|
|
|
|
|
# 12 | 如何调整TCP拥塞控制的性能?
|
|
|
|
|
|
|
|
|
|
|
|
你好,我是陶辉。
|
|
|
|
|
|
|
|
|
|
|
|
上一讲我们谈到接收主机的处理能力不足时,是通过滑动窗口来减缓对方的发送速度。这一讲我们来看看,当网络处理能力不足时又该如何优化TCP的性能。
|
|
|
|
|
|
|
|
|
|
|
|
如果你阅读过TCP协议相关的书籍,一定看到过慢启动、拥塞控制等名词。这些概念似乎离应用开发者很远,然而,如果没有拥塞控制,整个网络将会锁死,所有消息都无法传输。
|
|
|
|
|
|
|
|
|
|
|
|
而且,如果你在开发分布式集群中的高并发服务,理解拥塞控制的工作原理,就可以在内核的TCP层,提升所有进程的网络性能。比如,你可能听过,2013年谷歌把初始拥塞窗口从3个MSS(最大报文长度)左右提升到10个MSS,将Web站点的网络性能提升了10%以上,而有些高速CDN站点,甚至把初始拥塞窗口提升到70个MSS。
|
|
|
|
|
|
|
|
|
|
|
|
特别是,近年来谷歌提出的BBR拥塞控制算法已经应用在高版本的Linux内核中,从它在YouTube上的应用可以看到,在高性能站点上网络时延有20%以上的降低,传输带宽也有提高。
|
|
|
|
|
|
|
|
|
|
|
|
Linux允许我们调整拥塞控制算法,但是,正确地设置参数,还需要深入理解拥塞控制对TCP连接的影响。这一讲我们将沿着网络如何影响发送速度这条线,看看如何调整Linux下的拥塞控制参数。
|
|
|
|
|
|
|
|
|
|
|
|
## 慢启动阶段如何调整初始拥塞窗口?
|
|
|
|
|
|
|
|
|
|
|
|
上一讲谈到,只要接收方的读缓冲区足够大,就可以通过报文中的接收窗口,要求对方更快地发送数据。然而,网络的传输速度是有限的,它会直接丢弃超过其处理能力的报文。而发送方只有在重传定时器超时后,才能发现超发的报文被网络丢弃了,发送速度提不上去。更为糟糕的是,如果网络中的每个连接都按照接收窗口尽可能地发送更多的报文时,就会形成恶性循环,最终超高的网络丢包率会使得每个连接都无法发送数据。
|
|
|
|
|
|
|
|
|
|
|
|
解决这一问题的方案叫做拥塞控制,它包括4个阶段,我们首先来看TCP连接刚建立时的慢启动阶段。由于TCP连接会穿越许多网络,所以最初并不知道网络的传输能力,为了避免发送超过网络负载的报文,TCP只能先调低发送窗口(关于发送窗口,你可以参考[\[第11讲\]](https://time.geekbang.org/column/article/239176)),减少飞行中的报文来让发送速度变慢,这也是“慢启动”名字的由来。
|
|
|
|
|
|
|
|
|
|
|
|
让发送速度变慢是通过引入拥塞窗口(全称为congestion window,缩写为CWnd,类似地,接收窗口叫做rwnd,发送窗口叫做swnd)实现的,它用于避免网络出现拥塞。上一讲我们说过,如果不考虑网络拥塞,发送窗口就等于对方的接收窗口,而考虑了网络拥塞后,发送窗口则应当是拥塞窗口与对方接收窗口的最小值:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
swnd = min(cwnd, rwnd)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
