388 lines
16 KiB
Markdown
388 lines
16 KiB
Markdown
|
|
# 26 | 使用阻塞I/O和线程模型:换一种轻量的方式
|
|||
|
|
|
|||
|
|
你好,我是盛延敏,这里是网络编程实战第26讲,欢迎回来。
|
|||
|
|
|
|||
|
|
在前面一讲中,我们使用了进程模型来处理用户连接请求,进程切换上下文的代价是比较高的,幸运的是,有一种轻量级的模型可以处理多用户连接请求,这就是线程模型。这一讲里,我们就来了解一下线程模型。
|
|||
|
|
|
|||
|
|
线程(thread)是运行在进程中的一个“逻辑流”,现代操作系统都允许在单进程中运行多个线程。线程由操作系统内核管理。每个线程都有自己的上下文(context),包括一个可以唯一标识线程的ID(thread ID,或者叫tid)、栈、程序计数器、寄存器等。在同一个进程中,所有的线程共享该进程的整个虚拟地址空间,包括代码、数据、堆、共享库等。
|
|||
|
|
|
|||
|
|
在前面的程序中,我们没有显式使用线程,但这不代表线程没有发挥作用。实际上,每个进程一开始都会产生一个线程,一般被称为主线程,主线程可以再产生子线程,这样的主线程-子线程对可以叫做一个对等线程。
|
|||
|
|
|
|||
|
|
你可能会问,既然可以使用多进程来处理并发,为什么还要使用多线程模型呢?
|
|||
|
|
|
|||
|
|
简单来说,在同一个进程下,线程上下文切换的开销要比进程小得多。怎么理解线程上下文呢?我们的代码被CPU执行的时候,是需要一些数据支撑的,比如程序计数器告诉CPU代码执行到哪里了,寄存器里存了当前计算的一些中间值,内存里放置了一些当前用到的变量等,从一个计算场景,切换到另外一个计算场景,程序计数器、寄存器等这些值重新载入新场景的值,就是线程的上下文切换。
|
|||
|
|
|
|||
|
|
## POSIX线程模型
|
|||
|
|
|
|||
|
|
POSIX线程是现代UNIX系统提供的处理线程的标准接口。POSIX定义的线程函数大约有60多个,这些函数可以帮助我们创建线程、回收线程。接下来我们先看一个简单的例子程序。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int another_shared = 0;
|
|||
|
|
|
|||
|
|
void thread_run(void *arg) {
|
|||
|
|
int *calculator = (int *) arg;
|
|||
|
|
printf("hello, world, tid == %d \n", pthread_self());
|
|||
|
|
for (int i = 0; i < 1000; i++) {
|
|||
|
|
*calculator += 1;
|
|||
|
|
another_shared += 1;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
int main(int c, char **v) {
|
|||
|
|
int calculator;
|
|||
|
|
|
|||
|
|
pthread_t tid1;
|
|||
|
|
pthread_t tid2;
|
|||
|
|
|
|||
|
|
pthread_create(&tid1, NULL, thread_run, &calculator);
|
|||
|
|
pthread_create(&tid2, NULL, thread_run, &calculator);
|
|||
|
|
|
|||
|
|
pthread_join(tid1, NULL);
|
|||
|
|
pthread_join(tid2, NULL);
|
|||
|
|
|
|||
|
|
printf("calculator is %d \n", calculator);
|
|||
|
|
printf("another_shared is %d \n", another_shared);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
thread\_helloworld程序中,主线程依次创建了两个子线程,然后等待这两个子线程处理完毕之后终止。每个子线程都在对两个共享变量进行计算,最后在主线程中打印出最后的计算结果。
|
|||
|
|
|
|||
|
|
程序的第18和19行分别调用了pthread\_create创建了两个线程,每个线程的入口都是thread\_run函数,这里我们使用了calculator这个全局变量,并且通过传地址指针的方式,将这个值传给了thread\_run函数。当调用pthread\_create结束,子线程会立即执行,主线程在此后调用了pthread\_join函数等待子线程结束。
|
|||
|
|
|
|||
|
|
运行这个程序,很幸运,计算的结果是正确的。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
$./thread-helloworld
|
|||
|
|
hello, world, tid == 125607936
|
|||
|
|
hello, world, tid == 126144512
|
|||
|
|
calculator is 2000
|
|||
|
|
another_shared is 2000
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## 主要线程函数
|
|||
|
|
|
|||
|
|
### 创建线程
|
|||
|
|
|
|||
|
|
