312 lines
19 KiB
Markdown
312 lines
19 KiB
Markdown
|
|
# 24|UUID:如何高效生成全局的唯一ID?
|
|||
|
|
|
|||
|
|
你好,我是微扰君。
|
|||
|
|
|
|||
|
|
今天我们来聊一聊在生产环境中非常常用的一个算法——全局唯一ID生成算法,也就是我们通常说的UUID。
|
|||
|
|
|
|||
|
|
就和我们在社会中都有自己的身份证号作为自己的唯一标示一样,在互联网的应用中,很多时候,我们需要能生成一个全局唯一的ID,去区别不同业务场景下的不同数据,比如消息ID、用户ID、微博内容ID等等。
|
|||
|
|
|
|||
|
|
因为我们往往**需要通过这个ID去索引某个业务数据,所以一定要保证生成的ID在全局范围内是唯一的**,这也是identifier的本意,在部分情况下,冲突概率很小可能也是可以接受的。另外,这个ID通常需要按照某种规则有序排列,最常用的就是基于时间进行排序。
|
|||
|
|
|
|||
|
|
所以全局唯一ID的两个核心需求就是:
|
|||
|
|
|
|||
|
|
1. 全局唯一性
|
|||
|
|
2. 粗略有序性
|
|||
|
|
|
|||
|
|
那业界是如何生成满足这两大需求的ID,又有哪些方案呢?我们开始今天的学习。
|
|||
|
|
|
|||
|
|
### 单体环境
|
|||
|
|
|
|||
|
|
在单体的应用中,保证ID的全局唯一,其实不是一个很大的问题,我们只需要提供一个在内存中的计数器,就可以完成对ID的颁发。
|
|||
|
|
|
|||
|
|
当然这样的ID可能会带有明确的含义,并被暴露出去了,比如在票务系统中,如果这样设计,我们能根据电子票ID判断出自己买的是第几张票。这对安全性要求更高的业务来说,是不可接受的,但通过一些简单的加密算法混淆,我们就能解决这个问题。
|
|||
|
|
|
|||
|
|
总的来说,单节点的应用,因为所有产生新业务数据,而需要产生新ID的地方,都是同一个地方,复杂性是很可控的。
|
|||
|
|
|
|||
|
|
### 分布式环境
|
|||
|
|
|
|||
|
|
但在现在的分布式环境下,每一个简单的问题都变得更复杂了一些,我们来举一个具体的例子。
|
|||
|
|
|
|||
|
|
假设,现在有一个票务系统,每次出票请求的产生,都会产生一个对应的电子票ID,毫无疑问这个ID需要是全局唯一的,否则会出现多个同学的票无法区分的情况。那假设我们的出票服务TPS比较高,**为了同时让多台服务器都可以颁发不重复的ID,我们自然需要一种机制进行多台服务器之间的协调或者分配**。
|
|||
|
|
|
|||
|
|
这个问题其实历史已久,解决方法也已经有很多了,我们一起来看看主流的解决方案是如何考虑的。
|
|||
|
|
|
|||
|
|
## 引入单点ID生成器
|
|||
|
|
|
|||
|
|
先来看一个最简单的,也非常容易DIY的思路——单点ID生成器。
|
|||
|
|
|
|||
|
|
通过这个方案,我们可以快速了解这个问题的解决思路,在接下来学习的过程中,你也可以边看边思考,对于这个全局唯一ID的生成,你有什么更好的改进主意。
|
|||
|
|
|
|||
|
|
我们在前面说了,单机里生成ID不是一个问题,**在多节点中,我们仍然可以尝试自己手动打造一个单点的ID生成器,通常可以是一个独立部署的服务**,这样的服务,我们一般也称为 ID generate service。
|
|||
|
|
|
|||
|
|
也就是说,所有其他需要生成ID的服务,在需要生成ID的时候都不自己生成,而是全部访问这个单点的服务。因为单点的服务只有一台机器,我们很容易通过本地时钟和计数器来保证ID的唯一性和有序性。
|
|||
|
|
|
|||
|
|
当然这里要重点注意的是,我们必须要能应对时钟回拨,或者服务器异常重启之后计数器不会重复的问题。
|
|||
|
|
|
|||
|
|
### 如何解决
|
|||
|
|
|
|||
|
|
首先看第一个问题:时钟为什么会回拨呢?
