177 lines
14 KiB
Markdown
177 lines
14 KiB
Markdown
|
|
# 加餐01 | 案例分析:怎么解决海量IPVS规则带来的网络延时抖动问题?
|
|||
|
|
|
|||
|
|
你好,我是程远。
|
|||
|
|
|
|||
|
|
今天,我们进入到了加餐专题部分。我在结束语的彩蛋里就和你说过,在这个加餐案例中,我们会用到perf、ftrace、bcc/ebpf这几个Linux调试工具,了解它们的原理,熟悉它们在调试问题的不同阶段所发挥的作用。
|
|||
|
|
|
|||
|
|
加餐内容我是这样安排的,专题的第1讲我先完整交代这个案例的背景,带你回顾我们当时整个的调试过程和思路,然后用5讲内容,对这个案例中用到的调试工具依次进行详细讲解。
|
|||
|
|
|
|||
|
|
好了,话不多说。这一讲,我们先来整体看一下这个容器网络延时的案例。
|
|||
|
|
|
|||
|
|
## 问题的背景
|
|||
|
|
|
|||
|
|
在2020年初的时候,我们的一个用户把他们的应用从虚拟机迁移到了Kubernetes平台上。迁移之后,用户发现他们的应用在容器中的出错率很高,相比在之前虚拟机上的出错率要高出一个数量级。
|
|||
|
|
|
|||
|
|
那为什么会有这么大的差别呢?我们首先分析了应用程序的出错日志,发现在Kubernetes平台上,几乎所有的出错都是因为网络超时导致的。
|
|||
|
|
|
|||
|
|
经过网络环境排查和比对测试,我们排除了网络设备上的问题,那么这个超时就只能是容器和宿主机上的问题了。
|
|||
|
|
|
|||
|
|
这里要先和你说明的是,尽管应用程序的出错率在容器中比在虚拟机里高出一个数量级,不过这个出错比例仍然是非常低的,在虚拟机中的出错率是0.001%,而在容器中的出错率是0.01%~0.04%。
|
|||
|
|
|
|||
|
|
因为这个出错率还是很低,所以对于这种低概率事件,我们想复现和排查问题,难度就很大了。
|
|||
|
|
|
|||
|
|
当时我们查看了一些日常的节点监控数据,比如CPU使用率、Load Average、内存使用、网络流量和丢包数量、磁盘I/O,发现从这些数据中都看不到任何的异常。
