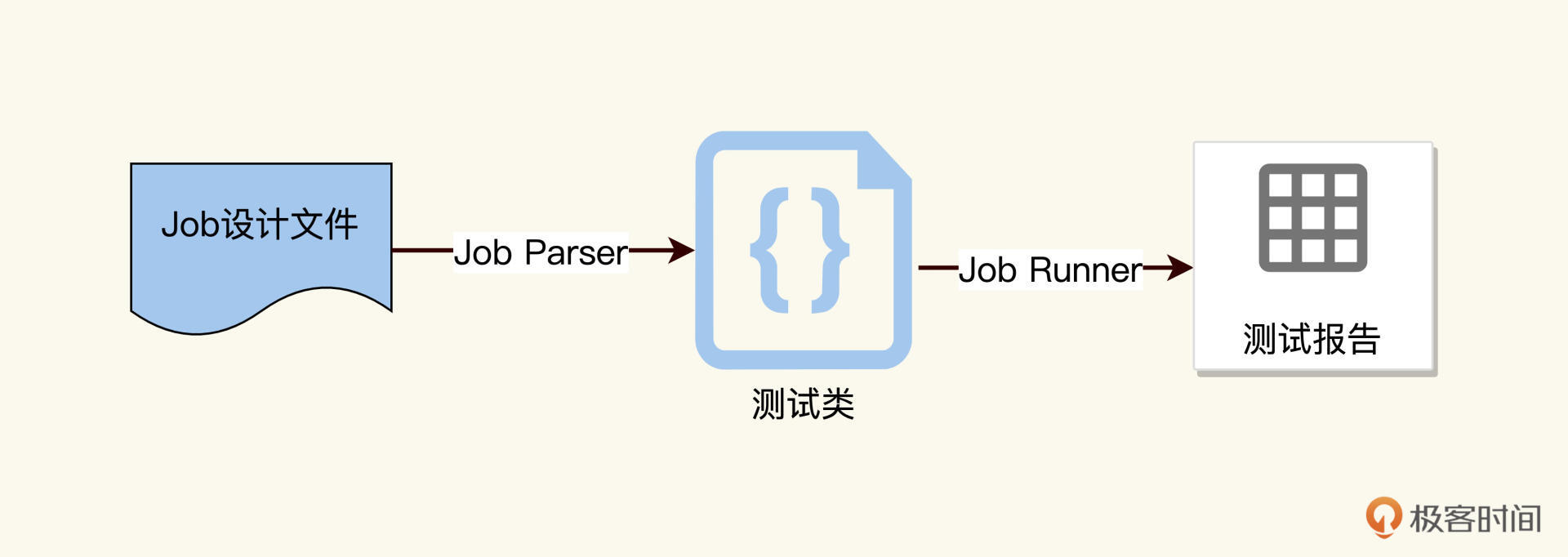
|
|||
|
|
|
|||
|
|
这个机制的优点是强大,扩展性强,但另外一面是,对Job Parser和Job Runner的开发技术要求高。再说直白点,就是这样的自动化测试框架开发投产比会比较低,只有稳定的测试组织,才能负担得起这样的开发投入和回报周期。
|
|||
|
|
|
|||
|
|
另外还有一种实现思路更轻量,Job设计文件就是可运行的文件,我们来看看。
|
|||
|
|
|
|||
|
|
### 设计文件即运行文件
|
|||
|
|
|
|||
|
|
如果你用过Apache Ant这个构建管理工具的话,你一定对编写Build.xml不会陌生。编写build.xml就是做任务设计,先创建Compile、Package、Test的Task,声明它们的调用关系,然后运行下面的命令:
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
ant -f build.xml
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
运行命令后,build.xml里定义的task就启动运行了。
|
|||
|
|
对于TestJobFile.xml,我们也可以采用相同的思路来处理。如果想让TestJobFile.xml里的TestJob能够启动运行,就需要把实例Job的运行细节填充进去。
|
|||
|
|
|
|||
|
|
比如一个通过QTP工具实现的实体Job,它要包含JobOutput、TestData数据源的类型和位置路径,还有引用的Library文件和运行的测试脚本路径。像下面这样:
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<QTP name="QTP_ScriptMode" description="QTP Script mdoe" depends="Java_Init">
|
|||
|
|
<JobOutput name="TicketNo"/>
|
|||
|
|
<TestData type="xls" location="testscripts\QTP\UILabelData\data_UI_Flight.xls"/>"
|
|||
|
|
<Lib location="common\lib_app\lib_flightdemo_login.vbs"/>