|
|||
|
|
|
|||
|
|
如果你了解计算机如何计时的话就知道,计算机底层的计时主要依靠石英钟,它本身是有一定误差,所以计算机会定期地通过NTP服务,来同步更加接近真实时间的时间(仍然有一定的误差),这个时候就可能会产生时钟的一些跳跃。这里我们就不展开讲了,感兴趣的话。你可以自己去搜索一下NTP协议了解。
|
|||
|
|
|
|||
|
|
真正影响更大的问题其实是第二个,**如果计数器只是在内存中保存,一旦发生机器故障或者断电等情况,我们就无法知道之前的ID生成到什么位置了**,怎么办?
|
|||
|
|
|
|||
|
|
我们需要想办法有一定的持久化机制,也需要有一定的容灾备份的机制,要考虑的问题还是不少的。比如,对于单点服务挂了的情况下,首先想到可以用之前讲Raft和MapReduce的时候也提到过类似的提供一个备用服务的方案,来提高整个服务的高可用性,但这样,备用服务和主服务之间又如何同步状态,又成了新的问题,所以我们往往需要引入数据库等外部组件来解决。
|
|||
|
|
|
|||
|
|
哪怕解决了这两大问题,就这个设计本身来说,单点服务的一大限制是**性能不佳,如果每个请求都需要将状态持久化一下,并发量很容易遇到瓶颈**。
|
|||
|
|
|
|||
|
|
所以这种方案在实际生产中并不常用,具体实现就留给你做课后的思考题,你可以想想,不借助任何外部组件,自己如何独立实现一个单点的ID生成器服务。
|
|||
|
|
|
|||
|
|
## 基于数据库实现ID生成器
|
|||
|
|
|
|||
|
|
好我们继续想,既然直接自己写还是有许多问题需要考虑,那能不能利用现有的组件来实现呢?
|
|||
|
|
|
|||
|
|
我首先想到的方案就是数据库,还记得数据库中的主键吗,我们往往可以把主键设置成auto\_increment,这样在往数据库里插入一个元素的时候,就不需要我们提供ID,而是数据库自动给我们生成一个呢?而且有了auto\_increment,我们也自然能保证字段的有序性。
|
|||
|
|
|
|||
|
|
其实这正是天然的全局ID生成器。利用了外部组件自身的能力,我们基于数据库自增ID直接实现的ID generate非常简单,既可以保证唯一性,也可以保证有序性,ID的步长也是可调的;而且数据库本身有非常好的可用性,能解决了我们对服务可靠性的顾虑。
|
|||
|
|
|
|||
|
|
但是同样有一个很大的限制,单点数据库的写入性能可能不是特别好,作为ID生成器,可能成为整个系统的性能瓶颈。
|
|||
|
|
|
|||
|
|
如何优化呢?我们一起来想一想。
|
|||
|
|
|
|||
|
|
### 水平扩展
|
|||
|
|
|
|||
|
|