|
|||
|
|
|
|||
|
|
既然常规手段无效,那我们应该如何下手去调试这个问题呢?
|
|||
|
|
|
|||
|
|
你可能会想到用 **tcpdump**看一看,因为它是网络抓包最常见的工具。其实我们当时也这样想过,不过马上就被自己否定了,因为这个方法存在下面三个问题。
|
|||
|
|
|
|||
|
|
第一,我们遇到的延时问题是偶尔延时,所以需要长时间地抓取数据,这样抓取的数据量就会很大。
|
|||
|
|
|
|||
|
|
第二,在抓完数据之后,需要单独设计一套分析程序来找到长延时的数据包。
|
|||
|
|
|
|||
|
|
第三,即使我们找到了长延时的数据包,也只是从实际的数据包层面证实了问题。但是这样做无法取得新进展,也无法帮助我们发现案例中网络超时的根本原因。
|
|||
|
|
|
|||
|
|
## 调试过程
|
|||
|
|
|
|||
|
|
对于这种非常偶然的延时问题,之前我们能做的是依靠经验,去查看一些可疑点碰碰“运气”。
|
|||
|
|
|
|||
|
|
不过这一次,我们想用更加系统的方法来调试这个问题。所以接下来,我会从ebpf破冰,perf进一步定位以及用ftrace最终锁定这三个步骤,带你一步步去解决这个复杂的网络延时问题。
|
|||
|
|
|
|||
|
|
### ebpf的破冰
|
|||
|
|
|
|||
|
|
我们的想法是这样的:因为延时产生在节点上,所以可以推测,这个延时有很大的概率发生在Linux内核处理数据包的过程中。
|
|||
|
|
|
|||
|
|
沿着这个思路,还需要进一步探索。我们想到,可以给每个数据包在内核协议栈关键的函数上都打上时间戳,然后计算数据包在每两个函数之间的时间差,如果这个时间差比较大,就可以说明问题出在这两个内核函数之间。
|
|||
|
|
|
|||
|
|
要想找到内核协议栈中的关键函数,还是比较容易的。比如下面的这张示意图里,就列出了Linux内核在接收数据包和发送数据包过程中的主要函数:
|
|||
|
|
|
|||
|
|
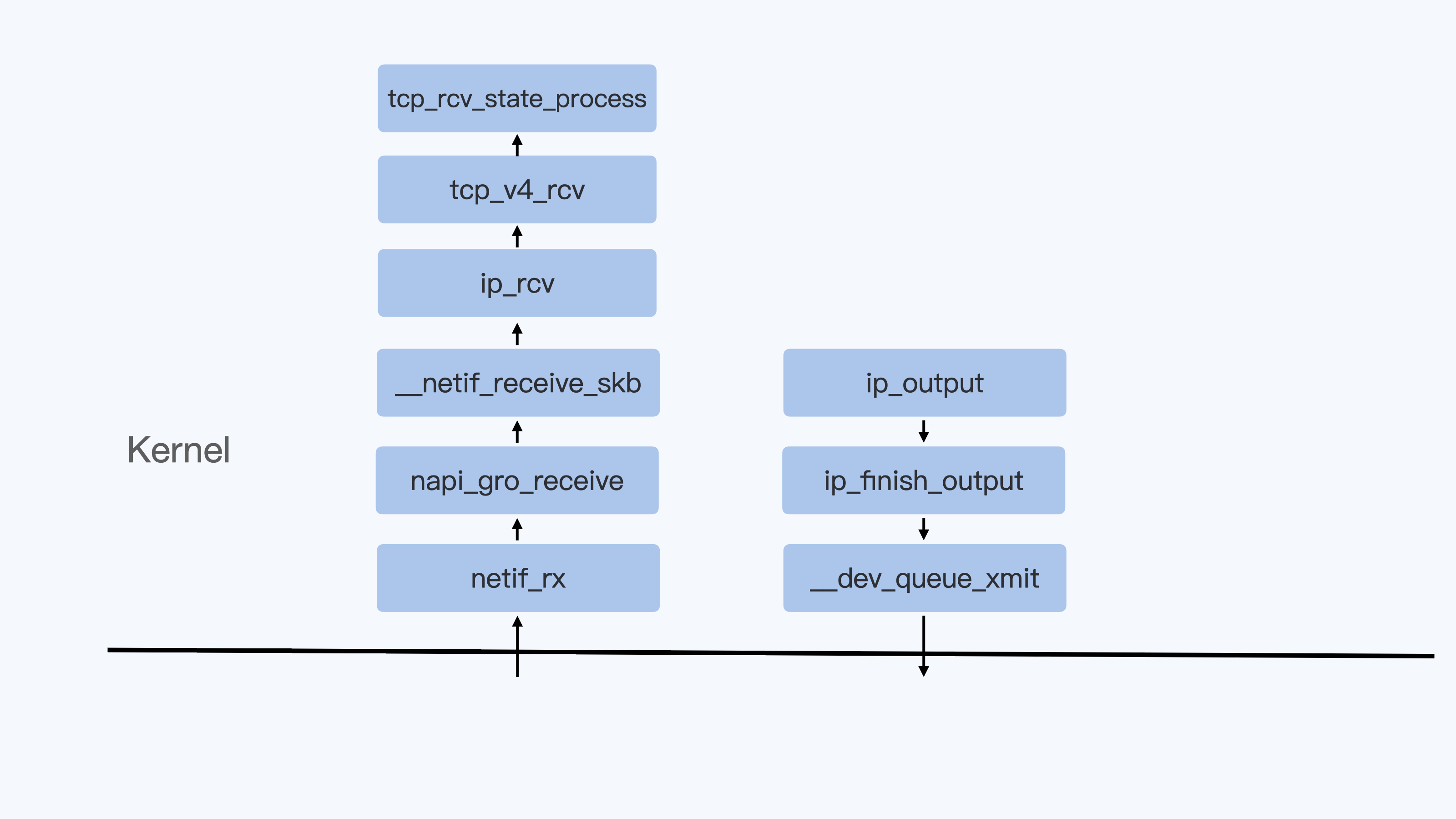