|
|||
|
|
<Lib location="common\lib_app\lib_utility.vbs"/>
|
|||
|
|
<Run path="testscripts\QTP\QTP_ScriptMode">
|
|||
|
|
</QTP>
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
而一个Selenium实现的实体Job,要包含Testdata,还有Java的ClassPath、TestCaseClass和TestMethod。
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<Selenium name="selenium_demo" description="Test calc" depends="" >
|
|||
|
|
<TestData type="xml" location="selenium\config.xml"/>
|
|||
|
|
<JobInput name="$number1"/>
|
|||
|
|
<ClassPath location="selenium\selenium-java-client-driver_self_extended_oracle.jar"/>
|
|||
|
|
<ClassPath location="selenium\my.jar"/>
|
|||
|
|
<ClassPath location=" selenium\selJava.jar"/>
|
|||
|
|
<SelTestCase path="selJava">
|
|||
|
|
<SelTest name="testSelJava "/>
|
|||
|
|
</SelTestCase>
|
|||
|
|
</Selenum>
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
通过代码我们可以看到,每种工具的实体Job都有一个Job定义的格式,那么,我们每完成一个Job的开发,就把这个Job的运行信息更新到TestJobFile.xml里去。
|
|||
|
|
|
|||
|
|
像Ant运行build.xml, Maven运行pom.xml一样,用JobRunner直接运行TestJobFile.xml, 运行命令如下,这样就能启动自动化测试执行了。