正如前面看到,通过调用pthread\_create函数来创建一个线程。这个函数的原型如下:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int pthread_create(pthread_t *tid, const pthread_attr_t *attr,
|
|||
|
|
void *(*func)(void *), void *arg);
|
|||
|
|
|
|||
|
|
返回:若成功则为0,若出错则为正的Exxx值
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
每个线程都有一个线程ID(tid)唯一来标识,其数据类型为pthread\_t,一般是unsigned int。pthread\_create函数的第一个输出参数tid就是代表了线程ID,如果创建线程成功,tid就返回正确的线程ID。
|
|||
|
|
|
|||
|
|
每个线程都会有很多属性,比如优先级、是否应该成为一个守护进程等,这些值可以通过pthread\_attr\_t来描述,一般我们不会特殊设置,可以直接指定这个参数为NULL。
|
|||
|
|
|
|||
|
|
第三个参数为新线程的入口函数,该函数可以接收一个参数arg,类型为指针,如果我们想给线程入口函数传多个值,那么需要把这些值包装成一个结构体,再把这个结构体的地址作为pthread\_create的第四个参数,在线程入口函数内,再将该地址转为该结构体的指针对象。
|
|||
|
|
|
|||
|
|
在新线程的入口函数内,可以执行pthread\_self函数返回线程tid。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
pthread_t pthread_self(void)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 终止线程
|
|||
|
|
|
|||
|
|
终止一个线程最直接的方法是在父线程内调用以下函数:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
void pthread_exit(void *status)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
当调用这个函数之后,父线程会等待其他所有的子线程终止,之后父线程自己终止。
|
|||
|
|
|
|||
|
|
当然,如果一个子线程入口函数直接退出了,那么子线程也就自然终止了。所以,绝大多数的子线程执行体都是一个无限循环。
|
|||
|
|
|
|||
|
|
也可以通过调用pthread\_cancel来主动终止一个子线程,和pthread\_exit不同的是,它可以指定某个子线程终止。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int pthread_cancel(pthread_t tid)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 回收已终止线程的资源
|
|||
|
|
|
|||
|
|
我们可以通过调用pthread\_join回收已终止线程的资源:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int pthread_join(pthread_t tid, void ** thread_return)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
当调用pthread\_join时,主线程会阻塞,直到对应tid的子线程自然终止。和pthread\_cancel不同的是,它不会强迫子线程终止。
|
|||
|
|
|
|||
|
|
### 分离线程
|
|||
|
|
|
|||
|
|
一个线程的重要属性是可结合的,或者是分离的。一个可结合的线程是能够被其他线程杀死和回收资源的;而一个分离的线程不能被其他线程杀死或回收资源。一般来说,默认的属性是可结合的。
|
|||
|
|
|
|||
|
|
我们可以通过调用pthread\_detach函数可以分离一个线程:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
int pthread_detach(pthread_t tid)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在高并发的例子里,每个连接都由一个线程单独处理,在这种情况下,服务器程序并不需要对每个子线程进行终止,这样的话,每个子线程可以在入口函数开始的地方,把自己设置为分离的,这样就能在它终止后自动回收相关的线程资源了,就不需要调用pthread\_join函数了。
|
|||
|
|
|
|||
|
|
## 每个连接一个线程处理
|
|||
|
|
|
|||
|
|
接下来,我们改造一下服务器端程序。我们的目标是这样:每次有新的连接到达后,创建一个新线程,而不是用新进程来处理它。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
#include "lib/common.h"
|
|||
|
|
|
|||
|
|
extern void loop_echo(int);
|
|||
|
|
|
|||
|
|
void thread_run(void *arg) {
|
|||
|
|
pthread_detach(pthread_self());
|
|||
|
|
int fd = (int) arg;
|
|||
|
|
loop_echo(fd);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