|
|||
|
|
找到这些主要函数之后,下一个问题就是,想给每个数据包在经过这些函数的时候打上时间戳做记录,应该用什么方法呢?接下来我们一起来看看。
|
|||
|
|
|
|||
|
|
在不修改内核源代码的情况,要截获内核函数,我们可以利用[kprobe](https://www.kernel.org/doc/Documentation/kprobes.txt)或者[tracepoint](https://www.kernel.org/doc/Documentation/trace/tracepoints.txt)的接口。
|
|||
|
|
|
|||
|
|
使用这两种接口的方法也有两种:一是直接写kernel module来调用kprobe或者tracepoint的接口,第二种方法是通过[ebpf](https://www.kernel.org/doc/html/latest/bpf/index.html)的接口来调用它们。在后面的课程里,我还会详细讲解ebpf、kprobe、tracepoint,这里你先有个印象就行。
|
|||
|
|
|
|||
|
|
在这里,我们选择了第二种方法,也就是使用ebpf来调用kprobe或者tracepoint接口,记录数据包处理过程中这些协议栈函数的每一次调用。
|
|||
|
|
|
|||
|
|
选择ebpf的原因主要是两个:一是ebpf的程序在内核中加载会做很严格的检查,这样在生产环境中使用比较安全;二是ebpf map功能可以方便地进行内核态与用户态的通讯,这样实现一个工具也比较容易。
|
|||
|
|
|
|||
|
|
决定了方法之后,这里我们需要先实现一个ebpf工具,然后用这个工具来对内核网络函数做trace。
|
|||
|
|
|
|||
|
|
我们工具的具体实现是这样的,针对用户的一个TCP/IP数据流,记录这个流的数据发送包与数据接收包的传输过程,也就是数据发送包从容器的Network Namespace发出,一直到它到达宿主机的eth0的全过程,以及数据接收包从宿主机的eth0返回到容器Network Namespace的eth0的全程。
|
|||
|
|
|
|||
|
|