既然单点写性能不高,我们如果扩展多个库,平均分摊流量是不是就可以了呢?这也是非常常用的提高系统吞吐量的办法。接下来的问题就是,多个库之间如何分配ID呢?
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
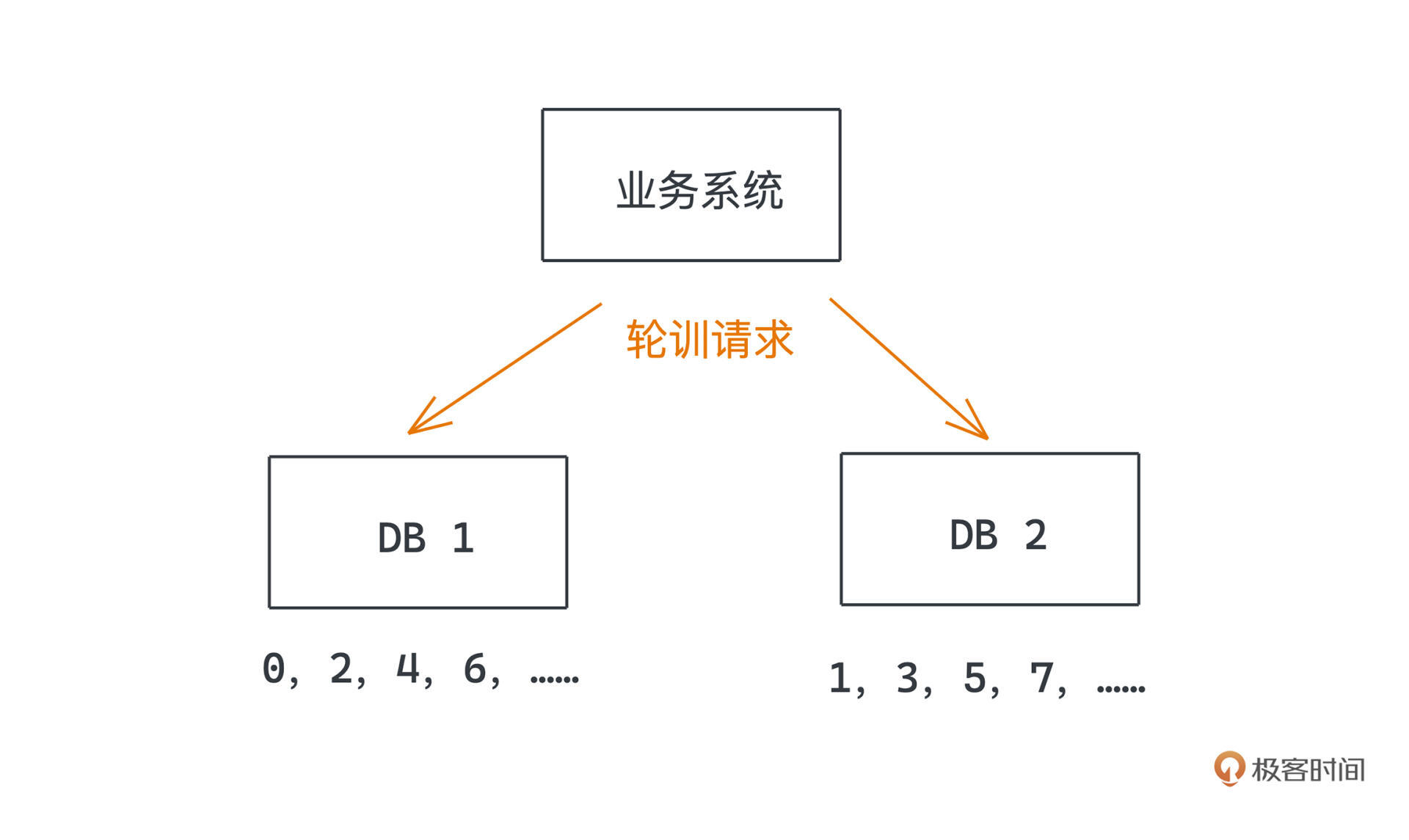
为了让每个库都能有独立的ID范围不至于产生冲突,我们可以为它们设置比数据库数量更高的值,作为auto\_increment的步长,而且每个库采用不同的初始值,这样自然就可以保证每个库所能分配的ID是错开的。比如两个数据库,一个持有所有偶数ID,一个持有所有奇数ID。其他业务系统只需要轮询两个数据库,就可以得到粗略有序的全局唯一ID了。
|
|||
|
|
|
|||
|
|
为什么只是粗略有序,因为我们没办法保证所有依赖于此的服务,能按照时序轮流访问多个服务,但随着时间推移,只要负载均衡算法比较合理,整体ID还是在递增的。
|
|||
|
|
|
|||
|
|
但这样的系统也往往有一个问题:一旦数据库的数量定好了,就不太好再随意增加,必须重新划分每个数据库的初始值和步长。不过通常来说,这个问题也比较好处理,可以一开始就根据业务规模,设置足够多个数据库作为ID生成器,来避免扩展的需要。
|
|||
|
|
|
|||
|
|
但是如果直接用数据库来产生序号,会面临数据库写入瓶颈的问题。不过估计你也想到了刚才单点服务的思路,**如果我们把生成ID的响应服务和存储服务拆开,还是用单点对外提供ID发生服务,但是将ID状态记录在数据库中呢**?两者结合应该能获得更好的效果。
|
|||
|
|
|
|||
|
|
### 利用单点服务
|
|||
|
|
|
|||
|
|
具体做法就是在需要产生新的全局ID的时候,每次单点服务都向数据库批量申请n个ID,在本地用内存维护这个号段,并把数据库中的ID修改为当前值+n,直到这n个ID被耗尽;下次需要产生新的全局ID的时候,再次到数据库申请一段新的号段。
|
|||
|
|
|
|||
|
|
如果ID被耗尽之前,单点服务就挂了,也没关系,我们重启的时候直接向数据库申请下一次批次的ID就行,最多也就导致继续生成的ID和之前的批次不连续,这在大部分场景中都是可以接受的。
|
|||
|
|
|
|||
|
|
这样批量处理的设计,能大大减少数据库写的次数,把压力变成了原来的1/n,性能大大提升,往往可以承载10w级的QPS。这也是非常常见的减少服务压力的策略。
|
|||
|
|
|
|||
|
|
## UUID
|
|||
|
|
|
|||
|
|
UUID(universally unique identifier) 这个词我们一开始就提到了,相信你不会很陌生,它本身就可以翻译成全局唯一ID,但同时它也是一种常见的生成全局唯一ID的算法和协议。
|
|||
|
|
|
|||
|
|