int main(int c, char **v) {
|
|||
|
|
int listener_fd = tcp_server_listen(SERV_PORT);
|
|||
|
|
pthread_t tid;
|
|||
|
|
|
|||
|
|
while (1) {
|
|||
|
|
struct sockaddr_storage ss;
|
|||
|
|
socklen_t slen = sizeof(ss);
|
|||
|
|
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
|
|||
|
|
if (fd < 0) {
|
|||
|
|
error(1, errno, "accept failed");
|
|||
|
|
} else {
|
|||
|
|
pthread_create(&tid, NULL, &thread_run, (void *) fd);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这个程序的第18行阻塞调用在accept上,一旦有新连接建立,阻塞调用返回,调用pthread\_create创建一个子线程来处理这个连接。
|
|||
|
|
|
|||
|
|
描述连接最主要的是连接描述字,这里通过强制把描述字转换为void \*指针的方式,完成了传值。如果你对这部分有点不理解,建议看一下C语言相关的指针部分内容。我们这里可以简单总结一下,虽然传的是一个指针,但是这个指针里存放的并不是一个地址,而是连接描述符的数值。
|
|||
|
|
|
|||
|
|
新线程入口函数thread\_run里,第6行使用了pthread\_detach方法,将子线程转变为分离的,也就意味着子线程独自负责线程资源回收。第7行,强制将指针转变为描述符数据,和前面将描述字转换为void \*指针对应,第8行调用loop\_echo方法处理这个连接的数据读写。
|
|||
|
|
|
|||
|
|
loop\_echo的程序如下,在接收客户端的数据之后,再编码回送出去。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
char rot13_char(char c) {
|
|||
|
|
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
|
|||
|
|
return c + 13;
|
|||
|
|
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
|
|||
|
|
return c - 13;
|
|||
|
|
else
|
|||
|
|
return c;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
void loop_echo(int fd) {
|
|||
|
|
char outbuf[MAX_LINE + 1];
|
|||
|
|
size_t outbuf_used = 0;
|
|||
|
|
ssize_t result;
|
|||
|
|
while (1) {
|
|||
|
|
char ch;
|
|||
|
|
result = recv(fd, &ch, 1, 0);
|
|||
|
|
|
|||
|
|
//断开连接或者出错
|
|||
|
|
if (result == 0) {
|
|||
|
|
break;
|
|||
|
|
} else if (result == -1) {
|
|||
|
|
error(1, errno, "read error");
|
|||
|
|
break;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
if (outbuf_used < sizeof(outbuf)) {
|
|||
|
|
outbuf[outbuf_used++] = rot13_char(ch);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
if (ch == '\n') {
|
|||
|
|
send(fd, outbuf, outbuf_used, 0);
|
|||
|
|
outbuf_used = 0;
|
|||
|
|
continue;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
运行这个程序之后,开启多个telnet客户端,可以看到这个服务器程序可以处理多个并发连接并回送数据。单独一个连接退出也不会影响其他连接的数据收发。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
$telnet 127.0.0.1 43211
|
|||
|
|
Trying 127.0.0.1...
|
|||
|
|
Connected to localhost.
|
|||
|
|
Escape character is '^]'.
|
|||
|
|
aaa
|
|||
|
|
nnn
|
|||
|
|
^]
|
|||
|
|
telnet> quit
|
|||
|
|
Connection closed.
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## 构建线程池处理多个连接
|
|||
|
|
|
|||
|
|
上面的服务器端程序虽然可以正常工作,不过它有一个缺点,那就是如果并发连接过多,就会引起线程的频繁创建和销毁。虽然线程切换的上下文开销不大,但是线程创建和销毁的开销却是不小的。
|
|||
|
|
|
|||
|
|