在收集了数十万条记录后,我们对数据做了分析,找出前后两步时间差大于50毫秒(ms)的记录。最后,我们终于发现了下面这段记录:
|
|||
|
|
|
|||
|
|
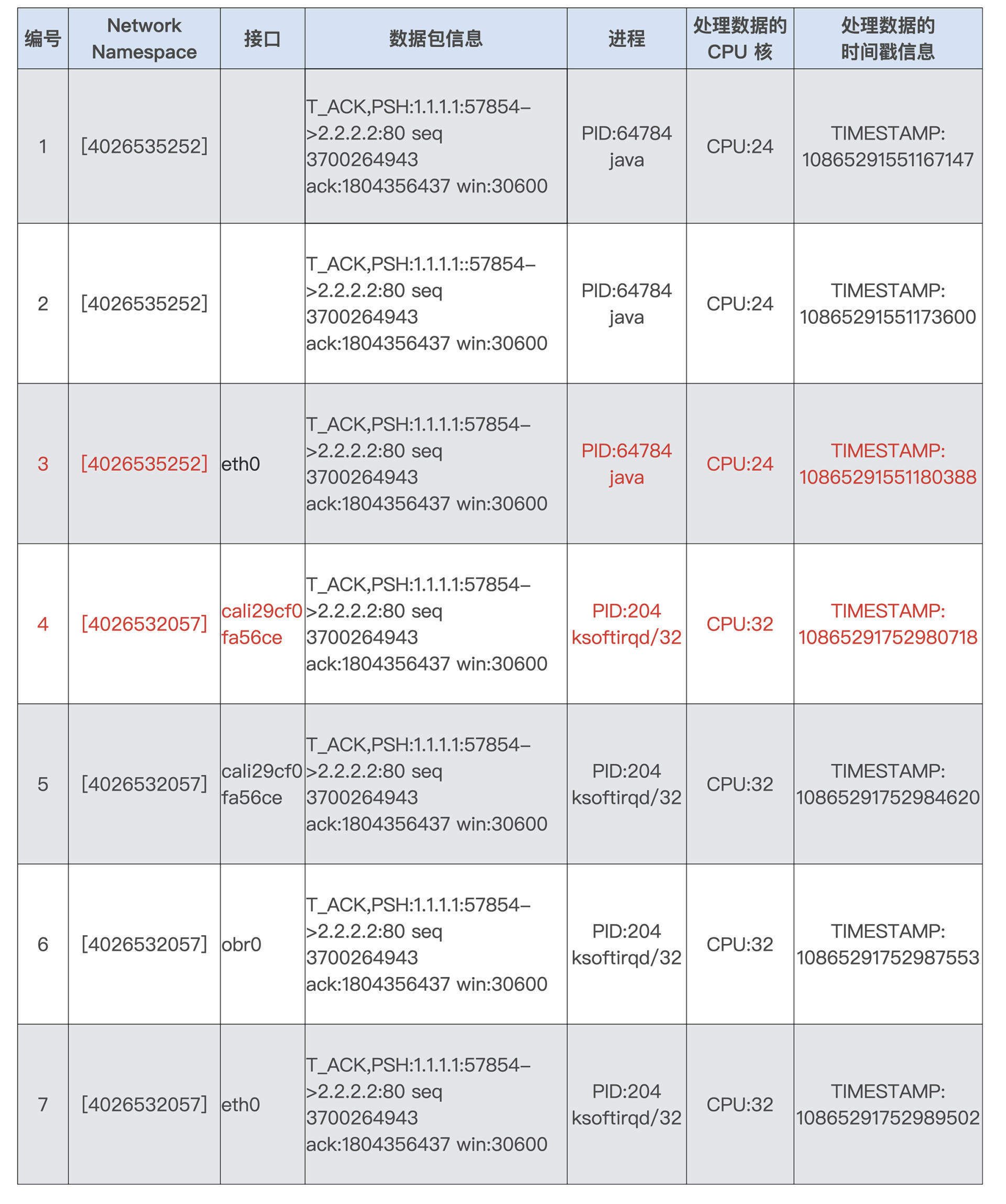
|
|||
|
|
|
|||
|
|
在这段记录中,我们先看一下“Network Namespace”这一列。编号3对应的Namespace ID 4026535252是容器里的,而ID4026532057是宿主机上的Host Namespace。
|
|||
|
|
|
|||
|
|
数据包从1到7的数据表示了,一个数据包从容器里的eth0通过veth发到宿主机上的peer veth cali29cf0fa56ce,然后再通过路由从宿主机的obr0(openvswitch)接口和eth0接口发出。
|
|||
|
|
|
|||
|
|
为了方便你理解,我在下面画了一张示意图,描述了这个数据包的传输过程:
|
|||
|
|
|
|||
|
|
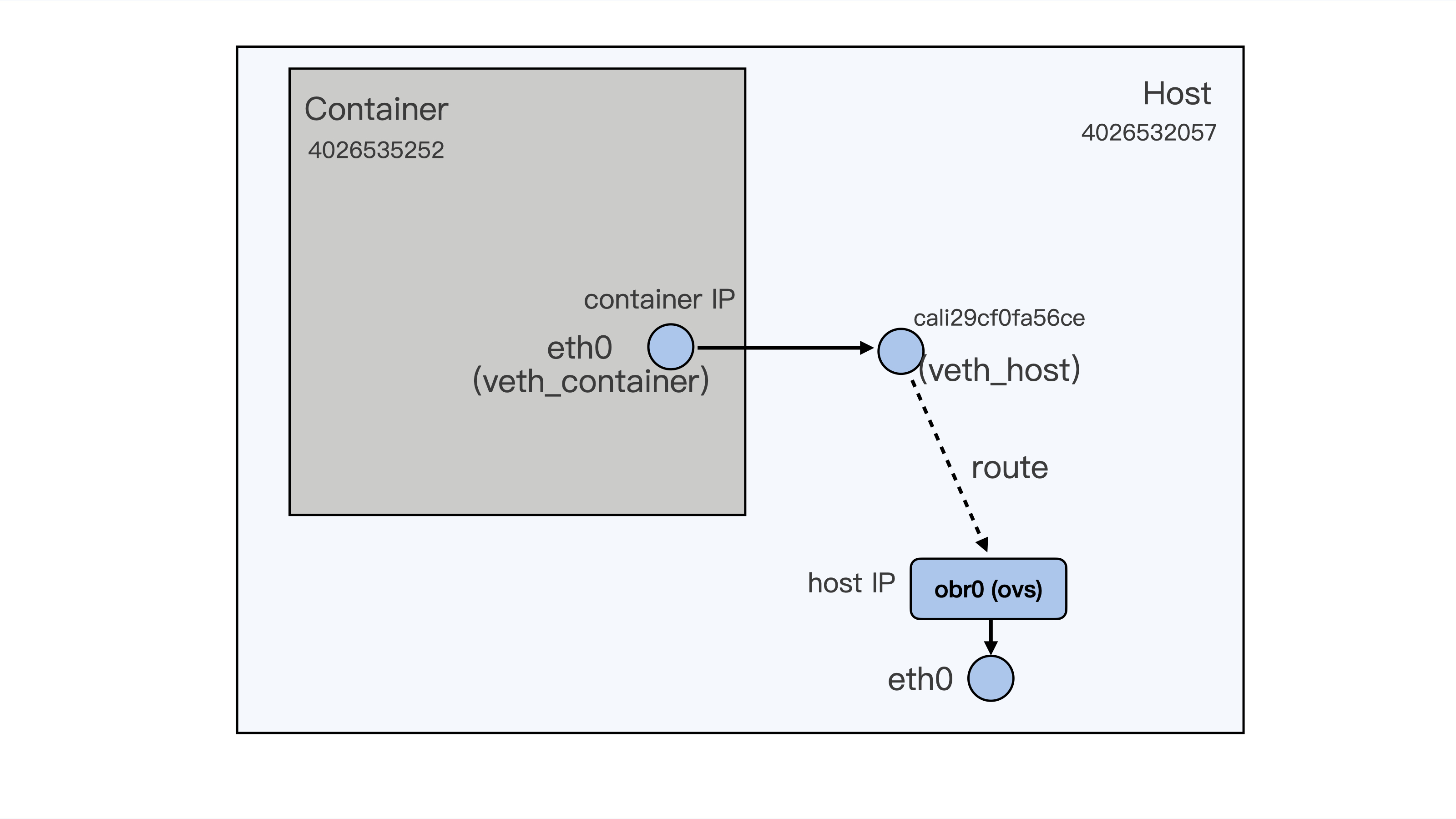
|
|||
|
|
|
|||
|
|
在这个过程里,我们发现了当数据包从容器的eth0发送到宿主机上的cali29cf0fa56ce,也就是从第3步到第4步之间,花费的时间是10865291752980718-10865291551180388=201800330。
|
|||
|
|
|
|||
|
|
因为时间戳的单位是纳秒ns,而201800330超过了200毫秒(ms),这个时间显然是不正常的。
|
|||
|
|
|
|||
|
|
你还记得吗?我们在容器网络模块的[第17讲](https://time.geekbang.org/column/article/324122)说过veth pair之间数据的发送,它会触发一个softirq,并且在我们ebpf的记录中也可以看到,当数据包到达cali29cf0fa56ce后,就是softirqd进程在CPU32上对它做处理。
|
|||
|
|
|
|||
|
|