这样,发送速度就综合考虑了接收方和网络的处理能力。
|
|
|
|
|
|
|
|
|
|
|
|
虽然窗口的计量单位是字节,但为了方便理解,通常我们用MSS作为描述窗口大小的单位,其中MSS是TCP报文的最大长度。
|
|
|
|
|
|
|
|
|
|
|
|
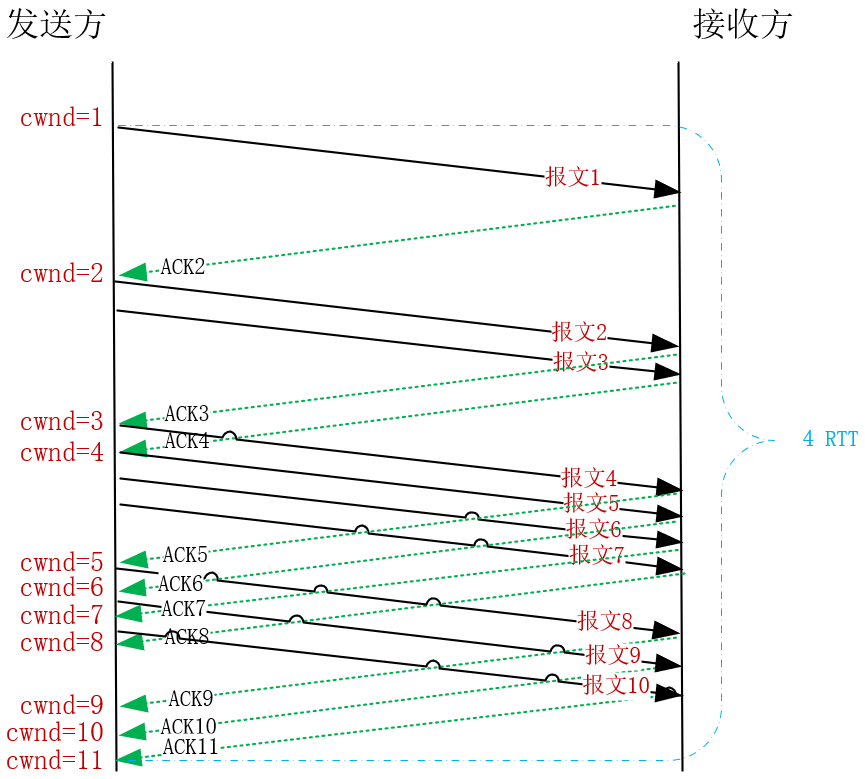
如果初始拥塞窗口只有1个MSS,当MSS是1KB,而RTT时延是100ms时,发送速度只有10KB/s。所以,当没有发生拥塞时,拥塞窗口必须快速扩大,才能提高互联网的传输速度。因此,慢启动阶段会以指数级扩大拥塞窗口(扩大规则是这样的:发送方每收到一个ACK确认报文,拥塞窗口就增加1个MSS),比如最初的初始拥塞窗口(也称为initcwnd)是1个MSS,经过4个RTT就会变成16个MSS。
|
|
|
|
|
|
|
|
|
|
|
|
虽然指数级提升发送速度很快,但互联网中的很多资源体积并不大,多数场景下,在传输速度没有达到最大时,资源就已经下载完了。下图是2010年Google对Web对象大小的CDF累积分布统计,大多数对象在10KB左右。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
这样,当MSS是1KB时,多数HTTP请求至少包含10个报文,即使以指数级增加拥塞窗口,也需要至少4个RTT才能传输完,参见下图:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
因此,2013年TCP的初始拥塞窗口调整到了10个MSS(参见[RFC6928](https://tools.ietf.org/html/rfc6928)),这样1个RTT内就可以传输10KB的请求。然而,如果你需要传输的对象体积更大,BDP带宽时延积很大时,完全可以继续提高初始拥塞窗口的大小。下图是2014年、2017年全球主要CDN厂商初始拥塞窗口的变化,可见,随着网速的增加,初始拥塞窗口也变得更大了。
|
|
|
|
|
|
|
|
|
|
|
|
[](https://blog.imaginea.com/look-at-tcp-initcwnd-cdns/)
|
|
|
|
|
|
|
|
|
|
|
|
因此,你可以根据网络状况和传输对象的大小,调整初始拥塞窗口的大小。调整前,先要清楚你的服务器现在的初始拥塞窗口是多大。你可以通过ss命令查看当前拥塞窗口:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
# ss -nli|fgrep cwnd
|
|
|
|
|
|
cubic rto:1000 mss:536 cwnd:10 segs_in:10621866 lastsnd:1716864402 lastrcv:1716864402 lastack:1716864402
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
再通过ip route change命令修改初始拥塞窗口:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
# ip route | while read r; do
|
|
|
|
|
|
ip route change $r initcwnd 10;