能不能对这个程序进行一些优化呢?
|
|||
|
|
|
|||
|
|
我们可以使用预创建线程池的方式来进行优化。在服务器端启动时,可以先按照固定大小预创建出多个线程,当有新连接建立时,往连接字队列里放置这个新连接描述字,线程池里的线程负责从连接字队列里取出连接描述字进行处理。
|
|||
|
|
|
|||
|
|
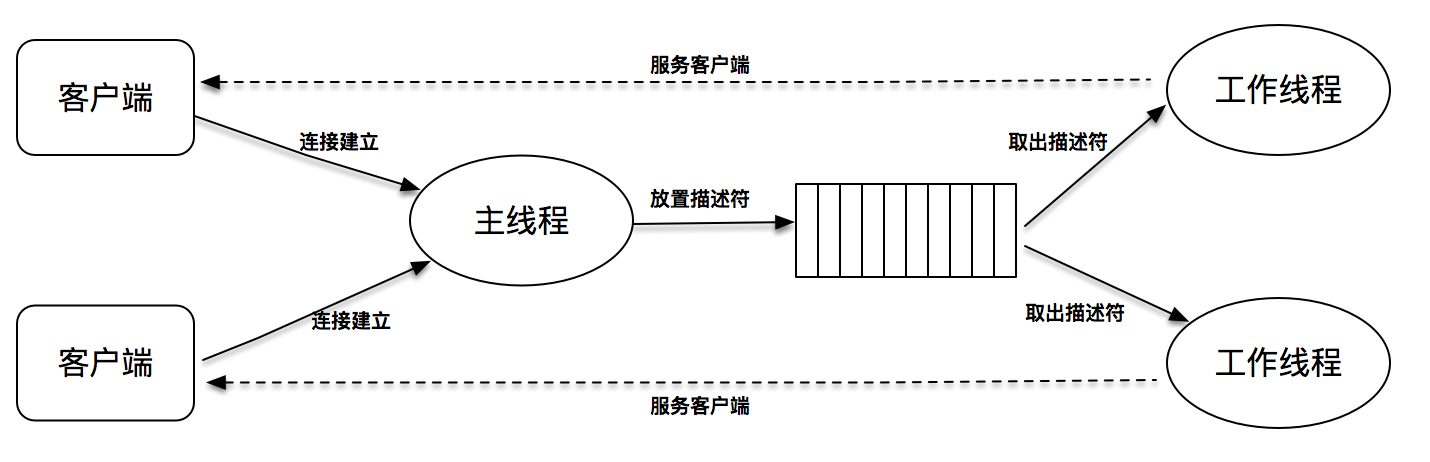
|
|||
|
|
这个程序的关键是连接字队列的设计,因为这里既有往这个队列里放置描述符的操作,也有从这个队列里取出描述符的操作。
|
|||
|
|
|
|||
|
|
对此,需要引入两个重要的概念,一个是锁mutex,一个是条件变量condition。锁很好理解,加锁的意思就是其他线程不能进入;条件变量则是在多个线程需要交互的情况下,用来线程间同步的原语。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
//定义一个队列
|
|||
|
|
typedef struct {
|
|||
|
|
int number; //队列里的描述字最大个数
|
|||
|
|
int *fd; //这是一个数组指针
|
|||
|
|
int front; //当前队列的头位置
|
|||
|
|
int rear; //当前队列的尾位置
|
|||
|
|
pthread_mutex_t mutex; //锁
|
|||
|
|
pthread_cond_t cond; //条件变量
|
|||
|
|
} block_queue;
|
|||
|
|
|
|||
|
|
//初始化队列
|
|||
|
|
void block_queue_init(block_queue *blockQueue, int number) {
|
|||
|
|
blockQueue->number = number;
|
|||
|
|
blockQueue->fd = calloc(number, sizeof(int));
|
|||
|
|
blockQueue->front = blockQueue->rear = 0;
|
|||
|
|
pthread_mutex_init(&blockQueue->mutex, NULL);
|
|||
|
|
pthread_cond_init(&blockQueue->cond, NULL);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
//往队列里放置一个描述字fd
|
|||
|
|
void block_queue_push(block_queue *blockQueue, int fd) {
|
|||
|
|
//一定要先加锁,因为有多个线程需要读写队列
|
|||
|
|
pthread_mutex_lock(&blockQueue->mutex);
|
|||
|
|
//将描述字放到队列尾的位置
|
|||
|
|
blockQueue->fd[blockQueue->rear] = fd;
|
|||
|
|
//如果已经到最后,重置尾的位置
|
|||
|
|
if (++blockQueue->rear == blockQueue->number) {
|
|||
|
|
blockQueue->rear = 0;
|
|||
|
|
}
|
|||
|
|
printf("push fd %d", fd);
|
|||
|
|
//通知其他等待读的线程,有新的连接字等待处理
|
|||
|
|
pthread_cond_signal(&blockQueue->cond);
|
|||
|
|
//解锁
|
|||
|
|
pthread_mutex_unlock(&blockQueue->mutex);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
//从队列里读出描述字进行处理
|
|||
|
|
int block_queue_pop(block_queue *blockQueue) {
|
|||
|
|
//加锁
|
|||
|
|
pthread_mutex_lock(&blockQueue->mutex);
|
|||
|
|
//判断队列里没有新的连接字可以处理,就一直条件等待,直到有新的连接字入队列
|
|||
|
|
while (blockQueue->front == blockQueue->rear)
|
|||
|
|
pthread_cond_wait(&blockQueue->cond, &blockQueue->mutex);
|
|||
|
|
//取出队列头的连接字
|
|||
|
|
int fd = blockQueue->fd[blockQueue->front];
|
|||
|
|
//如果已经到最后,重置头的位置
|
|||
|
|
if (++blockQueue->front == blockQueue->number) {
|
|||
|
|
blockQueue->front = 0;
|
|||
|
|
}
|
|||
|
|
printf("pop fd %d", fd);
|
|||
|
|
//解锁
|
|||
|
|
pthread_mutex_unlock(&blockQueue->mutex);
|
|||
|
|
//返回连接字
|
|||
|
|
return fd;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这里有block\_queue相关的定义和实现,并在关键的地方加了一些注释,有几个地方需要特别注意:
|
|||
|
|
|
|||
|
|
第一是记得对操作进行加锁和解锁,这里是通过pthread\_mutex\_lock和pthread\_mutex\_unlock来完成的。