那么这时候,我们就可以把关注点放到CPU32的softirq处理上了。我们再仔细看看CPU32上的si(softirq)的CPU使用情况(运行top命令之后再按一下数字键1,就可以列出每个CPU的使用率了),会发现在CPU32上时不时出现si CPU使用率超过20%的现象。
|
|||
|
|
|
|||
|
|
具体的输出情况如下:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
%Cpu32 : 8.7 us, 0.0 sy, 0.0 ni, 62.1 id, 0.0 wa, 0.0 hi, 29.1 si, 0.0 st
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
其实刚才说的这点,在最初的节点监控数据上,我们是不容易注意到的。这是因为我们的节点上有80个CPU,单个CPUsi偶尔超过20%,平均到80个CPU上就只有 0.25%了。要知道,对于一个普通节点,1%的si使用率都是很正常的。
|
|||
|
|
|
|||
|
|
好了,到这里我们已经缩小了问题的排查范围。可以看到,使用了ebpf帮助我们在毫无头绪的情况,找到了一个比较明确的方向。那么下一步,我们自然要顺藤摸瓜,进一步去搞清楚,为什么在CPU32上的softirq CPU使用率会时不时突然增高?
|
|||
|
|
|
|||
|
|
### perf 定位热点
|
|||
|
|
|
|||
|
|
对于查找高CPU使用率情况下的热点函数,perf显然是最有力的工具。我们只需要执行一下后面的这条命令,看一下CPU32上的函数调用的热度。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
# perf record -C 32 -g -- sleep 10
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
为了方便查看,我们可以把 `perf record` 输出的结果做成一个火焰图,具体的方法我在下一讲里介绍,这里你需要先理解定位热点的整体思路。
|
|||
|
|
|
|||
|
|
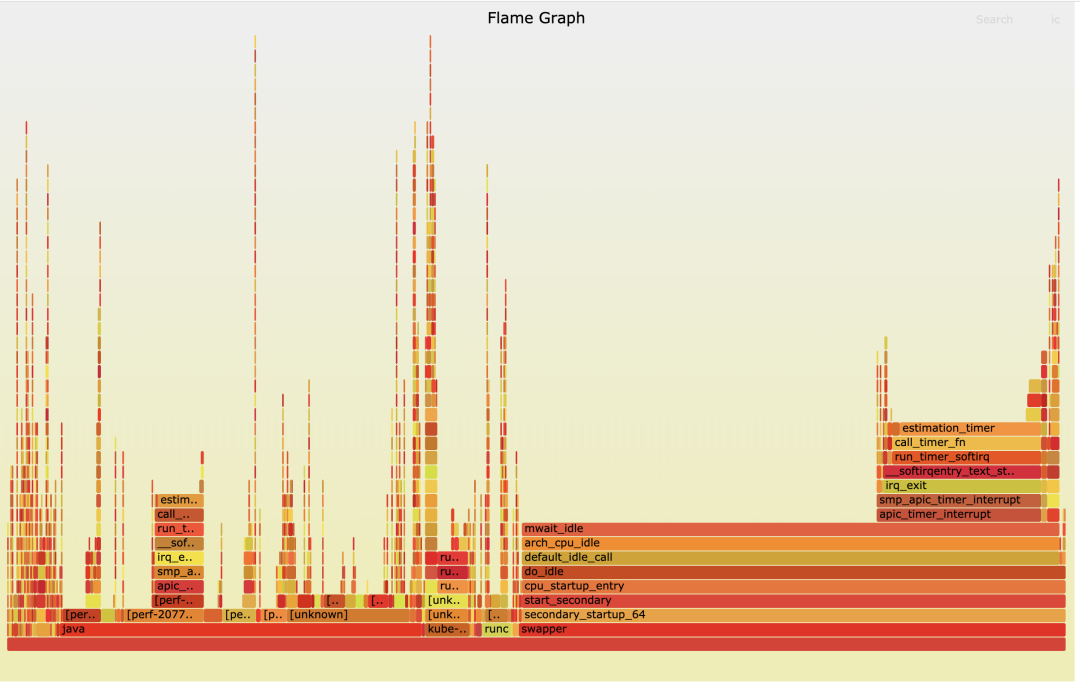
|
|||
|