|
|
|
|
|
|
done
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
当然,更大的初始拥塞窗口以及指数级的提速,连接很快就会遭遇网络拥塞,从而导致慢启动阶段的结束。
|
|
|
|
|
|
|
|
|
|
|
|
## 出现网络拥塞时该怎么办?
|
|
|
|
|
|
|
|
|
|
|
|
以下3种场景都会导致慢启动阶段结束:
|
|
|
|
|
|
|
|
|
|
|
|
1. 通过定时器明确探测到了丢包;
|
|
|
|
|
|
2. 拥塞窗口的增长到达了慢启动阈值ssthresh(全称为slow start threshold),也就是之前发现网络拥塞时的窗口大小;
|
|
|
|
|
|
3. 接收到重复的ACK报文,可能存在丢包。
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看第1种场景,在规定时间内没有收到ACK报文,这说明报文丢失了,网络出现了严重的拥塞,必须先降低发送速度,再进入拥塞避免阶段。不同的拥塞控制算法降低速度的幅度并不相同,比如CUBIC算法会把拥塞窗口降为原先的0.8倍(也就是发送速度降到0.8倍)。此时,我们知道了多大的窗口会导致拥塞,因此可以把慢启动阈值设为发生拥塞前的窗口大小。
|
|
|
|
|
|
|
|
|
|
|
|
再看第2种场景,虽然还没有发生丢包,但发送方已经达到了曾经发生网络拥塞的速度(拥塞窗口达到了慢启动阈值),接下来发生拥塞的概率很高,所以进入**拥塞避免阶段,此时拥塞窗口不能再以指数方式增长,而是要以线性方式增长**。接下来,拥塞窗口会以每个RTT增加1个MSS的方式,代替慢启动阶段每收到1个ACK就增加1个MSS的方式。这里可能有同学会有疑问,在第1种场景发生前,慢启动阈值是多大呢?事实上,[RFC5681](https://tools.ietf.org/html/rfc5681#page-5) 建议最初的慢启动阈值尽可能的大,这样才能在第1、3种场景里快速发现网络瓶颈。
|
|
|
|
|
|
|
|
|
|
|
|
第3种场景最为复杂。我们知道,TCP传输的是字节流,而“流”是天然有序的。因此,当接收方收到不连续的报文时,就可能发生报文丢失或者延迟,等待发送方超时重发太花时间了,为了缩短重发时间,**快速重传算法便应运而生。**
|
|
|
|
|
|
|
|
|
|
|
|
当连续收到3个重复ACK时,发送方便得到了网络发生拥塞的明确信号,通过重复ACK报文的序号,我们知道丢失了哪个报文,这样,不等待定时器的触发,立刻重发丢失的报文,可以让发送速度下降得慢一些,这就是快速重传算法。
|
|
|
|
|
|
|
|
|
|
|
|
出现拥塞后,发送方会缩小拥塞窗口,再进入前面提到的拥塞避免阶段,用线性速度慢慢增加拥塞窗口。然而,**为了平滑地降低速度,发送方应当先进入快速恢复阶段,在失序报文到达接收方后,再进入拥塞避免阶段。**
|
|
|
|
|
|
|
|
|
|
|
|
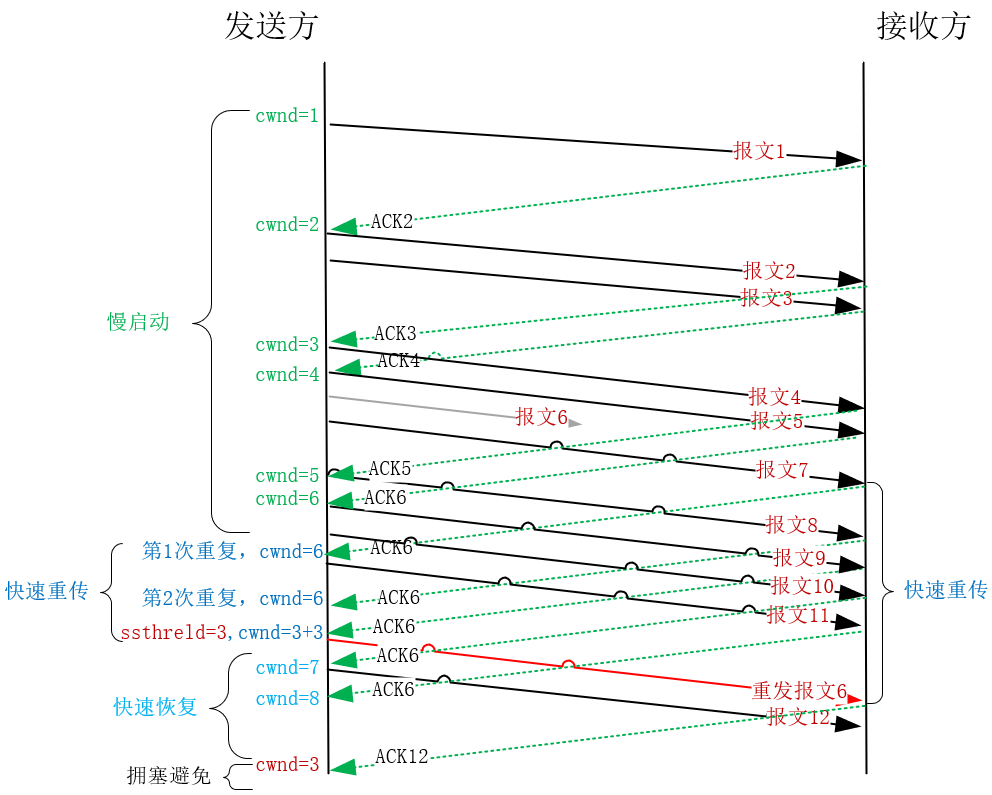