和前面我们思考的两种方案不同,**这次的ID不再需要通过远程调用一个独立的服务产生,而是直接在业务侧的服务本地产生,所以UUID通常也被实现为一个库,供业务方直接调用**。UUID有很多个不同的版本,网络上不同库的实现也可能会略有区别。
|
|||
|
|
|
|||
|
|
UUID一共包含32位16进制数,也就是相当于128位二进制数,显示的时候被分为8-4-4-4-12几个部分,看一个例子:
|
|||
|
|
|
|||
|
|
```scala
|
|||
|
|
0725f9ac-8cc1-11ec-a8a3-0242ac120002
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们就用JDK中自带的UUID,来讲解一下第三和第四个版本的使用和主要思想,背后的逻辑主要是一些复杂的位运算,解释起来比较麻烦,对我们实际业务开发帮助不大,你感兴趣的话可以自己去看看相关的[源代码](https://developer.classpath.org/doc/java/util/UUID-source.html)。
|
|||
|
|
|
|||
|
|
第三个版本的方法是基于名字计算的,名字由用户传入,它保证了不同空间不同名字下的UUID都具有唯一性,而相同空间相同名字下的UUID则是相同的:
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
public static UUID nameUUIDFromBytes(byte[] name)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
name是用户自行传入的一段二进制,UUID包会对其进行MD5计算以及一些位运算,最终得到一个UUID。
|
|||
|
|
|
|||
|
|
第四个版本更加常用也更加直接一点,就是直接基于随机性进行计算,因为UUID非常长,所以其重复概率可以忽略不计。
|
|||
|
|
|
|||
|
|
```plain
|
|||
|
|
public static UUID nameUUIDFromBytes(byte[] name)
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
两个版本的使用都很简单:
|
|||
|
|
|
|||
|
|
```scala
|
|||
|
|
UUID uuid = UUID.randomUUID();
|
|||
|
|
UUID uuid_ = UUID.nameUUIDFromBytes(nbyte);
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