|
|
|||
|
|
结合前面的数据分析,我们已经知道了问题出现在softirq的处理过程中,那么在查看火焰图的时候,就要特别关注在softirq中被调用到的函数。
|
|||
|
|
|
|||
|
|
从上面这张图里,我们可以看到,run\_timer\_softirq所占的比例是比较大的,而在run\_timer\_softirq中的绝大部分比例又是被一个叫作estimation\_timer()的函数所占用的。
|
|||
|
|
|
|||
|
|
运行完perf之后,我们离真相又近了一步。现在,我们知道了CPU32上softirq的繁忙是因为TIMER softirq引起的,而TIMER softirq里又在不断地调用 **estimation\_timer() 这个函数**。
|
|||
|
|
|
|||
|
|
沿着这个思路继续分析,对于TIMER softirq的高占比,一般有这两种情况,一是softirq发生的频率很高,二是softirq中的函数执行的时间很长。
|
|||
|
|
|
|||
|
|
那怎么判断具体是哪种情况呢?我们用/proc/softirqs查看CPU32上TIMER softirq每秒钟的次数,就会发现TIMER softirq在CPU32上的频率其实并不高。
|
|||
|
|
|
|||
|
|
这样第一种情况就排除了,那我们下面就来看看,Timer softirq中的那个函数estimation\_timer(),是不是它的执行时间太长了?
|
|||
|
|
|
|||
|
|
### ftrace 锁定长延时函数
|
|||
|
|
|
|||
|
|
我们怎样才能得到estimation\_timer()函数的执行时间呢?
|
|||
|
|
|
|||
|
|
你还记得,我们在容器I/O与内存[那一讲](https://time.geekbang.org/column/article/321330)里用过的[ftrace](https://www.kernel.org/doc/Documentation/trace/ftrace.txt)么?当时我们把ftrace的tracer设置为function\_graph,通过这个办法查看内核函数的调用时间。在这里我们也可以用同样的方法,查看estimation\_timer()的调用时间。