那什么是快速恢复呢?我们不妨把网络看成一个容器(上一讲中说过它可以容纳BDP字节的报文),每当接收方从网络中取出一个报文,发送方就可以增加一个报文。当发送方接收到重复ACK时,可以推断有失序报文离开了网络,到达了接收方的缓冲区,因此可以再多发送一个报文。如下图所示:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这里你要注意:第6个报文在慢启动阶段丢失,接收方收到失序的第7个报文会触发快速重传算法,它必须立刻返回ACK6。而发送方接收到第1个重复ACK6报文时,就从慢启动进入了快速重传阶段,**此刻的重复ACK不会扩大拥塞窗口。**当连续收到3个ACK6时,发送方会重发报文6,并把慢启动阈值和拥塞窗口都降到之前的一半:3个MSS,再进入快速恢复阶段。按照规则,由于收到3个重复ACK,所以拥塞窗口会增加3个MSS。之后收到的2个ACK,让拥塞窗口增加到了8个MSS,直到收到期待的ACK12,发送方才会进入拥塞避免阶段。
|
|
|
|
|
|
|
|
|
|
|
|
慢启动、拥塞避免、快速重传、快速恢复,共同构成了拥塞控制算法。Linux上提供了更改拥塞控制算法的配置,你可以通过tcp\_available\_congestion\_control配置查看内核支持的算法列表:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
net.ipv4.tcp_available_congestion_control = cubic reno
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
再通过tcp\_congestion\_control配置选择一个具体的拥塞控制算法:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
net.ipv4.tcp_congestion_control = cubic
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
但有件事你得清楚,拥塞控制是控制网络流量的算法,主机间会互相影响,在生产环境更改之前必须经过完善的测试。
|
|
|
|
|
|
|
|
|
|
|
|
## 基于测量的拥塞控制算法
|
|
|
|
|
|
|
|
|
|
|
|
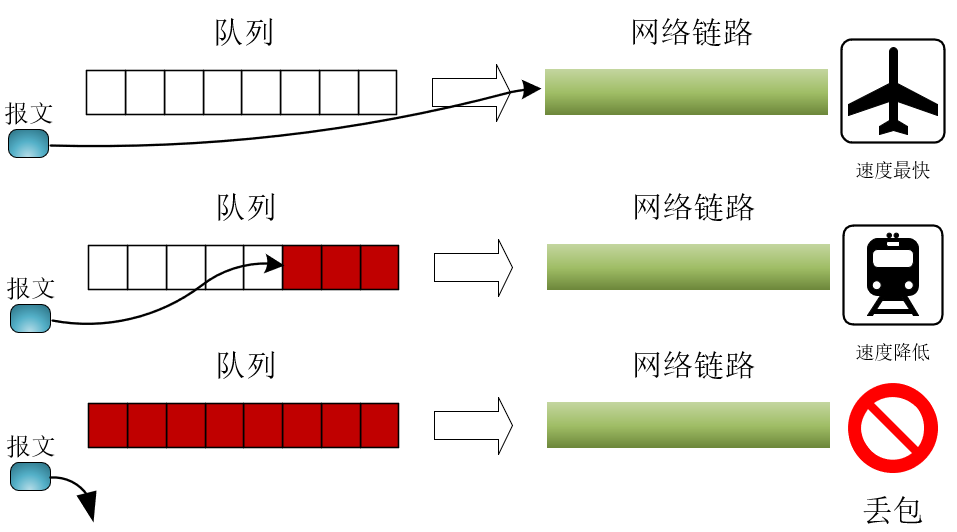
上文介绍的是传统拥塞控制算法,它是以丢包作为判断拥塞的依据。然而,网络刚出现拥塞时并不会丢包,而真的出现丢包时,拥塞已经非常严重了。如下图所示,像路由器这样的网络设备,都会有缓冲队列应对突发的、超越处理能力的流量:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
当缓冲队列为空时,传输速度最快。一旦队列开始积压,每个报文的传输时间需要增加排队时间,网速就变慢了。而当队列溢出时,才会出现丢包,基于丢包的拥塞控制算法在这个时间点进入拥塞避免阶段,显然太晚了。因为升高的网络时延降低了用户体验,而且从丢包到重发这段时间,带宽也会出现下降。
|
|
|
|
|
|
|
|
|
|
|
|
进行拥塞控制的最佳时间点,是缓冲队列刚出现积压的时刻,**此时,网络时延会增高,但带宽维持不变,这两个数值的变化可以给出明确的拥塞信号**,如下图所示:
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