但UUID过于冗长,且主流版本完全无序,对数据库存储非常不利,这点我们之后介绍B+树的时候也会展开讨论。
|
|||
|
|
|
|||
|
|
## Snowflake
|
|||
|
|
|
|||
|
|
除了用户自己传入name来计算UUID,UUID其他几个版本里也有用到MAC地址,利用全球唯一性来标识不同的机器以及利用时间来保证有序性。不过Mac地址属于用户隐私,暴露出去不太好,也没有被广泛使用,但是思想还是可以被借鉴的。
|
|||
|
|
|
|||
|
|
**Snowflake就是这样一种引入了机器编号和时间信息的分布式ID生成算法**,也是由业务方本地执行,由twitter开源,国内的美团和百度也都开源了基于各自业务场景的类似算法,感兴趣的同学可以搜索leaf和UUID-generator,性能都很不错。
|
|||
|
|
|
|||
|
|
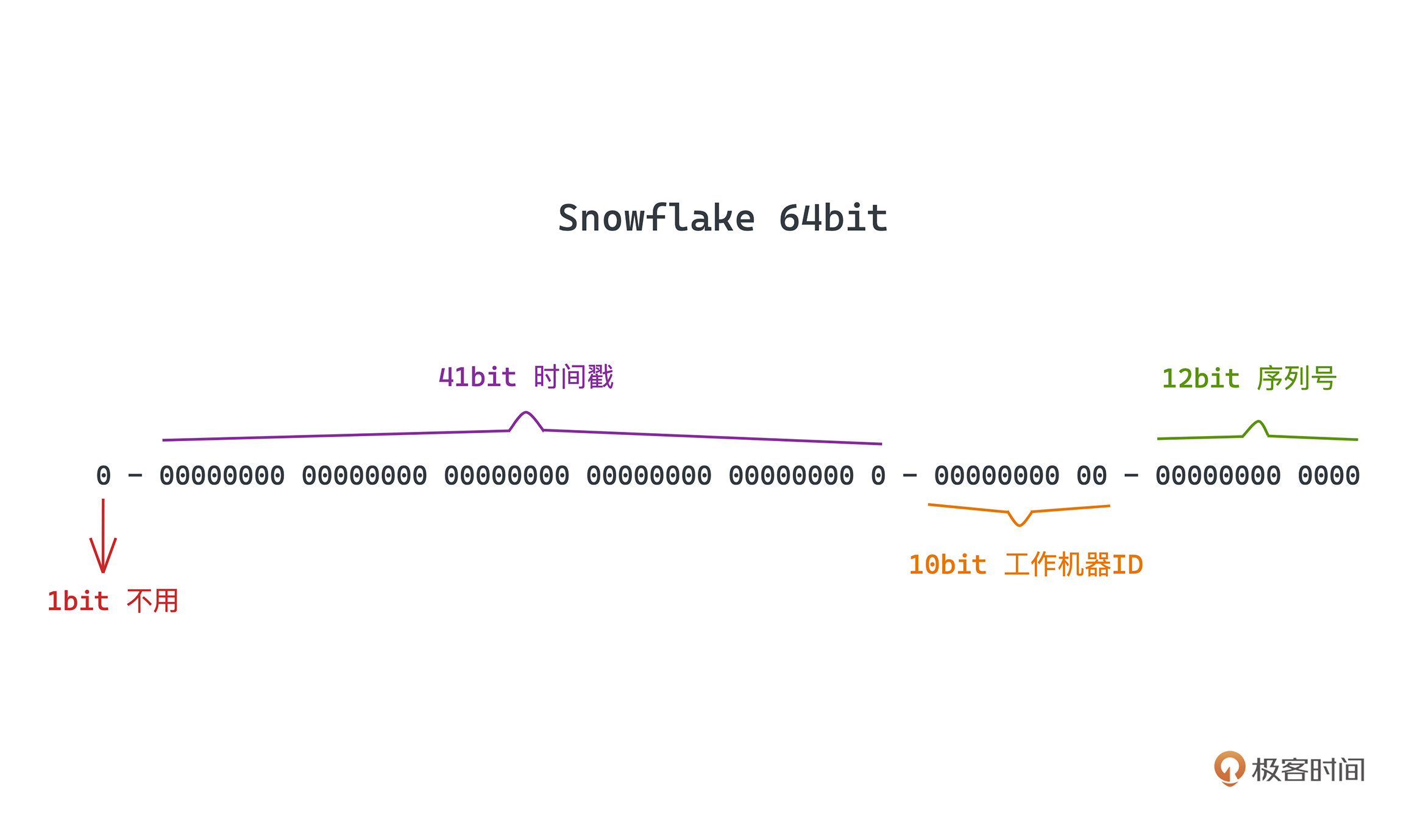
整个Snowflake生成的UUID都是64位的长整型,分为四个部分。
|
|||
|
|
|
|||
|
|
|
|||
|
|
* 第一位是位保留位,置0。
|
|||
|
|
* 后面连续41位存储时间戳,可到毫秒级精度。
|
|||
|
|
* 再后面10位代表机器ID,由用户指定,相当于最多可以支持1024台机器。
|
|||
|
|
* 最后12位表示序列号,是一个自增的序号,在时间相同的情况下,也就是1ms内可以支持4096个不同的序号,也就是在理论上来说Snowflake每秒可以产生400w+个序号,这对于大部分业务场景来说都是绰绰有余的了。
|
|||
|
|
|
|||
|
|
Twitter官方开源的版本是用Scala写的(网上也有人翻译了一个[Java版本](https://github.com/callicoder/java-snowflake/blob/master/src/main/java/com/callicoder/snowflake/Snowflake.java)),因为思路其实很简单,所以代码也非常简洁,我这里写了点简单的注释,供你参考:
|
|||
|
|
|
|||
|
|
```scala
|
|||
|
|
package com.callicoder.snowflake;
|
|||
|
|
|
|||
|
|
import java.net.NetworkInterface;
|
|||
|
|
import java.security.SecureRandom;
|
|||
|
|
import java.time.Instant;
|
|||
|
|
import java.util.Enumeration;
|
|||
|
|
|
|||
|
|
/**
|
|||
|
|
* Distributed Sequence Generator.