|
|||
|
|
|
|||
|
|
这时候,我们会发现在CPU32上的estimation\_timer()这个函数每次被调用的时间都特别长,比如下面图里的记录,可以看到CPU32上的时间高达310毫秒!
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
现在,我们可以确定问题就出在estimation\_timer()这个函数里了。
|
|||
|
|
|
|||
|
|
接下来,我们需要读一下estimation\_timer()在内核中的源代码,看看这个函数到底是干什么的,它为什么耗费了这么长的时间。其实定位到这一步,后面的工作就比较容易了。
|
|||
|
|
|
|||
|
|
estimation\_timer()是[IPVS](http://www.linuxvirtualserver.org/software/ipvs.html)模块中每隔2秒钟就要调用的一个函数,它主要用来更新节点上每一条IPVS规则的状态。Kubernetes Cluster里每建一个service,在所有的节点上都会为这个service建立相应的IPVS规则。
|
|||
|
|
|
|||
|
|
通过下面这条命令,我们可以看到节点上IPVS规则的数目:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
# ipvsadm -L -n | wc -l
|
|||
|
|
79004
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们的节点上已经建立了将近80K条IPVS规则,而estimation\_timer()每次都需要遍历所有的规则来更新状态,这样就导致estimation\_timer()函数时间开销需要上百毫秒。
|
|||
|
|
|
|||
|
|
我们还有最后一个问题,estimation\_timer()是TIMER softirq里执行的函数,那它为什么会影响到网络RX softirq的延时呢?