这种以测量带宽、时延来确定拥塞的方法,在丢包率较高的网络中应用效果尤其好。2016年Google推出的BBR算法(全称Bottleneck Bandwidth and Round-trip propagation time),就是测量驱动的拥塞控制算法,它在YouTube站点上应用后使得网络时延下降了20%以上,传输带宽也有5%左右的提升。
|
|
|
|
|
|
|
|
|
|
|
|
当然,测量驱动的拥塞算法并没有那么简单,因为网络会波动,线路也会变化,算法必须及时地响应网络变化,这里不再展开算法细节,你可以在我的[这篇博客](https://www.taohui.pub/2019/08/07/%e4%b8%80%e6%96%87%e8%a7%a3%e9%87%8a%e6%b8%85%e6%a5%9agoogle-bbr%e6%8b%a5%e5%a1%9e%e6%8e%a7%e5%88%b6%e7%ae%97%e6%b3%95%e5%8e%9f%e7%90%86/)中找到BBR算法更详细的介绍。
|
|
|
|
|
|
|
|
|
|
|
|
Linux 4.9版本之后都支持BBR算法,开启BBR算法仍然使用tcp\_congestion\_control配置:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
net.ipv4.tcp_congestion_control=bbr
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
|
|
|
|
|
|
我们对这一讲的内容做个小结。
|
|
|
|
|
|
|
|
|
|
|
|
当TCP连接建立成功后,拥塞控制算法就会发生作用,首先进入慢启动阶段。决定连接此时网速的是初始拥塞窗口,Linux上可以通过route ip change命令修改它。通常,在带宽时延积较大的网络中,应当调高初始拥塞窗口。
|
|
|
|
|
|
|
|
|
|
|
|
丢包以及重复的ACK都是明确的拥塞信号,此时,发送方就会调低拥塞窗口减速,同时修正慢启动阈值。这样,将来再次到达这个速度时,就会自动进入拥塞避免阶段,用线性速度代替慢启动阶段的指数速度提升窗口大小。
|
|
|
|
|
|
|
|
|
|
|
|
当然,重复ACK意味着发送方可以提前重发丢失报文,快速重传算法定义了这一行为。同时,为了使得重发报文的过程中,发送速度不至于出现断崖式下降,TCP又定义了快速恢复算法,发送方在报文重新变得有序后,结束快速恢复进入拥塞避免阶段。
|
|
|
|
|
|
|
|
|
|
|
|
但以丢包作为网络拥塞的信号往往为时已晚,于是以BBR算法为代表的测量型拥塞控制算法应运而生。当飞行中报文数量不变,而网络时延升高时,就说明网络中的缓冲队列出现了积压,这是进行拥塞控制的最好时机。Linux高版本支持BBR算法,你可以通过tcp\_congestion\_control配置更改拥塞控制算法。
|
|
|
|
|
|
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
|
|
|
|
|
|
最后,请你思考下,快速恢复阶段的拥塞窗口,在报文变得有序后反而会缩小,这是为什么?欢迎你在留言区与大家一起探讨。
|
|
|
|
|
|
|
|
|
|
|
|
感谢阅读,如果你觉得这节课对你有一些启发,也欢迎把它分享给你的朋友。
|
|
|
|
|
|
|