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
JobRunner -f TestJobFile.xml
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这样做主要有两个好处。第一,设计文件就是运行文件。Job开发完,需要更新设计文件,直接就可以运行,不存在设计和开发脱节的问题;第二,每个实体Job的运行都由JobRunner来驱动。这样一来,JobRunner就能判断出,Job有没有遵循它在设计文件里的承诺的Output,一旦Job的实现有了偏差,立刻就能发现。
|
|||
|
|
|
|||
|
|
我把TestJobFile.xml样例更新到了专栏的GitHub里,你可以点击[这里](https://github.com/sheng-geek-zhuanlan/autmation-arch/tree/master/module3)查看。
|
|||
|
|
|
|||
|
|
当然这个思路也有缺点,当TestJob定义过多的时候,这个TestJobFile.xml就会过于臃肿,难以维护。不过这个时候,也有解决办法,我们可以让TestJobFile支持引用和嵌套,就像build.xml和Maven里的pom.xml一样。
|
|||
|
|
|
|||
|
|
## Job运行报告
|
|||
|
|
|
|||
|
|
文档化和代码化的问题说完了,我们再来聊聊测试报告。测试报告是自动化测试最终的结果呈现。怎样利用Job模型来优化测试报告,让报告更好地服务各方人员呢?
|
|||
|
|
|
|||
|
|
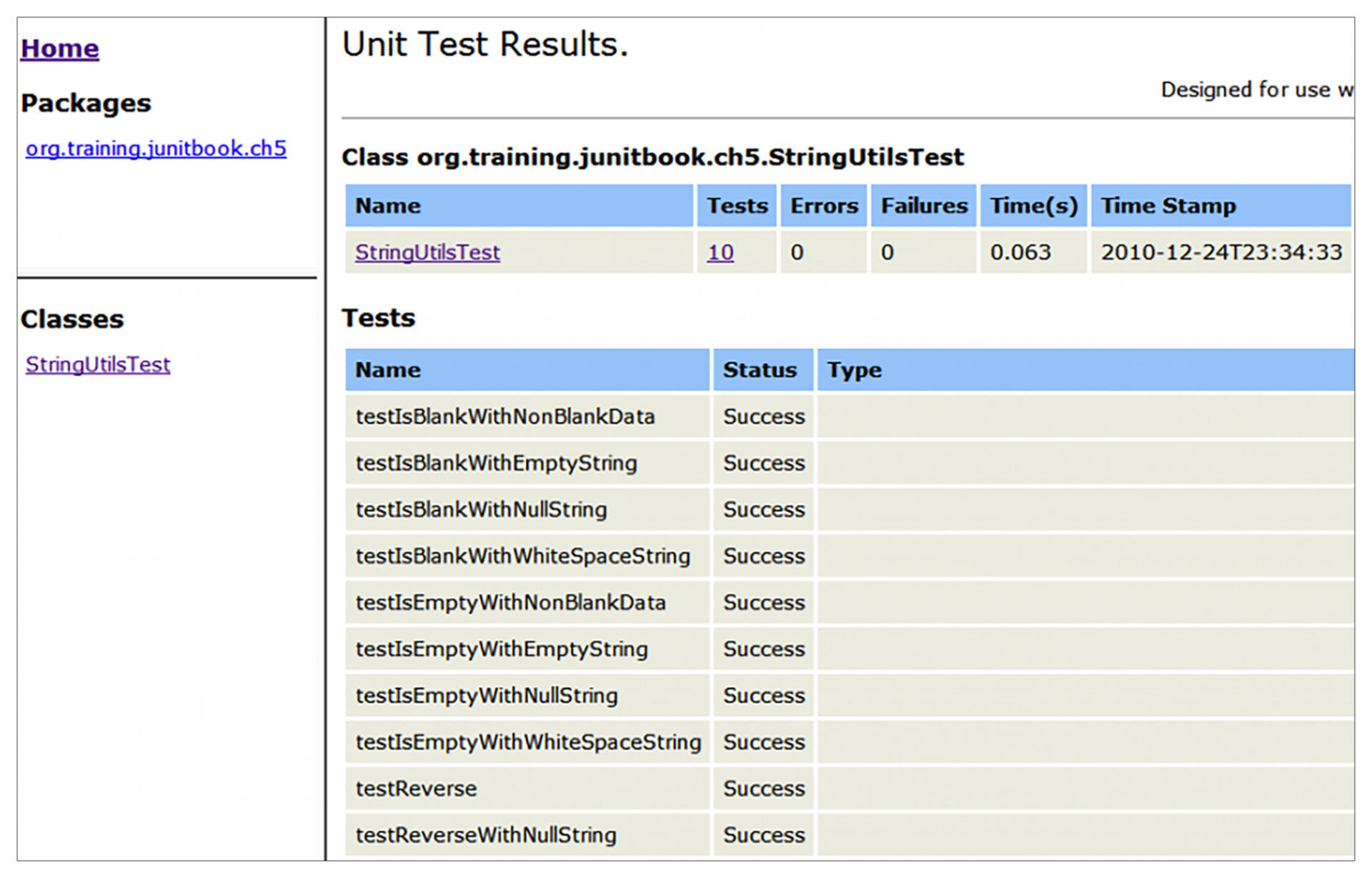
我们先看一下传统的自动化测试报告是什么样的,它们包含什么信息,又是怎么展现的。Junit框架产生的报告是这样的:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
发现了么?它报告的结构跟TestCase结构是一样的。在设计时,一个TestCase下有多个Test,运行产生报告后,结构保持不变。单个Test变成详细报告,有结果状态信息、检查点,还有Log输出;而TestCase变成汇总报告,聚合Test的执行结果,有成功率、失败率和执行时间等等。
|
|||
|
|
|
|||
|
|
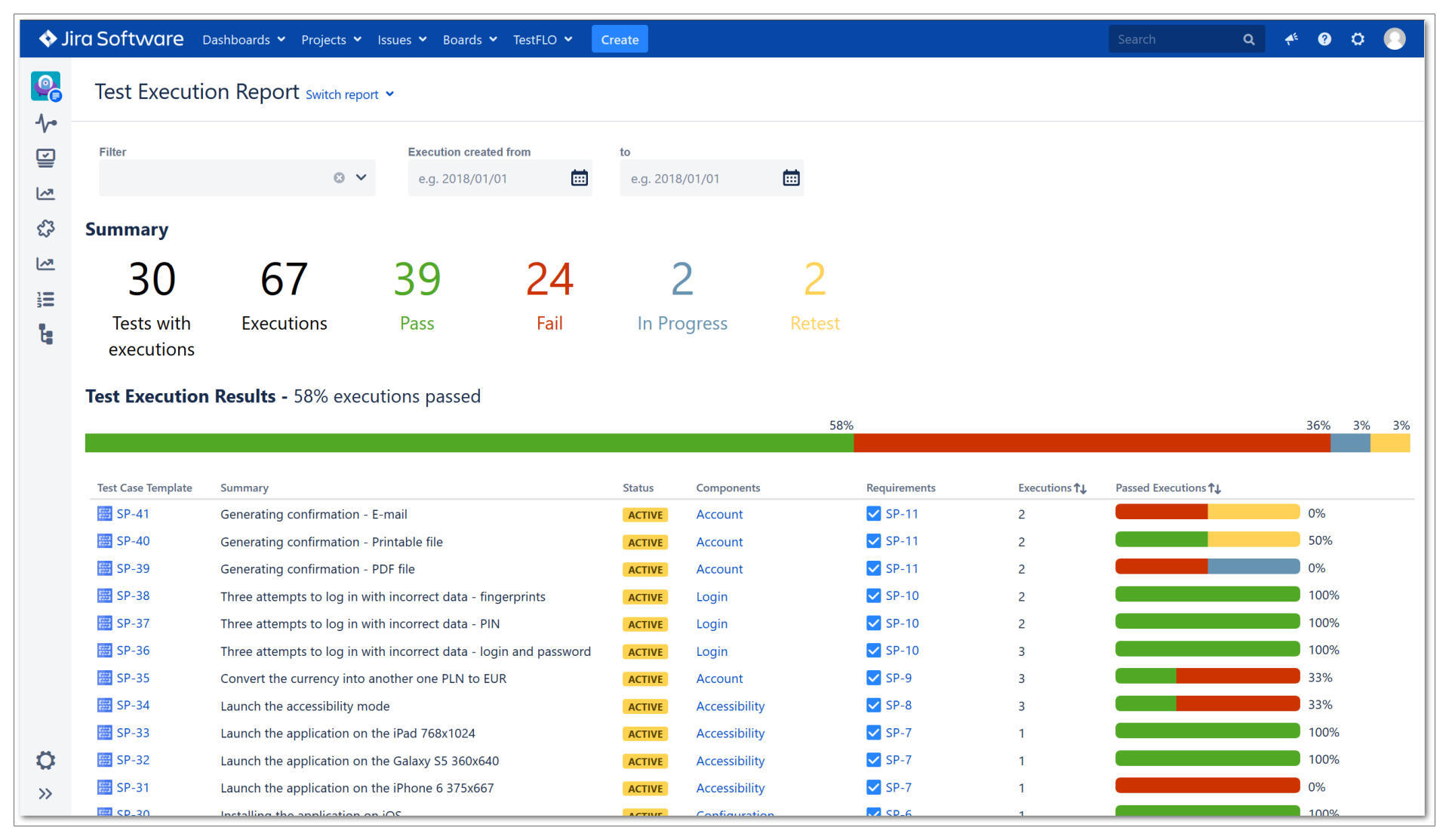