|
|||
|
|
|
|||
|
|
这个问题,我们只要看一下softirq的处理函数[\_\_do\_softirq()](https://github.com/torvalds/linux/blob/219d54332a09e8d8741c1e1982f5eae56099de85/kernel/softirq.c#L280),就会明白了。因为在同一个CPU上,\_\_do\_softirq()会串行执行每一种类型的softirq,所以TIMER softirq执行的时间长了,自然会影响到下一个RX softirq的执行。
|
|||
|
|
|
|||
|
|
好了,分析这里,这个网络延时问题产生的原因我们已经完全弄清楚了。接下来,我带你系统梳理一下这个问题的解决思路。
|
|||
|
|
|
|||
|
|
## 问题小结
|
|||
|
|
|
|||
|
|
首先回顾一下今天这一讲的问题,我们分析了一个在容器平台的生产环境中,用户的应用程序网络延时的问题。这个延时只是偶尔发生,并且出错率只有0.01%~0.04%,所以我们从常规的监控数据中无法看到任何异常。
|
|||
|
|
|
|||
|
|
那调试这个问题该如何下手呢?
|
|||
|
|
|
|||
|
|
我们想到的方法是使用ebpf调用kprobe/tracepoint的接口,这样就可以追踪数据包在内核协议栈主要函数中花费的时间。
|
|||
|
|
|
|||
|
|
我们实现了一个ebpf工具,并且用它缩小了排查范围,我们发现当数据包从容器的veth接口发送到宿主机上的veth接口,在某个CPU上的softirq的处理会有很长的延时。并且由此发现了,在对应的CPU上si的CPU使用率时不时会超过20%。
|
|||
|
|
|
|||
|
|
找到了这个突破口之后,我们用perf工具专门查找了这个CPU上的热点函数,发现TIMER softirq中调用estimation\_timer()的占比是比较高的。
|
|||
|
|
|
|||
|
|
接下来,我们使用ftrace进一步确认了,在这个特定CPU上estimation\_timer()所花费的时间需要几百毫秒。
|
|||
|
|
|
|||
|
|
通过这些步骤,我们最终锁定了问题出在IPVS的这个estimation\_timer()函数里,也找到了问题的根本原因:**在我们的节点上存在大量的IPVS规则,每次遍历这些规则都会消耗很多时间,最终导致了网络超时现象。**
|
|||
|
|
|
|||
|
|
知道了原因之后,因为我们在生产环境中并不需要读取IPVS规则状态,所以为了快速解决生产环境上的问题,我们可以使用内核[livepatch](https://www.kernel.org/doc/html/latest/livepatch/livepatch.html)的机制在线地把estimation\_timer()函数替换成了一个空函数。
|
|||
|
|
|
|||
|
|
这样,我们就暂时规避了因为estimation\_timer()耗时长而影响其他softirq的问题。至于长期的解决方案,我们可以把IPVS规则的状态统计从TIMER softirq中转移到kernel thread中处理。
|
|||
|
|
|
|||
|
|
## 思考题
|
|||
|
|
|
|||
|
|
如果不使用ebpf工具,你还有什么方法来找到这个问题的突破口呢?
|
|||
|
|
|
|||
|
|
欢迎你在留言区和我交流讨论。如果这一讲的内容对你有帮助的话,也欢迎转发给你的朋友、同事,和他一起学习进步。
|
|||
|
|
|