|
|||
|
|
* Inspired by Twitter snowflake: https://github.com/twitter/snowflake/tree/snowflake-2010
|
|||
|
|
*
|
|||
|
|
* This class should be used as a Singleton.
|
|||
|
|
* Make sure that you create and reuse a Single instance of Snowflake per node in your distributed system cluster.
|
|||
|
|
*/
|
|||
|
|
public class Snowflake {
|
|||
|
|
private static final int UNUSED_BITS = 1; // Sign bit, Unused (always set to 0)
|
|||
|
|
private static final int EPOCH_BITS = 41;
|
|||
|
|
private static final int NODE_ID_BITS = 10;
|
|||
|
|
private static final int SEQUENCE_BITS = 12;
|
|||
|
|
|
|||
|
|
private static final long maxNodeId = (1L << NODE_ID_BITS) - 1;
|
|||
|
|
private static final long maxSequence = (1L << SEQUENCE_BITS) - 1;
|
|||
|
|
|
|||
|
|
// Custom Epoch (January 1, 2015 Midnight UTC = 2015-01-01T00:00:00Z)
|
|||
|
|
private static final long DEFAULT_CUSTOM_EPOCH = 1420070400000L;
|
|||
|
|
|
|||
|
|
private final long nodeId;
|
|||
|
|
private final long customEpoch;
|
|||
|
|
|
|||
|
|
private volatile long lastTimestamp = -1L;
|
|||
|
|
private volatile long sequence = 0L;
|
|||
|
|
|
|||
|
|
// Create Snowflake with a nodeId and custom epoch
|
|||
|
|
// 初始化需要传入节点ID和年代
|
|||
|
|
public Snowflake(long nodeId, long customEpoch) {
|
|||
|
|
if(nodeId < 0 || nodeId > maxNodeId) {
|
|||
|
|
throw new IllegalArgumentException(String.format("NodeId must be between %d and %d", 0, maxNodeId));
|
|||
|
|
}
|
|||
|
|
this.nodeId = nodeId;
|
|||
|
|
this.customEpoch = customEpoch;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// Create Snowflake with a nodeId
|
|||
|
|
public Snowflake(long nodeId) {
|
|||
|
|
this(nodeId, DEFAULT_CUSTOM_EPOCH);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// Let Snowflake generate a nodeId
|
|||
|
|
public Snowflake() {
|
|||
|
|
this.nodeId = createNodeId();
|
|||
|
|
this.customEpoch = DEFAULT_CUSTOM_EPOCH;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// 这个函数用于获取下一个ID
|
|||
|
|
public synchronized long nextId() {
|
|||
|
|
long currentTimestamp = timestamp();
|
|||
|
|
|
|||
|
|
if(currentTimestamp < lastTimestamp) {
|
|||
|
|
throw new IllegalStateException("Invalid System Clock!");
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// 同一个时间戳,我们需要递增序号
|
|||
|
|
if (currentTimestamp == lastTimestamp) {
|
|||
|
|
sequence = (sequence + 1) & maxSequence;
|
|||
|
|
if(sequence == 0) {
|
|||
|
|
// 如果序号耗尽,则需要等待到下一秒继续执行
|
|||
|
|
// Sequence Exhausted, wait till next millisecond.
|
|||
|
|
currentTimestamp = waitNextMillis(currentTimestamp);
|
|||
|
|
}
|
|||
|
|
} else {
|
|||
|
|
// reset sequence to start with zero for the next millisecond
|
|||
|
|
sequence = 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
lastTimestamp = currentTimestamp;
|
|||
|
|
|
|||
|
|
long id = currentTimestamp << (NODE_ID_BITS + SEQUENCE_BITS)
|
|||
|
|
| (nodeId << SEQUENCE_BITS)
|
|||
|
|
| sequence;
|
|||
|
|
|
|||
|
|
return id;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
// Get current timestamp in milliseconds, adjust for the custom epoch.