再来看一下Jira产生的测试报告:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
相比Junit报告,Jira的测试报告又丰富了一些信息。多了一个执行历史的维度,能看到一个TestCase执行的历史记录;还有TestCase和需求的关联关系,从这里就能得出测试对需求的覆盖度。
|
|||
|
|
|
|||
|
|
看了Junit和Jira的测试报告后,你会发现传统的测试报告里的数据定义不一样,展现风格也不一样。为什么会有这么大差别呢?
|
|||
|
|
|
|||
|
|
测试报告形式多样,但不管测试报告有多少种,有一个基本常识是不变的:**测试报告是给人看的**。只不过,不同角色的人,希望从测试报告里得到的信息是不一样的。
|
|||
|
|
|
|||
|
|
测试管理者想要确定发布的信心,在一个发布周期内测试对需求的覆盖度,关键Bug的数量。
|
|||
|
|
|
|||
|
|
测试经理关注测试设计的质量和测试执行的效率,比如测试案例发现Bug的数量、自动化测试执行的时间和假失败的次数等等。
|
|||
|
|
|
|||
|
|
自动化测试开发人员想要快速诊断错误,自然关注点就放在了出错的Log、抓图,还有出错时的现场信息等等。而从测试报告里,开发人员也希望得到错误定位到开发模块的信息,比如出错时间、服务端的执行链条、服务端log等等。
|
|||
|
|
|
|||
|
|
你能看到,不同角色的关注点不同,而且这些关注点随着项目的进展,也会发生变化。而我们通过Jira和Junit的例子看到,传统的测试报告数据和格式都很固定。
|
|||
|
|
|
|||
|
|
那么,Job模型能不能满足这些需求呢?既能产生多样数据的报告,又能给不同的角色看,还能够灵活扩展。
|
|||
|
|
|
|||
|
|
听起来有点复杂和烧脑,不过,如果把这个问题当作一个数据工程来处理,就能把复杂问题简单化,拆解成更容易解决的问题。我们把它分解成两个简单问题:第一,**如何获得这些数据**;第二,**这些数据如何聚合和展现,为每个角色提供感兴趣的信息**。
|
|||
|
|
|
|||
|
|
先解决第一个问题,也就是数据来源。Job模型在设计态和运行态下都是一棵Job树,所有的数据也都依附在这棵Job树上。
|
|||
|
|
|
|||
|
|