|
|||
|
|
|
|||
|
|
第二是当工作线程没有描述字可用时,需要等待,第43行通过调用pthread\_cond\_wait,所有的工作线程等待有新的描述字可达。第32行,主线程通知工作线程有新的描述符需要服务。
|
|||
|
|
|
|||
|
|
服务器端程序如下:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
void thread_run(void *arg) {
|
|||
|
|
pthread_t tid = pthread_self();
|
|||
|
|
pthread_detach(tid);
|
|||
|
|
|
|||
|
|
block_queue *blockQueue = (block_queue *) arg;
|
|||
|
|
while (1) {
|
|||
|
|
int fd = block_queue_pop(blockQueue);
|
|||
|
|
printf("get fd in thread, fd==%d, tid == %d", fd, tid);
|
|||
|
|
loop_echo(fd);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
int main(int c, char **v) {
|
|||
|
|
int listener_fd = tcp_server_listen(SERV_PORT);
|
|||
|
|
|
|||
|
|
block_queue blockQueue;
|
|||
|
|
block_queue_init(&blockQueue, BLOCK_QUEUE_SIZE);
|
|||
|
|
|
|||
|
|
thread_array = calloc(THREAD_NUMBER, sizeof(Thread));
|
|||
|
|
int i;
|
|||
|
|
for (i = 0; i < THREAD_NUMBER; i++) {
|
|||
|
|
pthread_create(&(thread_array[i].thread_tid), NULL, &thread_run, (void *) &blockQueue);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
while (1) {
|
|||
|
|
struct sockaddr_storage ss;
|
|||
|
|
socklen_t slen = sizeof(ss);
|
|||
|
|
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
|
|||
|
|
if (fd < 0) {
|
|||
|
|
error(1, errno, "accept failed");
|
|||
|
|
} else {
|
|||
|
|
block_queue_push(&blockQueue, fd);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
有了描述字队列,主程序变得非常简洁。第19-23行预创建了多个线程,组成了一个线程池。28-32行在新连接建立后,将连接描述字加入到队列中。
|
|||
|
|
|
|||
|
|
7-9行是工作线程的主循环,从描述字队列中取出描述字,对这个连接进行服务处理。
|
|||
|
|
|
|||
|
|
同样的,运行这个程序之后,开启多个telnet客户端,可以看到这个服务器程序可以正常处理多个并发连接并回显。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
$telnet 127.0.0.1 43211
|
|||
|
|
Trying 127.0.0.1...
|
|||
|
|
Connected to localhost.
|
|||
|
|
Escape character is '^]'.
|
|||
|
|
aaa
|
|||
|
|
nnn
|
|||
|
|
^]
|
|||
|
|
telnet> quit
|
|||
|
|
Connection closed.
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
和前面的程序相比,线程创建和销毁的开销大大降低,但因为线程池大小固定,又因为使用了阻塞套接字,肯定会出现有连接得不到及时服务的场景。这个问题的解决还是要回到我在开篇词里提到的方案上来,多路I/O复用加上线程来处理,仅仅使用阻塞I/O模型和线程是没有办法达到极致的高并发处理能力。
|
|||
|
|
|
|||
|
|
## 总结
|
|||
|
|
|
|||
|
|
这一讲,我们使用了线程来构建服务器端程序。一种是每次动态创建线程,另一种是使用线程池提高效率。和进程相比,线程的语义更轻量,使用的场景也更多。线程是高性能网络服务器必须掌握的核心知识,希望你能够通过本讲的学习,牢牢掌握它。
|
|||
|
|
|
|||
|
|
## 思考题
|
|||
|
|
|
|||
|
|
和往常一样,给你留两道思考题。
|
|||
|
|
|
|||
|
|
第一道,连接字队列的实现里,有一个重要情况没有考虑,就是队列里没有可用的位置了,想想看,如何对这种情况进行优化?
|
|||
|
|
|
|||
|
|
第二道,我在讲到第一个hello-world计数器应用时,说“结果是幸运”这是为什么呢?怎么理解呢?
|
|||
|
|
|
|||
|
|
欢迎你在评论区写下你的思考,我会和你一起思考,也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
|
|||
|
|
|