|
|||
|
|
private long timestamp() {
|
|||
|
|
return Instant.now().toEpochMilli() - customEpoch;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// 由于这样被耗尽的情况不多,且需要等待的时间也只有1ms;所以我们选择死循环进行阻塞
|
|||
|
|
// Block and wait till next millisecond
|
|||
|
|
private long waitNextMillis(long currentTimestamp) {
|
|||
|
|
while (currentTimestamp == lastTimestamp) {
|
|||
|
|
currentTimestamp = timestamp();
|
|||
|
|
}
|
|||
|
|
return currentTimestamp;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
// 默认基于mac地址生成节点ID
|
|||
|
|
private long createNodeId() {
|
|||
|
|
long nodeId;
|
|||
|
|
try {
|
|||
|
|
StringBuilder sb = new StringBuilder();
|
|||
|
|
Enumeration<NetworkInterface> networkInterfaces = NetworkInterface.getNetworkInterfaces();
|
|||
|
|
while (networkInterfaces.hasMoreElements()) {
|
|||
|
|
NetworkInterface networkInterface = networkInterfaces.nextElement();
|
|||
|
|
byte[] mac = networkInterface.getHardwareAddress();
|
|||
|
|
if (mac != null) {
|
|||
|
|
for(byte macPort: mac) {
|
|||
|
|
sb.append(String.format("%02X", macPort));
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
nodeId = sb.toString().hashCode();
|
|||
|
|
} catch (Exception ex) {
|
|||
|
|
nodeId = (new SecureRandom().nextInt());
|
|||
|
|
}
|
|||
|
|
nodeId = nodeId & maxNodeId;
|
|||
|
|
return nodeId;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public long[] parse(long id) {
|
|||
|
|
long maskNodeId = ((1L << NODE_ID_BITS) - 1) << SEQUENCE_BITS;
|
|||
|
|
long maskSequence = (1L << SEQUENCE_BITS) - 1;
|
|||
|
|
|
|||
|
|
long timestamp = (id >> (NODE_ID_BITS + SEQUENCE_BITS)) + customEpoch;
|
|||
|
|
long nodeId = (id & maskNodeId) >> SEQUENCE_BITS;
|
|||
|
|
long sequence = id & maskSequence;
|
|||
|
|
|
|||
|
|
return new long[]{timestamp, nodeId, sequence};
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@Override
|
|||
|
|
public String toString() {
|
|||
|
|
return "Snowflake Settings [EPOCH_BITS=" + EPOCH_BITS + ", NODE_ID_BITS=" + NODE_ID_BITS
|
|||
|
|
+ ", SEQUENCE_BITS=" + SEQUENCE_BITS + ", CUSTOM_EPOCH=" + customEpoch
|
|||
|
|
+ ", NodeId=" + nodeId + "]";
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
主要思路就是先根据name,初始化Snowflake generator的实例,开发者需要保证name的唯一性;然后在需要生成新的ID的时候,用当前时间戳加上当前时间戳内(也就是某一毫秒内)的计数器,拼接得到UUID,如果某一毫秒内的计数器被耗尽达到上限,会死循环直至这1ms过去。代码很简单,你看懂了吗。
|
|||
|
|
|
|||
|
|
再次说明一下,你千万不用太担心源码艰深复杂而不敢看,其实很多项目的源码还是很简单的,推荐你从这种小而美的代码开始看起,其实你看完之后,往往也会信心倍增,觉得自己也能写出来。等你之后看得多了,自然也能更好地掌握背后的编程技巧啦。
|
|||
|
|
|
|||
|
|
## 总结
|
|||
|
|
|
|||
|
|
主流的几种生成分布式唯一ID的方案我们今天就都学习完了,思路基本上都比较直接,大体分为两种思路:需要引入额外的系统生成ID、在业务侧本地通过规则约束独立生成ID。
|
|||
|
|
|
|||
|
|
单点生成器和基于数据库的实现都是第一种,UUID和Snowflake则都是在本地根据规则约束独立生成ID,一般来说也应用更加广泛。
|
|||
|
|
|
|||
|
|
你可以好好回顾感受学到的几个问题解决思想,备份节点来提高可用性、批量读写来提高系统性能、本地计算来避免性能瓶颈。之后,你自己引入外部数据库或者其他系统的时候,也要多多考虑是否会在引入的系统上发生问题和性能瓶颈。
|
|||
|
|
|
|||
|
|
### 课后作业
|
|||
|
|
|
|||
|
|
今天思考题就是前面说的,如果让你自己不借助外部组件实现一个单点的ID发生器,你会怎么做呢?
|
|||
|
|
|
|||
|
|
欢迎你在评论区留言与我一起讨论,如果觉得本文对你有帮助的话,也欢迎转发给你的朋友一起学习,我们下节课见~
|
|||
|
|
|