那数据就有两个来源:一个来源是在设计态下加到Job模型里的数据。比如测试Job和需求的关联,这在Job设计时,可以作为Job的一个属性RequirementID添加到Job模型里;另一个来源,是在运行态下采集到的数据。比如执行的检查点、测试Log、屏幕抓图等等,采集到这些数据之后,也可以添加到Job树里。
|
|||
|
|
|
|||
|
|
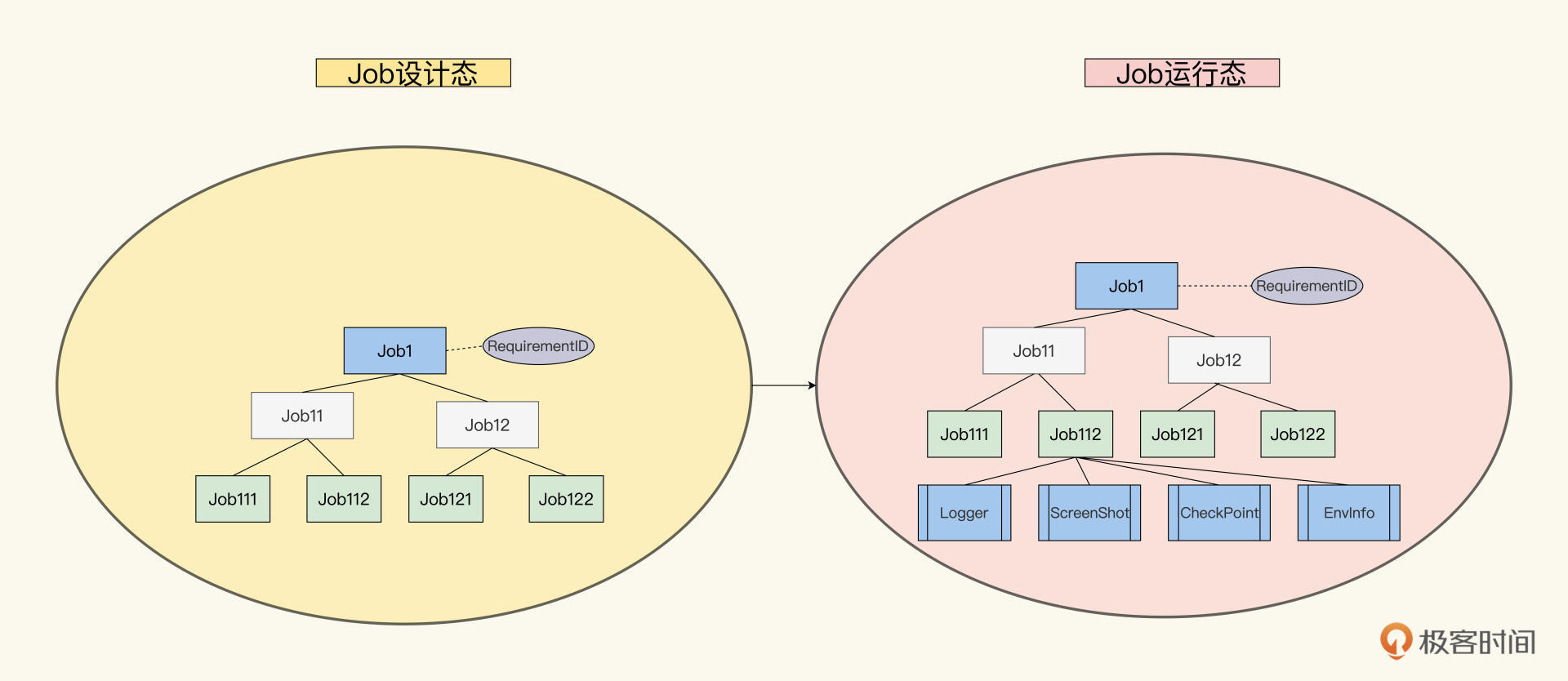
你可以想象这样的一个场景,Job树从设计态到运行态,是这棵树上的果实越来越多的过程。这里的果实就是数据,刚开始时只有设计数据,后来运行时数据也加进来了。参看下图,更有助于你加深印象。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
运行完毕后,这棵Job树就结满了果实。虽然你不知道谁会要什么样的水果拼盘,但你能通过根Job能遍历所有的果子,能做什么样的菜,自然就能心里有数了。
|
|||
|
|
|
|||
|
|
在每个Job节点执行相应的聚合算法,就可以生成不同层级的报告了。抽象Job可以生成汇总报告,而实例Job生成诊断报告。
|
|||
|
|
|
|||
|
|
现在,我们再把Job的设计态、运行态、结果态理一遍。通过下图,你会更清楚地看到这个数据采集到聚合的过程。
|
|||
|
|
|
|||
|
|
现在,你可能会问,我有了数据之后,到底怎么展现呢?这就涉及到数据工程的最后一个环节——数据可视化了。
|
|||
|
|
|
|||
|
|
传统的测试报告,会通过HTML展现。我们的TestJobFile.xml是XML文件,最后结果态Job树也是一个XML文件,你可以考虑通过XML+XSLT,来实现数据的处理和可变样式呈现。
|
|||
|
|
|
|||
|
|
如今的数据工程发展日新月异,自动化测试报告可以看作是数据工程的一个细分环节。这块的解决方案有很多,比如Grafana、Kibana、Tabelau等等。我在下一模块“数据度量”最后一讲里为你分享这个问题的实现思路和方法,敬请期待。
|
|||
|
|
|
|||
|
|
## 小结
|
|||
|
|
|
|||
|
|
为了把Job设计方法落地到你的日常工作活动中,我们用一讲的篇幅,依次讲解了将设计文档化、代码化和生成运行报告的方法。
|
|||
|
|
|
|||
|
|
怎么去评审和交流Job设计方案?这需要我们把Job设计文档化,而且要让评审高效,我们还要考虑好用什么数据格式呈现。
|
|||
|
|
|
|||
|
|
XML,YAML还是Json?这三种方式都能通用互相转换,找出适合你的团队的那一种。另外,还要能自动验证设计文档的合规性,这里的可用方法有Schema验证,还有自开发Validator代码的办法。
|
|||
|
|
|
|||
|
|
怎么能让Job设计和代码实现保持一致,不发生脱节呢?这里我们要考虑两个方向,一个是从设计到代码,另外一个是从代码到设计。
|
|||
|
|
|
|||
|
|
我们探讨了Auto Gen Auto的实现思路,还了解了一个模版利器**Mustache**,你可以用它产生任何类型的代码:Java、Go,JavaScript,甚至HTML等等。
|
|||
|
|
|
|||
|
|
另外还有一个轻量的思路,就是设计和执行合二为一,我们参考了Ant、Maven的运行机制,把TestJobFile.xml作为JobRunner的一个执行配置文件,直接就能跑起来。这样既能验证设计,又能验证代码。
|
|||
|
|
|
|||
|
|
最后,测试报告作为自动化测试最重要的成果,怎么能把价值充分展现呢?我们从传统报告里分析了需求之后,加以突破升级,用数据工程的思维理了一下自动化测试运行过程。
|
|||
|
|
|
|||
|
|
**这个过程,本质上是一个设计数据、采集数据、聚合数据和展现数据的数据工程。**用好Job模型的设计树、运行树、结果树,就能满足这个要求,设计树里设计数据,运行树采集数据,结果树聚合数据。
|
|||
|
|
|
|||
|
|
通过今天的学习,想必你也感受到了,在自动化测试领域,创新并落地一个新的设计方法,要比实现某个垂直领域的工具自动化要复杂很多,要考虑的点也多,也需要不小的开发工作量。
|
|||
|
|
|
|||
|
|
感谢你学习完这一模块。为了奖励你的耐心,也为了节省Job模型在你项目落地的时间,我把Job模型框架的代码上传到 [GitHub](https://github.com/sheng-geek-zhuanlan/JobFramework) 里,你可以参考,按需取用。
|
|||
|
|
|
|||
|
|
## **思考题**
|
|||
|
|
|
|||
|
|
在你的项目里,自动化测试报告都有哪些角色要看?报告里都展现了哪些数据,是什么格式呈现的?
|
|||
|
|
|
|||
|
|
欢迎你在留言区跟我交流互动。如果觉得今天讲的方法对你有启发,也推荐你分享给更多朋友、同事,一起学习进步。
|
|||
|
|
|